 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Transducer and Attention based Encoder-Decoder Modeling for Speech-to-Text Tasks
Paper and Code
May 04, 2023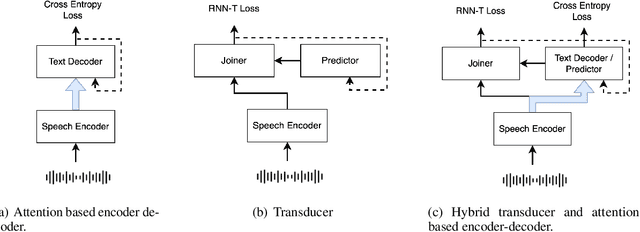
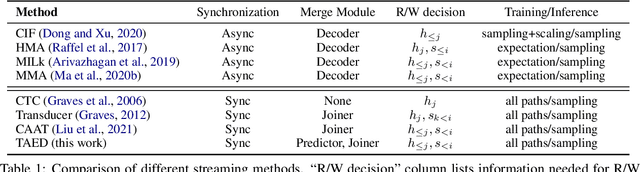


Transducer and Attention based Encoder-Decoder (AED) are two widely used frameworks for speech-to-text tasks. They are designed for different purposes and each has its own benefits and drawbacks for speech-to-text tasks. In order to leverage strengths of both modeling methods, we propose a solution by combining Transducer and Attention based Encoder-Decoder (TAED) for speech-to-text tasks. The new method leverages AED's strength in non-monotonic sequence to sequence learning while retaining Transducer's streaming property. In the proposed framework, Transducer and AED share the same speech encoder. The predictor in Transducer is replaced by the decoder in the AED model, and the outputs of the decoder are conditioned on the speech inputs instead of outputs from an unconditioned language model. The proposed solution ensures that the model is optimized by covering all possible read/write scenarios and creates a matched environment for streaming applications. We evaluate the proposed approach on the \textsc{MuST-C} dataset and the findings demonstrate that TAED performs significantly better than Transducer for offline automatic speech recognition (ASR) and speech-to-text translation (ST) tasks. In the streaming case, TAED outperforms Transducer in the ASR task and one ST direction while comparable results are achieved in another translation direction.