 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Compliance: A Resistance-Informed Motivation Reasoning Framework for Challenging Psychological Client Simulation
Apr 12, 2026Psychological client simulators have emerged as a scalable solution for training and evaluating counselor trainees and psychological LLMs. Yet existing simulators exhibit unrealistic over-compliance, leaving counselors underprepared for the challenging behaviors common in real-world practice. To bridge this gap, we present ResistClient, which systematically models challenging client behaviors grounded in Client Resistance Theory by integrating external behaviors with underlying motivational mechanisms. To this end, we propose Resistance-Informed Motivation Reasoning (RIMR), a two-stage training framework. First, RIMR mitigates compliance bias via supervised fine-tuning on RPC, a large-scale resistance-oriented psychological conversation dataset covering diverse client profiles. Second, beyond surface-level response imitation, RIMR models psychologically coherent motivation reasoning before response generation, jointly optimizing motivation authenticity and response consistency via process-supervised reinforcement learning. Extensive automatic and expert evaluations show that ResistClient substantially outperforms existing simulators in challenge fidelity, behavioral plausibility, and reasoning coherence. Moreover, ResistClient facilities evaluation of psychological LLMs under challenging conditions, offering new optimization directions for mental health dialogue systems.
KIT's Low-resource Speech Translation Systems for IWSLT2025: System Enhancement with Synthetic Data and Model Regularization
May 26, 2025This paper presents KIT's submissions to the IWSLT 2025 low-resource track. We develop both cascaded systems, consisting of Automatic Speech Recognition (ASR) and Machine Translation (MT) models, and end-to-end (E2E) Speech Translation (ST) systems for three language pairs: Bemba, North Levantine Arabic, and Tunisian Arabic into English. Building upon pre-trained models, we fine-tune our systems with different strategies to utilize resources efficiently. This study further explores system enhancement with synthetic data and model regularization. Specifically, we investigate MT-augmented ST by generating translations from ASR data using MT models. For North Levantine, which lacks parallel ST training data, a system trained solely on synthetic data slightly surpasses the cascaded system trained on real data. We also explore augmentation using text-to-speech models by generating synthetic speech from MT data, demonstrating the benefits of synthetic data in improving both ASR and ST performance for Bemba. Additionally, we apply intra-distillation to enhance model performance. Our experiments show that this approach consistently improves results across ASR, MT, and ST tasks, as well as across different pre-trained models. Finally, we apply Minimum Bayes Risk decoding to combine the cascaded and end-to-end systems, achieving an improvement of approximately 1.5 BLEU points.
Embodied Escaping: End-to-End Reinforcement Learning for Robot Navigation in Narrow Environment
Mar 05, 2025



Autonomous navigation is a fundamental task for robot vacuum cleaners in indoor environments. Since their core function is to clean entire areas, robots inevitably encounter dead zones in cluttered and narrow scenarios. Existing planning methods often fail to escape due to complex environmental constraints, high-dimensional search spaces, and high difficulty maneuvers. To address these challenges, this paper proposes an embodied escaping model that leverages reinforcement learning-based policy with an efficient action mask for dead zone escaping. To alleviate the issue of the sparse reward in training, we introduce a hybrid training policy that improves learning efficiency. In handling redundant and ineffective action options, we design a novel action representation to reshape the discrete action space with a uniform turning radius. Furthermore, we develop an action mask strategy to select valid action quickly, balancing precision and efficiency. In real-world experiments, our robot is equipped with a Lidar, IMU, and two-wheel encoders. Extensive quantitative and qualitative experiments across varying difficulty levels demonstrate that our robot can consistently escape from challenging dead zones. Moreover, our approach significantly outperforms compared path planning and reinforcement learning methods in terms of success rate and collision avoidance.
Middle-Layer Representation Alignment for Cross-Lingual Transfer in Fine-Tuned LLMs
Feb 20, 2025While large language models demonstrate remarkable capabilities at task-specific applications through fine-tuning, extending these benefits across diverse languages is essential for broad accessibility. However, effective cross-lingual transfer is hindered by LLM performance gaps across languages and the scarcity of fine-tuning data in many languages. Through analysis of LLM internal representations from over 1,000+ language pairs, we discover that middle layers exhibit the strongest potential for cross-lingual alignment. Building on this finding, we propose a middle-layer alignment objective integrated into task-specific training. Our experiments on slot filling, machine translation, and structured text generation show consistent improvements in cross-lingual transfer, especially to lower-resource languages. The method is robust to the choice of alignment languages and generalizes to languages unseen during alignment. Furthermore, we show that separately trained alignment modules can be merged with existing task-specific modules, improving cross-lingual capabilities without full re-training. Our code is publicly available (https://github.com/dannigt/mid-align).
How do Multimodal Foundation Models Encode Text and Speech? An Analysis of Cross-Lingual and Cross-Modal Representations
Nov 26, 2024Multimodal foundation models aim to create a unified representation space that abstracts away from surface features like language syntax or modality differences. To investigate this, we study the internal representations of three recent models, analyzing the model activations from semantically equivalent sentences across languages in the text and speech modalities. Our findings reveal that: 1) Cross-modal representations converge over model layers, except in the initial layers specialized at text and speech processing. 2) Length adaptation is crucial for reducing the cross-modal gap between text and speech, although current approaches' effectiveness is primarily limited to high-resource languages. 3) Speech exhibits larger cross-lingual differences than text. 4) For models not explicitly trained for modality-agnostic representations, the modality gap is more prominent than the language gap.
Optimizing Rare Word Accuracy in Direct Speech Translation with a Retrieval-and-Demonstration Approach
Sep 13, 2024Direct speech translation (ST) models often struggle with rare words. Incorrect translation of these words can have severe consequences, impacting translation quality and user trust. While rare word translation is inherently challenging for neural models due to sparse learning signals, real-world scenarios often allow access to translations of past recordings on similar topics. To leverage these valuable resources, we propose a retrieval-and-demonstration approach to enhance rare word translation accuracy in direct ST models. First, we adapt existing ST models to incorporate retrieved examples for rare word translation, which allows the model to benefit from prepended examples, similar to in-context learning. We then develop a cross-modal (speech-to-speech, speech-to-text, text-to-text) retriever to locate suitable examples. We demonstrate that standard ST models can be effectively adapted to leverage examples for rare word translation, improving rare word translation accuracy over the baseline by 17.6% with gold examples and 8.5% with retrieved examples. Moreover, our speech-to-speech retrieval approach outperforms other modalities and exhibits higher robustness to unseen speakers. Our code is publicly available (https://github.com/SiqiLii/Retrieve-and-Demonstration-ST).
Speech Editing -- a Summary
Jul 24, 2024



With the rise of video production and social media, speech editing has become crucial for creators to address issues like mispronunciations, missing words, or stuttering in audio recordings. This paper explores text-based speech editing methods that modify audio via text transcripts without manual waveform editing. These approaches ensure edited audio is indistinguishable from the original by altering the mel-spectrogram. Recent advancements, such as context-aware prosody correction and advanced attention mechanisms, have improved speech editing quality. This paper reviews state-of-the-art methods, compares key metrics, and examines widely used datasets. The aim is to highlight ongoing issues and inspire further research and innovation in speech editing.
Blending LLMs into Cascaded Speech Translation: KIT's Offline Speech Translation System for IWSLT 2024
Jun 24, 2024Large Language Models (LLMs) are currently under exploration for various tasks, including Automatic Speech Recognition (ASR), Machine Translation (MT), and even End-to-End Speech Translation (ST). In this paper, we present KIT's offline submission in the constrained + LLM track by incorporating recently proposed techniques that can be added to any cascaded speech translation. Specifically, we integrate Mistral-7B\footnote{mistralai/Mistral-7B-Instruct-v0.1} into our system to enhance it in two ways. Firstly, we refine the ASR outputs by utilizing the N-best lists generated by our system and fine-tuning the LLM to predict the transcript accurately. Secondly, we refine the MT outputs at the document level by fine-tuning the LLM, leveraging both ASR and MT predictions to improve translation quality. We find that integrating the LLM into the ASR and MT systems results in an absolute improvement of $0.3\%$ in Word Error Rate and $0.65\%$ in COMET for tst2019 test set. In challenging test sets with overlapping speakers and background noise, we find that integrating LLM is not beneficial due to poor ASR performance. Here, we use ASR with chunked long-form decoding to improve context usage that may be unavailable when transcribing with Voice Activity Detection segmentation alone.
SciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Jun 14, 2024
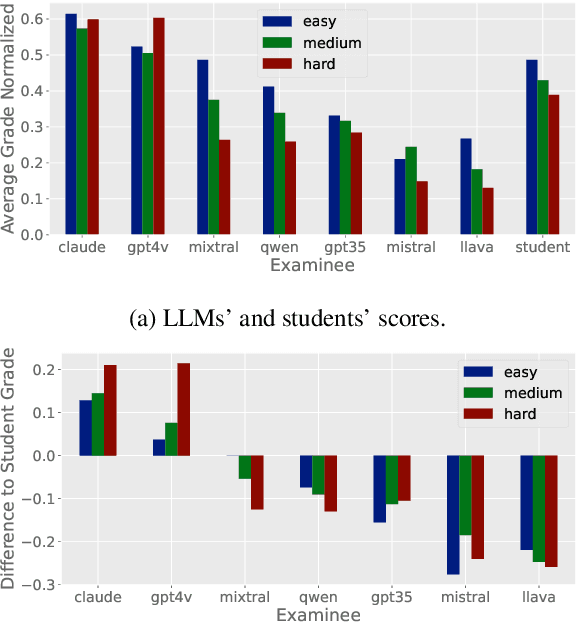

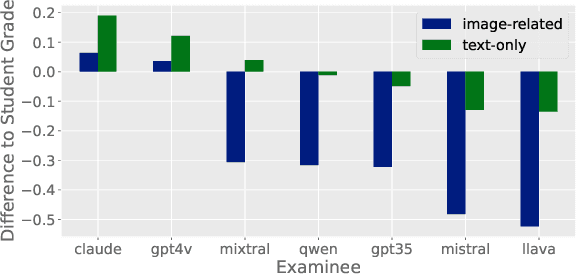
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4\% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.
Language-Independent Representations Improve Zero-Shot Summarization
Apr 08, 2024Finetuning pretrained models on downstream generation tasks often leads to catastrophic forgetting in zero-shot conditions. In this work, we focus on summarization and tackle the problem through the lens of language-independent representations. After training on monolingual summarization, we perform zero-shot transfer to new languages or language pairs. We first show naively finetuned models are highly language-specific in both output behavior and internal representations, resulting in poor zero-shot performance. Next, we propose query-key (QK) finetuning to decouple task-specific knowledge from the pretrained language generation abilities. Then, after showing downsides of the standard adversarial language classifier, we propose a balanced variant that more directly enforces language-agnostic representations. Moreover, our qualitative analyses show removing source language identity correlates to zero-shot summarization performance. Our code is openly available.