 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenAI: Deterministic Inference, Verifiable Results
Jan 30, 2026EigenAI is a verifiable AI platform built on top of the EigenLayer restaking ecosystem. At a high level, it combines a deterministic large-language model (LLM) inference engine with a cryptoeconomically secured optimistic re-execution protocol so that every inference result can be publicly audited, reproduced, and, if necessary, economically enforced. An untrusted operator runs inference on a fixed GPU architecture, signs and encrypts the request and response, and publishes the encrypted log to EigenDA. During a challenge window, any watcher may request re-execution through EigenVerify; the result is then deterministically recomputed inside a trusted execution environment (TEE) with a threshold-released decryption key, allowing a public challenge with private data. Because inference itself is bit-exact, verification reduces to a byte-equality check, and a single honest replica suffices to detect fraud. We show how this architecture yields sovereign agents -- prediction-market judges, trading bots, and scientific assistants -- that enjoy state-of-the-art performance while inheriting security from Ethereum's validator base.
Learning to Extract Context for Context-Aware LLM Inference
Dec 12, 2025User prompts to large language models (LLMs) are often ambiguous or under-specified, and subtle contextual cues shaped by user intentions, prior knowledge, and risk factors strongly influence what constitutes an appropriate response. Misinterpreting intent or risks may lead to unsafe outputs, while overly cautious interpretations can cause unnecessary refusal of benign requests. In this paper, we question the conventional framework in which LLMs generate immediate responses to requests without considering broader contextual factors. User requests are situated within broader contexts such as intentions, knowledge, and prior experience, which strongly influence what constitutes an appropriate answer. We propose a framework that extracts and leverages such contextual information from the user prompt itself. Specifically, a reinforcement learning based context generator, designed in an autoencoder-like fashion, is trained to infer contextual signals grounded in the prompt and use them to guide response generation. This approach is particularly important for safety tasks, where ambiguous requests may bypass safeguards while benign but confusing requests can trigger unnecessary refusals. Experiments show that our method reduces harmful responses by an average of 5.6% on the SafetyInstruct dataset across multiple foundation models and improves the harmonic mean of attack success rate and compliance on benign prompts by 6.2% on XSTest and WildJailbreak. These results demonstrate the effectiveness of context extraction for safer and more reliable LLM inferences.
Gistify! Codebase-Level Understanding via Runtime Execution
Oct 30, 2025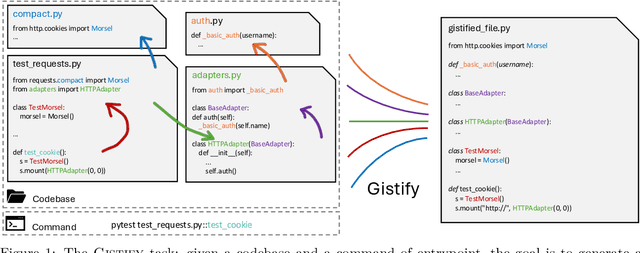
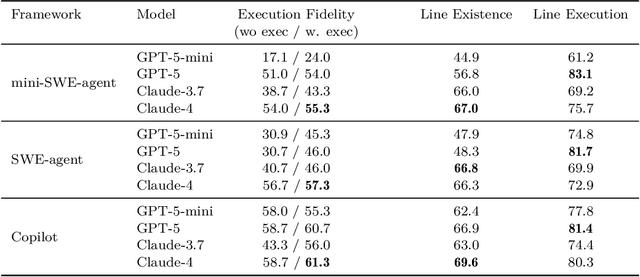

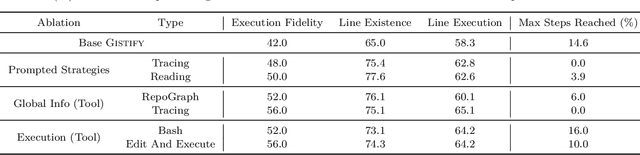
As coding agents are increasingly deployed in large codebases, the need to automatically design challenging, codebase-level evaluation is central. We propose Gistify, a task where a coding LLM must create a single, minimal, self-contained file that can reproduce a specific functionality of a codebase. The coding LLM is given full access to a codebase along with a specific entrypoint (e.g., a python command), and the generated file must replicate the output of the same command ran under the full codebase, while containing only the essential components necessary to execute the provided command. Success on Gistify requires both structural understanding of the codebase, accurate modeling of its execution flow as well as the ability to produce potentially large code patches. Our findings show that current state-of-the-art models struggle to reliably solve Gistify tasks, especially ones with long executions traces.
debug-gym: A Text-Based Environment for Interactive Debugging
Mar 27, 2025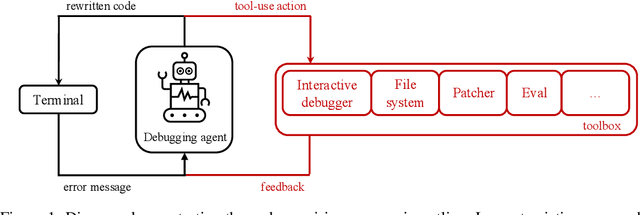
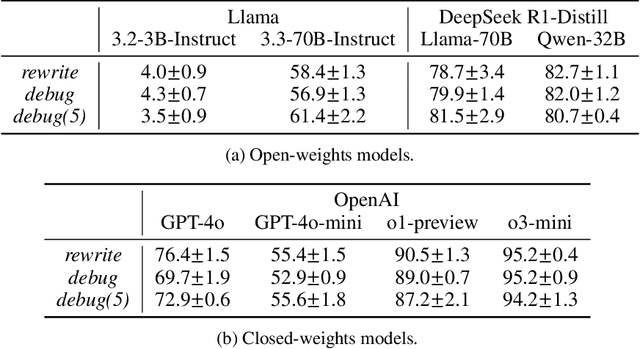
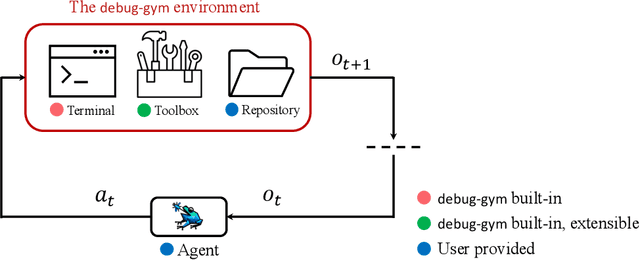
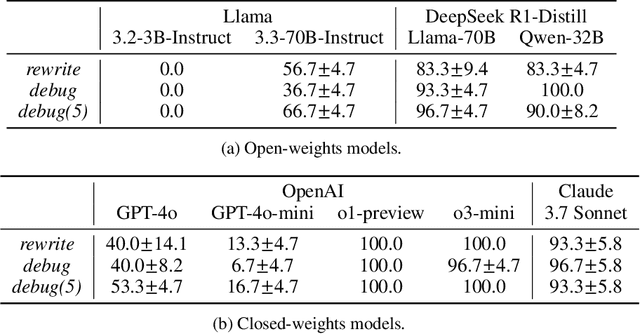
Large Language Models (LLMs) are increasingly relied upon for coding tasks, yet in most scenarios it is assumed that all relevant information can be either accessed in context or matches their training data. We posit that LLMs can benefit from the ability to interactively explore a codebase to gather the information relevant to their task. To achieve this, we present a textual environment, namely debug-gym, for developing LLM-based agents in an interactive coding setting. Our environment is lightweight and provides a preset of useful tools, such as a Python debugger (pdb), designed to facilitate an LLM-based agent's interactive debugging. Beyond coding and debugging tasks, this approach can be generalized to other tasks that would benefit from information-seeking behavior by an LLM agent.
Towards Modular LLMs by Building and Reusing a Library of LoRAs
May 18, 2024The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
Deep Language Networks: Joint Prompt Training of Stacked LLMs using Variational Inference
Jun 21, 2023



We view large language models (LLMs) as stochastic \emph{language layers} in a network, where the learnable parameters are the natural language \emph{prompts} at each layer. We stack two such layers, feeding the output of one layer to the next. We call the stacked architecture a \emph{Deep Language Network} (DLN). We first show how to effectively perform prompt optimization for a 1-Layer language network (DLN-1). We then show how to train 2-layer DLNs (DLN-2), where two prompts must be learnt. We consider the output of the first layer as a latent variable to marginalize, and devise a variational inference algorithm for joint prompt training. A DLN-2 reaches higher performance than a single layer, sometimes comparable to few-shot GPT-4 even when each LLM in the network is smaller and less powerful. The DLN code is open source: https://github.com/microsoft/deep-language-networks .
Multi-Head Adapter Routing for Data-Efficient Fine-Tuning
Nov 07, 2022Parameter-efficient fine-tuning (PEFT) methods can adapt large language models to downstream tasks by training a small amount of newly added parameters. In multi-task settings, PEFT adapters typically train on each task independently, inhibiting transfer across tasks, or on the concatenation of all tasks, which can lead to negative interference. To address this, Polytropon (Ponti et al.) jointly learns an inventory of PEFT adapters and a routing function to share variable-size sets of adapters across tasks. Subsequently, adapters can be re-combined and fine-tuned on novel tasks even with limited data. In this paper, we investigate to what extent the ability to control which adapters are active for each task leads to sample-efficient generalization. Thus, we propose less expressive variants where we perform weighted averaging of the adapters before few-shot adaptation (Poly-mu) instead of learning a routing function. Moreover, we introduce more expressive variants where finer-grained task-adapter allocation is learned through a multi-head routing function (Poly-S). We test these variants on three separate benchmarks for multi-task learning. We find that Poly-S achieves gains on all three (up to 5.3 points on average) over strong baselines, while incurring a negligible additional cost in parameter count. In particular, we find that instruction tuning, where models are fully fine-tuned on natural language instructions for each task, is inferior to modular methods such as Polytropon and our proposed variants.