 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
MMM: Multi-Layer Multi-Residual Multi-Stream Discrete Speech Representation from Self-supervised Learning Model
Jun 14, 2024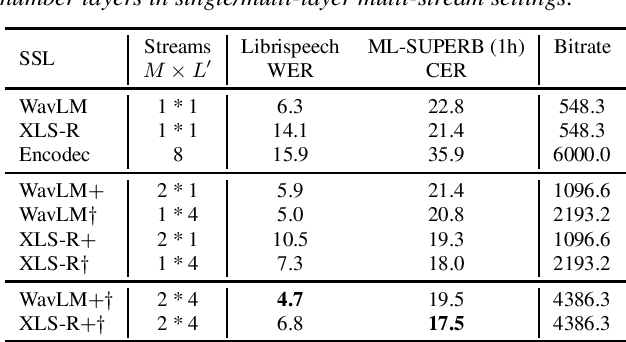
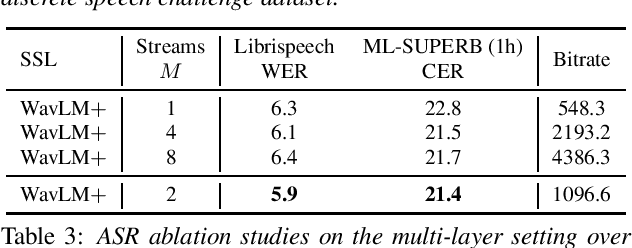
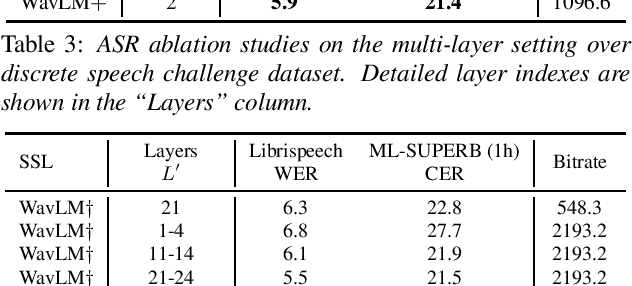
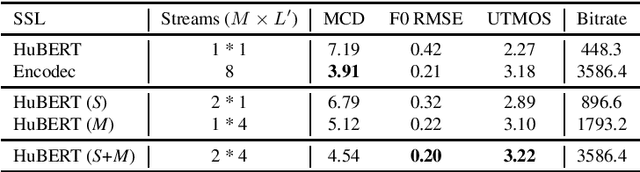
Speech discrete representation has proven effective in various downstream applications due to its superior compression rate of the waveform, fast convergence during training, and compatibility with other modalities. Discrete units extracted from self-supervised learning (SSL) models have emerged as a prominent approach for obtaining speech discrete representation. However, while discrete units have shown effectiveness compared to spectral features, they still lag behind continuous SSL representations. In this work, we propose MMM, a multi-layer multi-residual multi-stream discrete units extraction method from SSL. Specifically, we introduce iterative residual vector quantization with K-means for different layers in an SSL model to extract multi-stream speech discrete representation. Through extensive experiments in speech recognition, speech resynthesis, and text-to-speech, we demonstrate the proposed MMM can surpass or on-par with neural codec's performance under various conditions.
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Jun 06, 2024
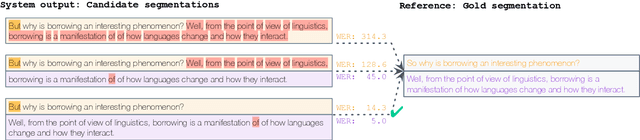

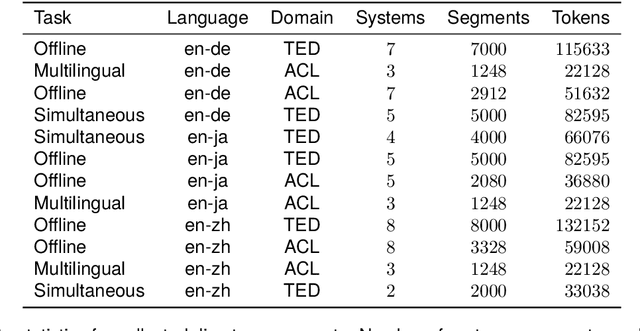
Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
* LREC-COLING2024 publication (with corrections for Table 3)
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
Efficient Monotonic Multihead Attention
Dec 07, 2023
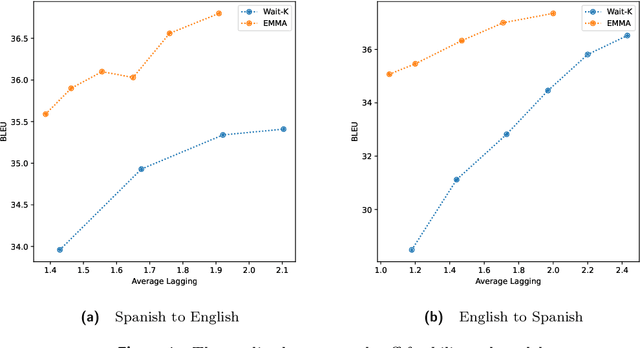
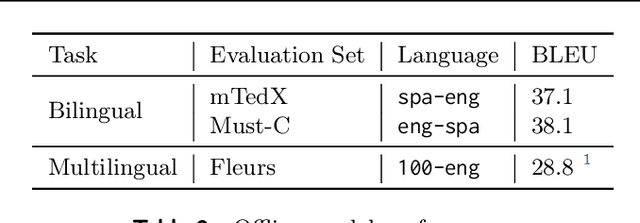
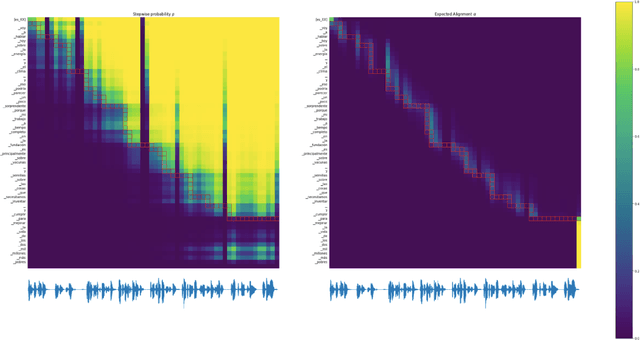
We introduce the Efficient Monotonic Multihead Attention (EMMA), a state-of-the-art simultaneous translation model with numerically-stable and unbiased monotonic alignment estimation. In addition, we present improved training and inference strategies, including simultaneous fine-tuning from an offline translation model and reduction of monotonic alignment variance. The experimental results demonstrate that the proposed model attains state-of-the-art performance in simultaneous speech-to-text translation on the Spanish and English translation task.
Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction
Oct 04, 2023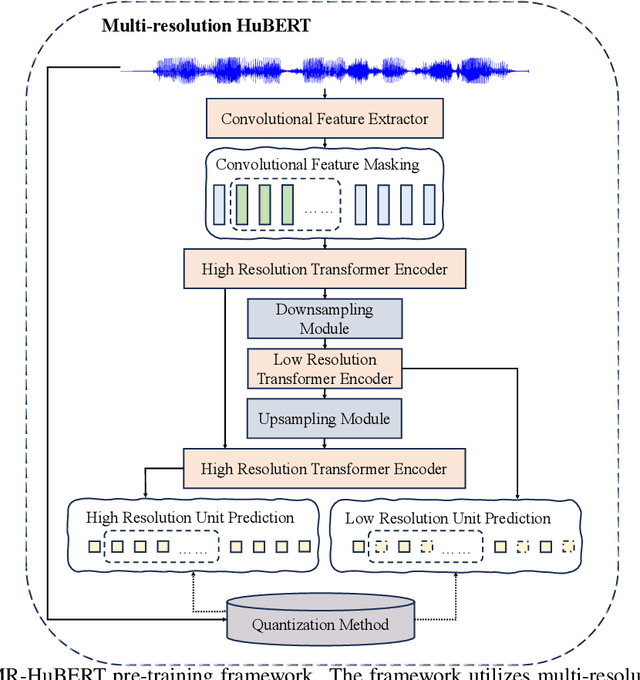
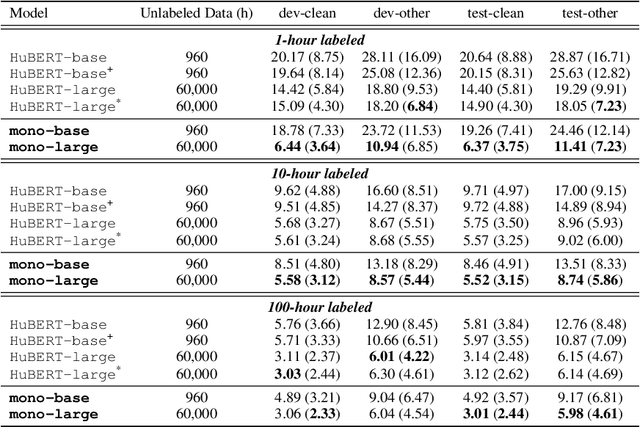
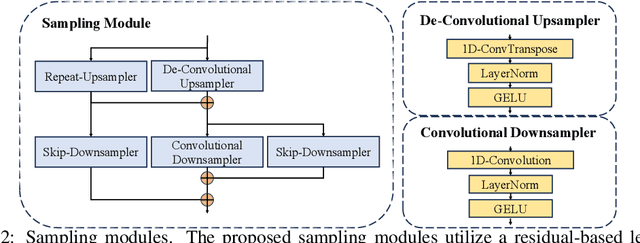
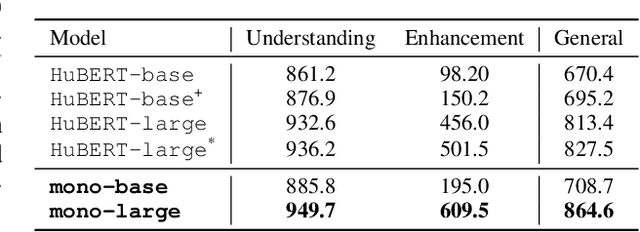
Existing Self-Supervised Learning (SSL) models for speech typically process speech signals at a fixed resolution of 20 milliseconds. This approach overlooks the varying informational content present at different resolutions in speech signals. In contrast, this paper aims to incorporate multi-resolution information into speech self-supervised representation learning. We introduce a SSL model that leverages a hierarchical Transformer architecture, complemented by HuBERT-style masked prediction objectives, to process speech at multiple resolutions. Experimental results indicate that the proposed model not only achieves more efficient inference but also exhibits superior or comparable performance to the original HuBERT model over various tasks. Specifically, significant performance improvements over the original HuBERT have been observed in fine-tuning experiments on the LibriSpeech speech recognition benchmark as well as in evaluations using the Speech Universal PERformance Benchmark (SUPERB) and Multilingual SUPERB (ML-SUPERB).
SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
Hybrid Transducer and Attention based Encoder-Decoder Modeling for Speech-to-Text Tasks
May 04, 2023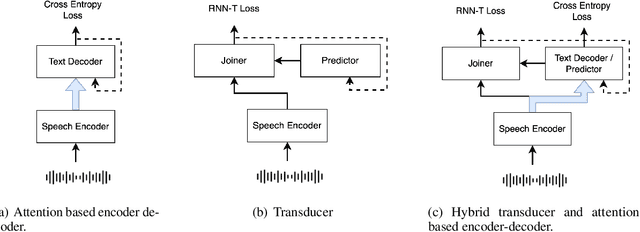
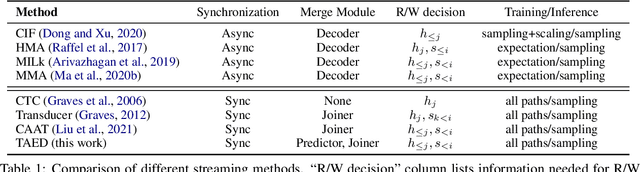


Transducer and Attention based Encoder-Decoder (AED) are two widely used frameworks for speech-to-text tasks. They are designed for different purposes and each has its own benefits and drawbacks for speech-to-text tasks. In order to leverage strengths of both modeling methods, we propose a solution by combining Transducer and Attention based Encoder-Decoder (TAED) for speech-to-text tasks. The new method leverages AED's strength in non-monotonic sequence to sequence learning while retaining Transducer's streaming property. In the proposed framework, Transducer and AED share the same speech encoder. The predictor in Transducer is replaced by the decoder in the AED model, and the outputs of the decoder are conditioned on the speech inputs instead of outputs from an unconditioned language model. The proposed solution ensures that the model is optimized by covering all possible read/write scenarios and creates a matched environment for streaming applications. We evaluate the proposed approach on the \textsc{MuST-C} dataset and the findings demonstrate that TAED performs significantly better than Transducer for offline automatic speech recognition (ASR) and speech-to-text translation (ST) tasks. In the streaming case, TAED outperforms Transducer in the ASR task and one ST direction while comparable results are achieved in another translation direction.
Direct simultaneous speech to speech translation
Oct 15, 2021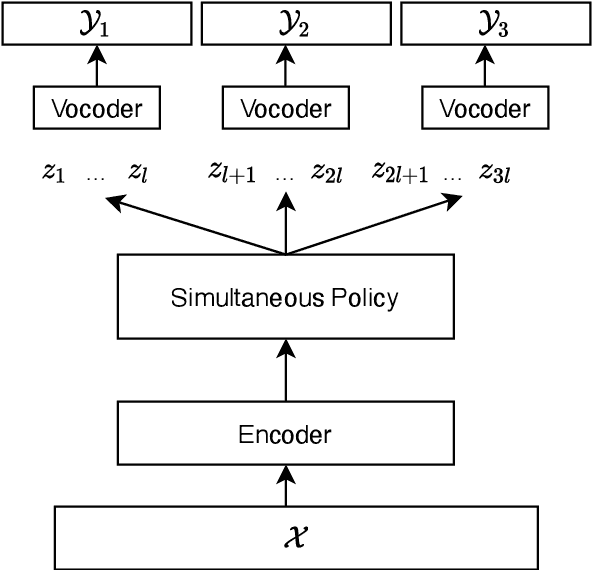
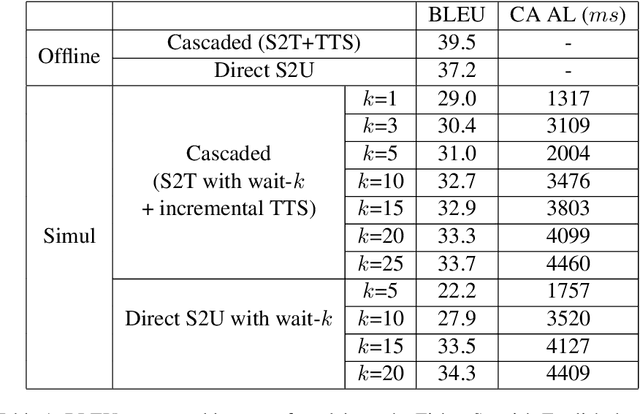
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.