 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect simultaneous speech to speech translation
Oct 15, 2021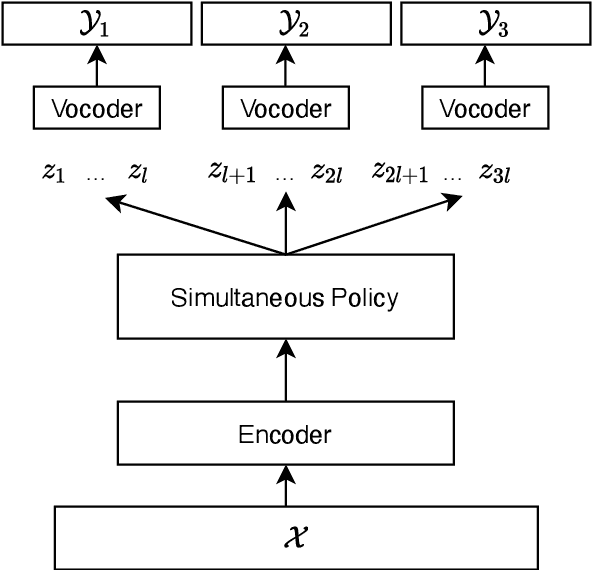
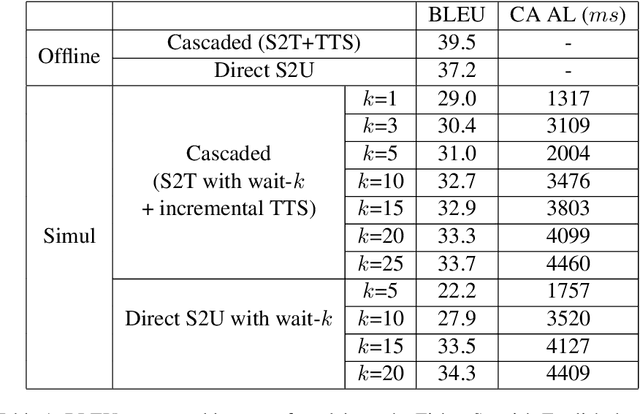
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.