 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTOP: Structured On-Policy Pruning of Long-Form Reasoning in Low-Data Regimes
May 13, 2026Long chain-of-thought (Long CoT) reasoning improves performance on multi-step problems, but it also induces overthinking: models often generate low-yield reasoning that increases inference cost and latency. This inefficiency is especially problematic in low-data fine-tuning regimes, where real applications adapt reasoning models with limited supervision and cannot rely on large-scale teacher distillation or heavy test-time control. To address this, we propose STOP (Structured On-policy Pruning), an on-policy algorithm for analyzing and pruning long-form reasoning traces. STOP constructs self-distilled traces from the model. Then it maps each trace into a structured reasoning interface through node segmentation, taxonomy annotation, and reasoning-tree construction. On top of this interface, we introduce ECN (Earliest Correct Node), which retains the shortest prefix ending at the earliest node that both functions as an answering conclusion and yields the correct final answer, removing redundant post-solution reasoning while preserving semantic continuity. Experiments on DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-LLaMA-3-8B across GSM8K, Math 500, and AIME 2024 show that STOP reduces generated tokens by 19.4-42.4% while largely preserving accuracy in low-data fine-tuning. Beyond efficiency, our analyses show that STOP induces much smaller distributional shift than teacher-guided pruning, improves the structural efficiency of generated reasoning, and reallocates reasoning effort away from redundant verification and backtracking toward more productive exploration.
RoboClaw: An Agentic Framework for Scalable Long-Horizon Robotic Tasks
Mar 12, 2026Vision-Language-Action (VLA) systems have shown strong potential for language-driven robotic manipulation. However, scaling them to long-horizon tasks remains challenging. Existing pipelines typically separate data collection, policy learning, and deployment, resulting in heavy reliance on manual environment resets and brittle multi-policy execution. We present RoboClaw, an agentic robotics framework that unifies data collection, policy learning, and task execution under a single VLM-driven controller. At the policy level, RoboClaw introduces Entangled Action Pairs (EAP), which couple forward manipulation behaviors with inverse recovery actions to form self-resetting loops for autonomous data collection. This mechanism enables continuous on-policy data acquisition and iterative policy refinement with minimal human intervention. During deployment, the same agent performs high-level reasoning and dynamically orchestrates learned policy primitives to accomplish long-horizon tasks. By maintaining consistent contextual semantics across collection and execution, RoboClaw reduces mismatch between the two phases and improves multi-policy robustness. Experiments in real-world manipulation tasks demonstrate improved stability and scalability compared to conventional open-loop pipelines, while significantly reducing human effort throughout the robot lifecycle, achieving a 25% improvement in success rate over baseline methods on long-horizon tasks and reducing human time investment by 53.7%.
Towards Dynamic Dense Retrieval with Routing Strategy
Feb 26, 2026The \textit{de facto} paradigm for applying dense retrieval (DR) to new tasks involves fine-tuning a pre-trained model for a specific task. However, this paradigm has two significant limitations: (1) It is difficult adapt the DR to a new domain if the training dataset is limited. (2) Old DR models are simply replaced by newer models that are trained from scratch when the former are no longer up to date. Especially for scenarios where the model needs to be updated frequently, this paradigm is prohibitively expensive. To address these challenges, we propose a novel dense retrieval approach, termed \textit{dynamic dense retrieval} (DDR). DDR uses \textit{prefix tuning} as a \textit{module} specialized for a specific domain. These modules can then be compositional combined with a dynamic routing strategy, enabling highly flexible domain adaptation in the retrieval part. Extensive evaluation on six zero-shot downstream tasks demonstrates that this approach can surpass DR while utilizing only 2\% of the training parameters, paving the way to achieve more flexible dense retrieval in IR. We see it as a promising future direction for applying dense retrieval to various tasks.
OpenDecoder: Open Large Language Model Decoding to Incorporate Document Quality in RAG
Jan 13, 2026The development of large language models (LLMs) has achieved superior performance in a range of downstream tasks, including LLM-based retrieval-augmented generation (RAG). The quality of generated content heavily relies on the usefulness of the retrieved information and the capacity of LLMs' internal information processing mechanism to incorporate it in answer generation. It is generally assumed that the retrieved information is relevant to the question. However, the retrieved information may have a variable degree of relevance and usefulness, depending on the question and the document collection. It is important to take into account the relevance of the retrieved information in answer generation. In this paper, we propose OpenDecoder, a new approach that leverages explicit evaluation of the retrieved information as quality indicator features for generation. We aim to build a RAG model that is more robust to varying levels of noisy context. Three types of explicit evaluation information are considered: relevance score, ranking score, and QPP (query performance prediction) score. The experimental results on five benchmark datasets demonstrate the effectiveness and better robustness of OpenDecoder by outperforming various baseline methods. Importantly, this paradigm is flexible to be integrated with the post-training of LLMs for any purposes and incorporated with any type of external indicators.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025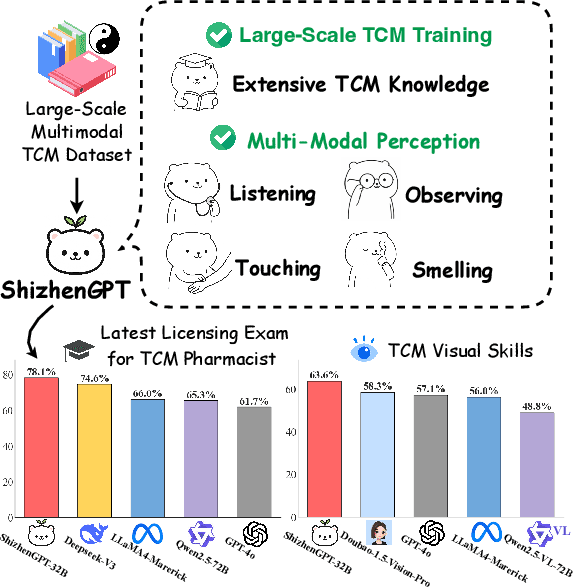
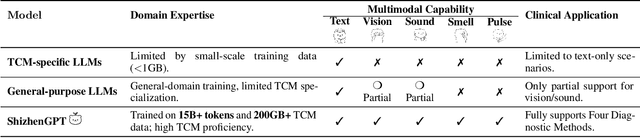
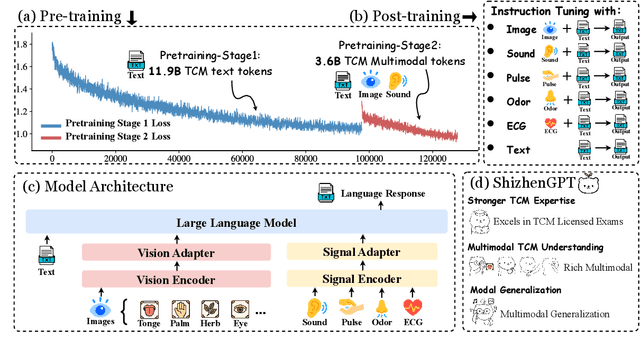
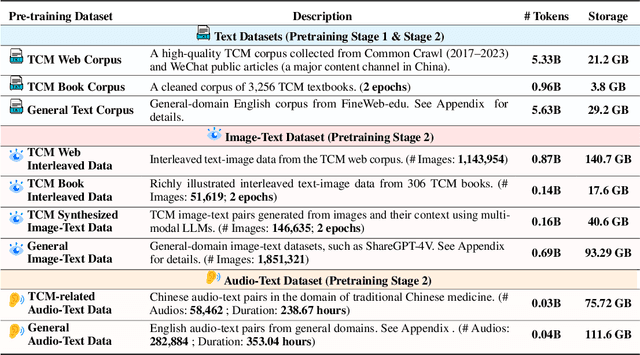
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
Adaptive Personalized Conversational Information Retrieval
Aug 12, 2025Personalized conversational information retrieval (CIR) systems aim to satisfy users' complex information needs through multi-turn interactions by considering user profiles. However, not all search queries require personalization. The challenge lies in appropriately incorporating personalization elements into search when needed. Most existing studies implicitly incorporate users' personal information and conversational context using large language models without distinguishing the specific requirements for each query turn. Such a ``one-size-fits-all'' personalization strategy might lead to sub-optimal results. In this paper, we propose an adaptive personalization method, in which we first identify the required personalization level for a query and integrate personalized queries with other query reformulations to produce various enhanced queries. Then, we design a personalization-aware ranking fusion approach to assign fusion weights dynamically to different reformulated queries, depending on the required personalization level. The proposed adaptive personalized conversational information retrieval framework APCIR is evaluated on two TREC iKAT datasets. The results confirm the effectiveness of adaptive personalization of APCIR by outperforming state-of-the-art methods.
ConvMix: A Mixed-Criteria Data Augmentation Framework for Conversational Dense Retrieval
Aug 06, 2025Conversational search aims to satisfy users' complex information needs via multiple-turn interactions. The key challenge lies in revealing real users' search intent from the context-dependent queries. Previous studies achieve conversational search by fine-tuning a conversational dense retriever with relevance judgments between pairs of context-dependent queries and documents. However, this training paradigm encounters data scarcity issues. To this end, we propose ConvMix, a mixed-criteria framework to augment conversational dense retrieval, which covers more aspects than existing data augmentation frameworks. We design a two-sided relevance judgment augmentation schema in a scalable manner via the aid of large language models. Besides, we integrate the framework with quality control mechanisms to obtain semantically diverse samples and near-distribution supervisions to combine various annotated data. Experimental results on five widely used benchmarks show that the conversational dense retriever trained by our ConvMix framework outperforms previous baseline methods, which demonstrates our superior effectiveness.
Tensorized Clustered LoRA Merging for Multi-Task Interference
Aug 06, 2025Despite the success of the monolithic dense paradigm of large language models (LLMs), the LoRA adapters offer an efficient solution by fine-tuning small task-specific modules and merging them with the base model. However, in multi-task settings, merging LoRA adapters trained on heterogeneous sources frequently causes \textit{task interference}, degrading downstream performance. To address this, we propose a tensorized clustered LoRA (TC-LoRA) library targeting to address the task interference at the \textit{text-level} and \textit{parameter-level}. At the \textit{text-level}, we cluster the training samples in the embedding space to capture input-format similarities, then train a specialized LoRA adapter for each cluster. At the \textit{parameter-level}, we introduce a joint Canonical Polyadic (CP) decomposition that disentangles task-specific and shared factors across LoRA adapters. This joint factorization preserves essential knowledge while reducing cross-task interference. Extensive experiments on out-of-domain zero-shot and skill-composition tasks-including reasoning, question answering, and coding. Compared to strong SVD-based baselines, TC-LoRA achieves +1.4\% accuracy on Phi-3 and +2.3\% on Mistral-7B (+2.3\%), demonstrating the effectiveness of TC-LoRA in LLM adaptation.
Aligning Query Representation with Rewritten Query and Relevance Judgments in Conversational Search
Jul 29, 2024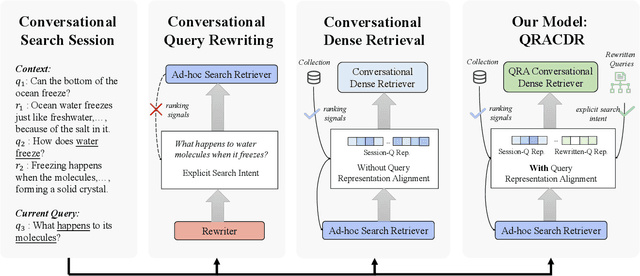
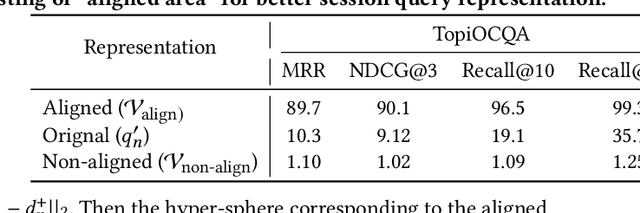
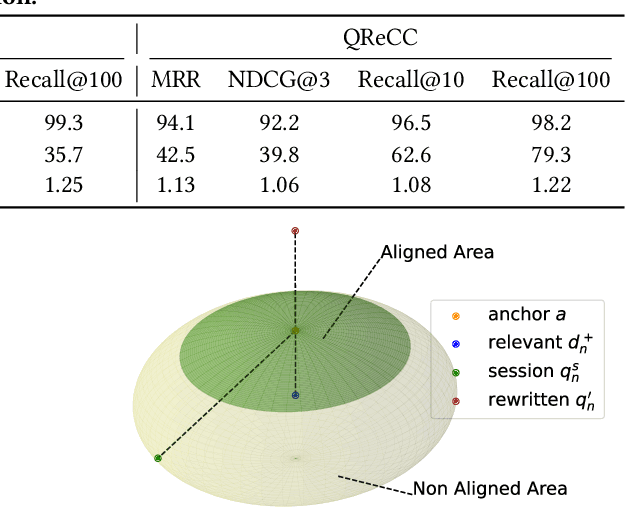

Conversational search supports multi-turn user-system interactions to solve complex information needs. Different from the traditional single-turn ad-hoc search, conversational search encounters a more challenging problem of context-dependent query understanding with the lengthy and long-tail conversational history context. While conversational query rewriting methods leverage explicit rewritten queries to train a rewriting model to transform the context-dependent query into a stand-stone search query, this is usually done without considering the quality of search results. Conversational dense retrieval methods use fine-tuning to improve a pre-trained ad-hoc query encoder, but they are limited by the conversational search data available for training. In this paper, we leverage both rewritten queries and relevance judgments in the conversational search data to train a better query representation model. The key idea is to align the query representation with those of rewritten queries and relevant documents. The proposed model -- Query Representation Alignment Conversational Dense Retriever, QRACDR, is tested on eight datasets, including various settings in conversational search and ad-hoc search. The results demonstrate the strong performance of QRACDR compared with state-of-the-art methods, and confirm the effectiveness of representation alignment.
Mixture of Experts Using Tensor Products
May 26, 2024



In multi-task learning, the conventional approach involves training a model on multiple tasks simultaneously. However, the training signals from different tasks can interfere with one another, potentially leading to \textit{negative transfer}. To mitigate this, we investigate if modular language models can facilitate positive transfer and systematic generalization. Specifically, we propose a novel modular language model (\texttt{TensorPoly}), that balances parameter efficiency with nuanced routing methods. For \textit{modules}, we reparameterize Low-Rank Adaptation (\texttt{LoRA}) by employing an entangled tensor through the use of tensor product operations and name the resulting approach \texttt{TLoRA}. For \textit{routing function}, we tailor two innovative routing functions according to the granularity: \texttt{TensorPoly-I} which directs to each rank within the entangled tensor while \texttt{TensorPoly-II} offers a finer-grained routing approach targeting each order of the entangled tensor. The experimental results from the multi-task T0-benchmark demonstrate that: 1) all modular LMs surpass the corresponding dense approaches, highlighting the potential of modular language models to mitigate negative inference in multi-task learning and deliver superior outcomes. 2) \texttt{TensorPoly-I} achieves higher parameter efficiency in adaptation and outperforms other modular LMs, which shows the potential of our approach in multi-task transfer learning.