 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERRIN: A Benchmark for Multimodal Evidence Retrieval and Reasoning in Noisy Web Environments
Apr 15, 2026Motivated by the underspecified, multi-hop nature of search queries and the multimodal, heterogeneous, and often conflicting nature of real-world web results, we introduce MERRIN (Multimodal Evidence Retrieval and Reasoning in Noisy Web Environments), a human-annotated benchmark for evaluating search-augmented agents. MERRIN measures AI agents' ability to identify relevant modalities, retrieve multimodal evidence, and perform multi-hop reasoning over noisy web sources. It differs from prior work in three important aspects: (1) using natural language queries without explicit modality cues, (2) incorporating underexplored modalities such as video and audio, and (3) requiring the retrieval of complex, often noisy or conflicting multimodal evidence during web search. We evaluate diverse search agents powered by ten models, including strong closed-source models (e.g., GPT-5.4-mini, Gemini 3/3.1 Flash/Pro) and open-weight models (Qwen3-4B/30B/235B), across three search settings (no search, native search, and agentic search). Our results show that MERRIN is highly challenging: the average accuracy across all agents is 22.3%, with the best-performing agent reaching only 40.1%. We further observe that while stronger agents like Gemini Deep Research achieve higher performance, gains are modest due to over-exploration; they take more steps and use more tools, but are often distracted by conflicting or partially relevant web content, leading to incorrect answers. Compared to humans, these agents consume more resources yet achieve lower accuracy, largely due to inefficient source selection and an overreliance on text modalities. These findings highlight the need for search agents capable of robust search and reasoning across diverse modalities in noisy web environments, making MERRIN a valuable testbed for evaluating such capabilities.
Playing Along: Learning a Double-Agent Defender for Belief Steering via Theory of Mind
Apr 13, 2026As large language models (LLMs) become the engine behind conversational systems, their ability to reason about the intentions and states of their dialogue partners (i.e., form and use a theory-of-mind, or ToM) becomes increasingly critical for safe interaction with potentially adversarial partners. We propose a novel privacy-themed ToM challenge, ToM for Steering Beliefs (ToM-SB), in which a defender must act as a Double Agent to steer the beliefs of an attacker with partial prior knowledge within a shared universe. To succeed on ToM-SB, the defender must engage with and form a ToM of the attacker, with a goal of fooling the attacker into believing they have succeeded in extracting sensitive information. We find that strong frontier models like Gemini3-Pro and GPT-5.4 struggle on ToM-SB, often failing to fool attackers in hard scenarios with partial attacker prior knowledge, even when prompted to reason about the attacker's beliefs (ToM prompting). To close this gap, we train models on ToM-SB to act as AI Double Agents using reinforcement learning, testing both fooling and ToM rewards. Notably, we find a bidirectionally emergent relationship between ToM and attacker-fooling: rewarding fooling success alone improves ToM, and rewarding ToM alone improves fooling. Across four attackers with different strengths, six defender methods, and both in-distribution and out-of-distribution (OOD) evaluation, we find that gains in ToM and attacker-fooling are well-correlated, highlighting belief modeling as a key driver of success on ToM-SB. AI Double Agents that combine both ToM and fooling rewards yield the strongest fooling and ToM performance, outperforming Gemini3-Pro and GPT-5.4 with ToM prompting on hard scenarios. We also show that ToM-SB and AI Double Agents can be extended to stronger attackers, demonstrating generalization to OOD settings and the upgradability of our task.
Balancing Faithfulness and Performance in Reasoning via Multi-Listener Soft Execution
Feb 18, 2026Chain-of-thought (CoT) reasoning sometimes fails to faithfully reflect the true computation of a large language model (LLM), hampering its utility in explaining how LLMs arrive at their answers. Moreover, optimizing for faithfulness and interpretability in reasoning often degrades task performance. To address this tradeoff and improve CoT faithfulness, we propose Reasoning Execution by Multiple Listeners (REMUL), a multi-party reinforcement learning approach. REMUL builds on the hypothesis that reasoning traces which other parties can follow will be more faithful. A speaker model generates a reasoning trace, which is truncated and passed to a pool of listener models who "execute" the trace, continuing the trace to an answer. Speakers are rewarded for producing reasoning that is clear to listeners, with additional correctness regularization via masked supervised finetuning to counter the tradeoff between faithfulness and performance. On multiple reasoning benchmarks (BIG-Bench Extra Hard, MuSR, ZebraLogicBench, and FOLIO), REMUL consistently and substantially improves three measures of faithfulness -- hint attribution, early answering area over the curve (AOC), and mistake injection AOC -- while also improving accuracy. Our analysis finds that these gains are robust across training domains, translate to legibility gains, and are associated with shorter and more direct CoTs.
Multimodal Fact-Level Attribution for Verifiable Reasoning
Feb 12, 2026Multimodal large language models (MLLMs) are increasingly used for real-world tasks involving multi-step reasoning and long-form generation, where reliability requires grounding model outputs in heterogeneous input sources and verifying individual factual claims. However, existing multimodal grounding benchmarks and evaluation methods focus on simplified, observation-based scenarios or limited modalities and fail to assess attribution in complex multimodal reasoning. We introduce MuRGAt (Multimodal Reasoning with Grounded Attribution), a benchmark for evaluating fact-level multimodal attribution in settings that require reasoning beyond direct observation. Given inputs spanning video, audio, and other modalities, MuRGAt requires models to generate answers with explicit reasoning and precise citations, where each citation specifies both modality and temporal segments. To enable reliable assessment, we introduce an automatic evaluation framework that strongly correlates with human judgments. Benchmarking with human and automated scores reveals that even strong MLLMs frequently hallucinate citations despite correct reasoning. Moreover, we observe a key trade-off: increasing reasoning depth or enforcing structured grounding often degrades accuracy, highlighting a significant gap between internal reasoning and verifiable attribution.
Conflict-Resolving and Sharpness-Aware Minimization for Generalized Knowledge Editing with Multiple Updates
Feb 03, 2026Large language models (LLMs) rely on internal knowledge to solve many downstream tasks, making it crucial to keep them up to date. Since full retraining is expensive, prior work has explored efficient alternatives such as model editing and parameter-efficient fine-tuning. However, these approaches often break down in practice due to poor generalization across inputs, limited stability, and knowledge conflict. To address these limitations, we propose the CoRSA (Conflict-Resolving and Sharpness-Aware Minimization) training framework, a parameter-efficient, holistic approach for knowledge editing with multiple updates. CoRSA tackles multiple challenges simultaneously: it improves generalization to different input forms and enhances stability across multiple updates by minimizing loss curvature, and resolves conflicts by maximizing the margin between new and prior knowledge. Across three widely used fact editing benchmarks, CoRSA achieves significant gains in generalization, outperforming baselines with average absolute improvements of 12.42% over LoRA and 10% over model editing methods. With multiple updates, it maintains high update efficacy while reducing catastrophic forgetting by 27.82% compared to LoRA. CoRSA also generalizes to the code domain, outperforming the strongest baseline by 5.48% Pass@5 in update efficacy.
Understanding and Enhancing Mamba-Transformer Hybrids for Memory Recall and Language Modeling
Oct 30, 2025Hybrid models that combine state space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. However, the architectural design choices behind these hybrid models remain insufficiently understood. In this work, we analyze hybrid architectures through the lens of memory utilization and overall performance, and propose a complementary method to further enhance their effectiveness. We first examine the distinction between sequential and parallel integration of SSM and attention layers. Our analysis reveals several interesting findings, including that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts. We also introduce a data-centric approach of continually training on datasets augmented with paraphrases, which further enhances recall while preserving other capabilities. It generalizes well across different base models and outperforms architectural modifications aimed at enhancing recall. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases.
Gistify! Codebase-Level Understanding via Runtime Execution
Oct 30, 2025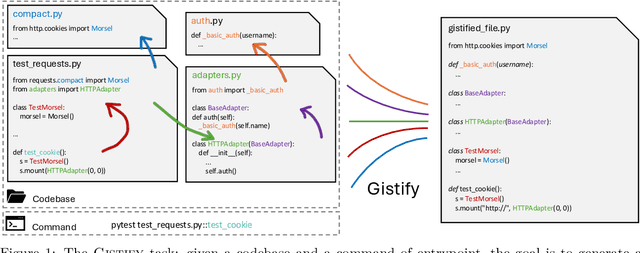
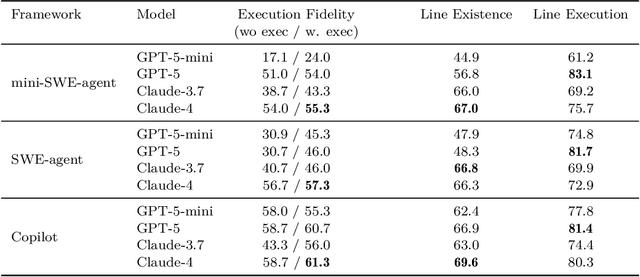

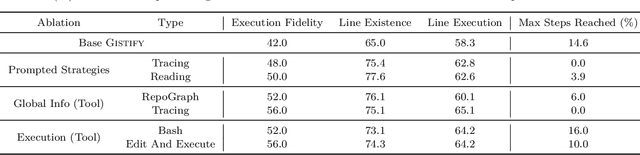
As coding agents are increasingly deployed in large codebases, the need to automatically design challenging, codebase-level evaluation is central. We propose Gistify, a task where a coding LLM must create a single, minimal, self-contained file that can reproduce a specific functionality of a codebase. The coding LLM is given full access to a codebase along with a specific entrypoint (e.g., a python command), and the generated file must replicate the output of the same command ran under the full codebase, while containing only the essential components necessary to execute the provided command. Success on Gistify requires both structural understanding of the codebase, accurate modeling of its execution flow as well as the ability to produce potentially large code patches. Our findings show that current state-of-the-art models struggle to reliably solve Gistify tasks, especially ones with long executions traces.
Context-Informed Grounding Supervision
Jun 18, 2025Large language models (LLMs) are often supplemented with external knowledge to provide information not encoded in their parameters or to reduce hallucination. In such cases, we expect the model to generate responses by grounding its response in the provided external context. However, prior work has shown that simply appending context at inference time does not ensure grounded generation. To address this, we propose Context-INformed Grounding Supervision (CINGS), a post-training supervision in which the model is trained with relevant context prepended to the response, while computing the loss only over the response tokens and masking out the context. Our experiments demonstrate that models trained with CINGS exhibit stronger grounding in both textual and visual domains compared to standard instruction-tuned models. In the text domain, CINGS outperforms other training methods across 11 information-seeking datasets and is complementary to inference-time grounding techniques. In the vision-language domain, replacing a vision-language model's LLM backbone with a CINGS-trained model reduces hallucinations across four benchmarks and maintains factual consistency throughout the generated response. This improved grounding comes without degradation in general downstream performance. Finally, we analyze the mechanism underlying the enhanced grounding in CINGS and find that it induces a shift in the model's prior knowledge and behavior, implicitly encouraging greater reliance on the external context.
Differential Information: An Information-Theoretic Perspective on Preference Optimization
May 29, 2025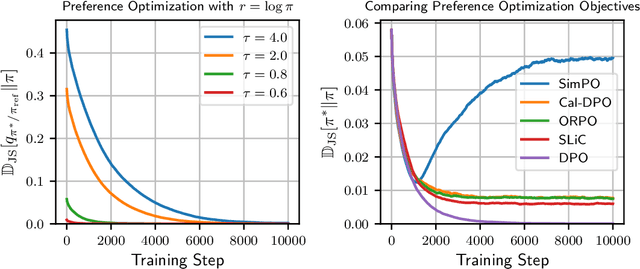
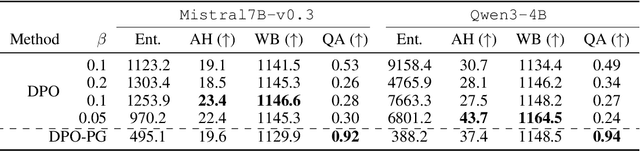
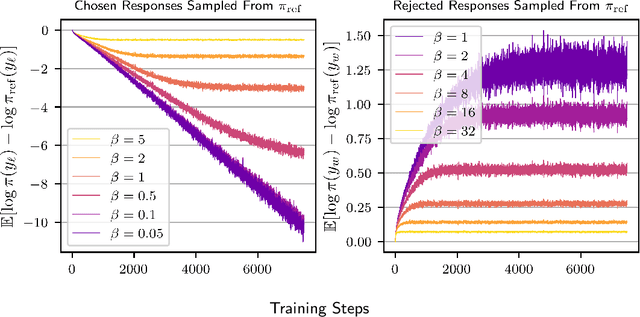

Direct Preference Optimization (DPO) has become a standard technique for aligning language models with human preferences in a supervised manner. Despite its empirical success, the theoretical justification behind its log-ratio reward parameterization remains incomplete. In this work, we address this gap by utilizing the Differential Information Distribution (DID): a distribution over token sequences that captures the information gained during policy updates. First, we show that when preference labels encode the differential information required to transform a reference policy into a target policy, the log-ratio reward in DPO emerges as the uniquely optimal form for learning the target policy via preference optimization. This result naturally yields a closed-form expression for the optimal sampling distribution over rejected responses. Second, we find that the condition for preferences to encode differential information is fundamentally linked to an implicit assumption regarding log-margin ordered policies-an inductive bias widely used in preference optimization yet previously unrecognized. Finally, by analyzing the entropy of the DID, we characterize how learning low-entropy differential information reinforces the policy distribution, while high-entropy differential information induces a smoothing effect, which explains the log-likelihood displacement phenomenon. We validate our theoretical findings in synthetic experiments and extend them to real-world instruction-following datasets. Our results suggest that learning high-entropy differential information is crucial for general instruction-following, while learning low-entropy differential information benefits knowledge-intensive question answering. Overall, our work presents a unifying perspective on the DPO objective, the structure of preference data, and resulting policy behaviors through the lens of differential information.
CORG: Generating Answers from Complex, Interrelated Contexts
Apr 25, 2025In a real-world corpus, knowledge frequently recurs across documents but often contains inconsistencies due to ambiguous naming, outdated information, or errors, leading to complex interrelationships between contexts. Previous research has shown that language models struggle with these complexities, typically focusing on single factors in isolation. We classify these relationships into four types: distracting, ambiguous, counterfactual, and duplicated. Our analysis reveals that no single approach effectively addresses all these interrelationships simultaneously. Therefore, we introduce Context Organizer (CORG), a framework that organizes multiple contexts into independently processed groups. This design allows the model to efficiently find all relevant answers while ensuring disambiguation. CORG consists of three key components: a graph constructor, a reranker, and an aggregator. Our results demonstrate that CORG balances performance and efficiency effectively, outperforming existing grouping methods and achieving comparable results to more computationally intensive, single-context approaches.