 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Apriel: One Checkpoint, Many Speeds
Apr 21, 2026We release Super Apriel, a 15B-parameter supernet in which every decoder layer provides four trained mixer choices -- Full Attention (FA), Sliding Window Attention (SWA), Kimi Delta Attention (KDA), and Gated DeltaNet (GDN). A placement selects one mixer per layer; placements can be switched between requests at serving time without reloading weights, enabling multiple speed presets from a single checkpoint. The shared checkpoint also enables speculative decoding without a separate draft model. The all-FA preset matches the Apriel 1.6 teacher on all reported benchmarks; recommended hybrid presets span $2.9\times$ to $10.7\times$ decode throughput at 96% to 77% quality retention, with throughput advantages that compound at longer context lengths. With four mixer types across 48 layers, the configuration space is vast. A surrogate that predicts placement quality from the per-layer mixer assignment makes the speed-quality landscape tractable and identifies the best tradeoffs at each speed level. We investigate whether the best configurations at each speed level can be identified early in training or only after convergence. Rankings stabilize quickly at 0.5B scale, but the most efficient configurations exhibit higher instability at 15B, cautioning against extrapolation from smaller models. Super Apriel is trained by stochastic distillation from a frozen Apriel 1.6 teacher, followed by supervised fine-tuning. We release the supernet weights, Fast-LLM training code, vLLM serving code, and a placement optimization toolkit.
Using Scaling Laws for Data Source Utility Estimation in Domain-Specific Pre-Training
Jul 29, 2025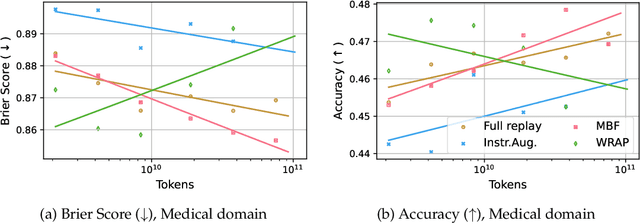
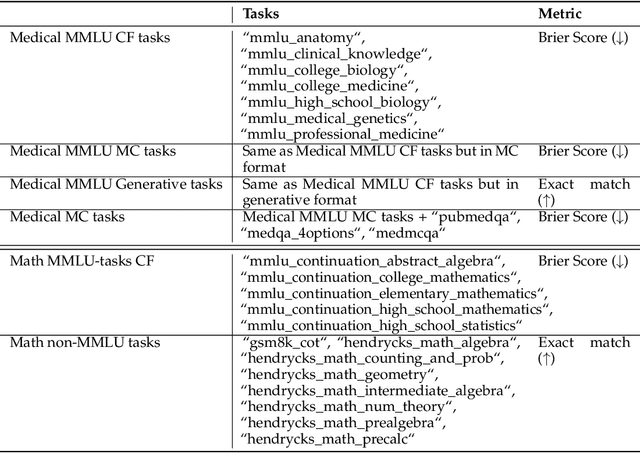
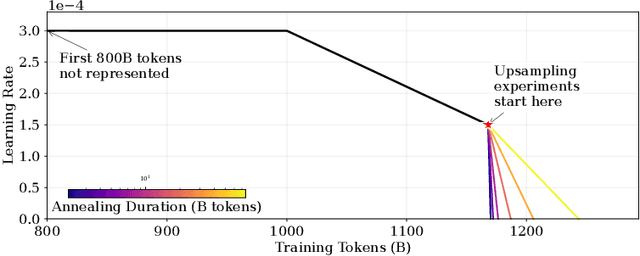
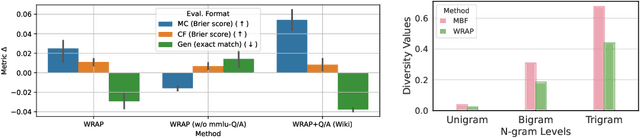
We introduce a framework for optimizing domain-specific dataset construction in foundation model training. Specifically, we seek a cost-efficient way to estimate the quality of data sources (e.g. synthetically generated or filtered web data, etc.) in order to make optimal decisions about resource allocation for data sourcing from these sources for the stage two pre-training phase, aka annealing, with the goal of specializing a generalist pre-trained model to specific domains. Our approach extends the usual point estimate approaches, aka micro-annealing, to estimating scaling laws by performing multiple annealing runs of varying compute spent on data curation and training. This addresses a key limitation in prior work, where reliance on point estimates for data scaling decisions can be misleading due to the lack of rank invariance across compute scales -- a phenomenon we confirm in our experiments. By systematically analyzing performance gains relative to acquisition costs, we find that scaling curves can be estimated for different data sources. Such scaling laws can inform cost effective resource allocation across different data acquisition methods (e.g. synthetic data), data sources (e.g. user or web data) and available compute resources. We validate our approach through experiments on a pre-trained model with 7 billion parameters. We adapt it to: a domain well-represented in the pre-training data -- the medical domain, and a domain underrepresented in the pretraining corpora -- the math domain. We show that one can efficiently estimate the scaling behaviors of a data source by running multiple annealing runs, which can lead to different conclusions, had one used point estimates using the usual micro-annealing technique instead. This enables data-driven decision-making for selecting and optimizing data sources.
Towards Modular LLMs by Building and Reusing a Library of LoRAs
May 18, 2024


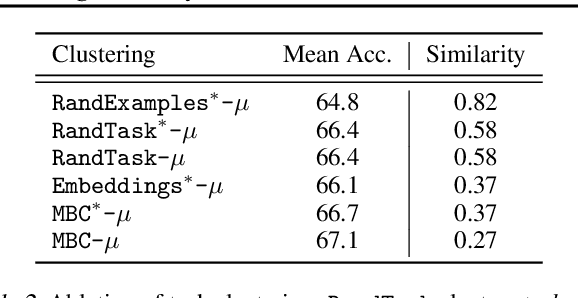
The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
Guiding Language Model Reasoning with Planning Tokens
Oct 09, 2023



Large language models (LLMs) have recently attracted considerable interest for their ability to perform complex reasoning tasks, such as chain-of-thought reasoning. However, most of the existing approaches to enhance this ability rely heavily on data-driven methods, while neglecting the structural aspects of the model's reasoning capacity. We find that while LLMs can manage individual reasoning steps well, they struggle with maintaining consistency across an entire reasoning chain. To solve this, we introduce 'planning tokens' at the start of each reasoning step, serving as a guide for the model. These token embeddings are then fine-tuned along with the rest of the model parameters. Our approach requires a negligible increase in trainable parameters (just 0.001%) and can be applied through either full fine-tuning or a more parameter-efficient scheme. We demonstrate our method's effectiveness by applying it to three different LLMs, showing notable accuracy improvements across three math word problem datasets w.r.t. plain chain-of-thought fine-tuning baselines.
Scaling the Number of Tasks in Continual Learning
Jul 10, 2022
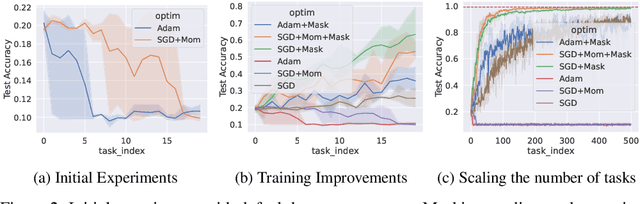

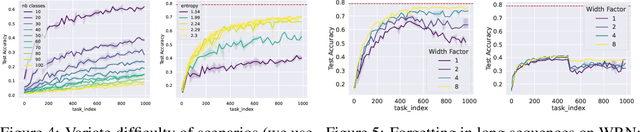
Standard gradient descent algorithms applied to sequences of tasks are known to produce catastrophic forgetting in deep neural networks. When trained on a new task in a sequence, the model updates its parameters on the current task, forgetting past knowledge. This article explores scenarios where we scale the number of tasks in a finite environment. Those scenarios are composed of a long sequence of tasks with reoccurring data. We show that in such setting, stochastic gradient descent can learn, progress, and converge to a solution that according to existing literature needs a continual learning algorithm. In other words, we show that the model performs knowledge retention and accumulation without specific memorization mechanisms. We propose a new experimentation framework, SCoLe (Scaling Continual Learning), to study the knowledge retention and accumulation of algorithms in potentially infinite sequences of tasks. To explore this setting, we performed a large number of experiments on sequences of 1,000 tasks to better understand this new family of settings. We also propose a slight modifications to the vanilla stochastic gradient descent to facilitate continual learning in this setting. The SCoLe framework represents a good simulation of practical training environments with reoccurring situations and allows the study of convergence behavior in long sequences. Our experiments show that previous results on short scenarios cannot always be extrapolated to longer scenarios.
Foundational Models for Continual Learning: An Empirical Study of Latent Replay
Apr 30, 2022
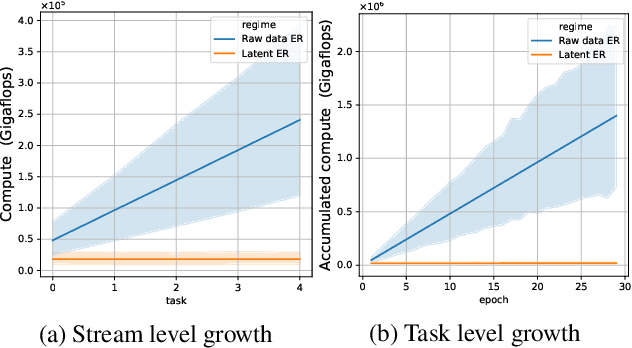
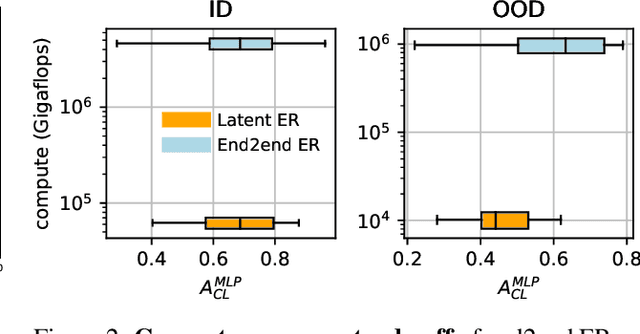
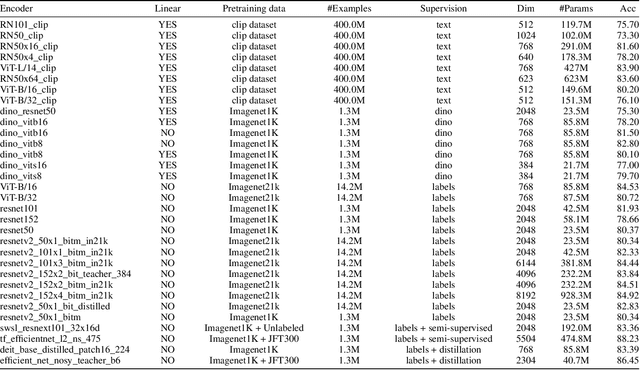
Rapid development of large-scale pre-training has resulted in foundation models that can act as effective feature extractors on a variety of downstream tasks and domains. Motivated by this, we study the efficacy of pre-trained vision models as a foundation for downstream continual learning (CL) scenarios. Our goal is twofold. First, we want to understand the compute-accuracy trade-off between CL in the raw-data space and in the latent space of pre-trained encoders. Second, we investigate how the characteristics of the encoder, the pre-training algorithm and data, as well as of the resulting latent space affect CL performance. For this, we compare the efficacy of various pre-trained models in large-scale benchmarking scenarios with a vanilla replay setting applied in the latent and in the raw-data space. Notably, this study shows how transfer, forgetting, task similarity and learning are dependent on the input data characteristics and not necessarily on the CL algorithms. First, we show that under some circumstances reasonable CL performance can readily be achieved with a non-parametric classifier at negligible compute. We then show how models pre-trained on broader data result in better performance for various replay sizes. We explain this with representational similarity and transfer properties of these representations. Finally, we show the effectiveness of self-supervised pre-training for downstream domains that are out-of-distribution as compared to the pre-training domain. We point out and validate several research directions that can further increase the efficacy of latent CL including representation ensembling. The diverse set of datasets used in this study can serve as a compute-efficient playground for further CL research. The codebase is available under https://github.com/oleksost/latent_CL.
Continual Learning via Local Module Composition
Nov 15, 2021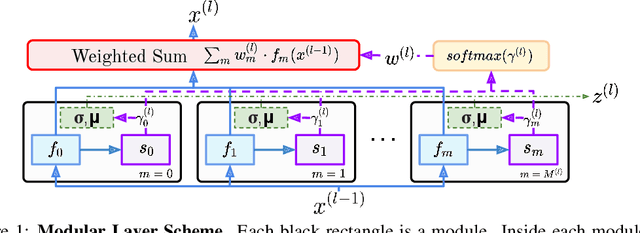
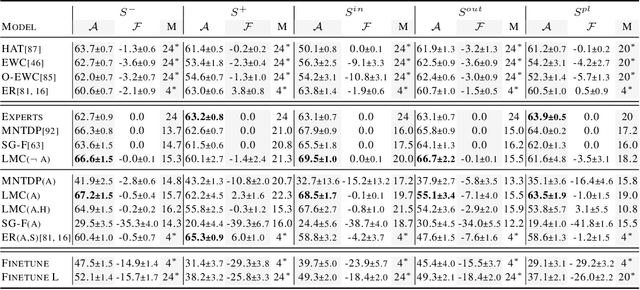
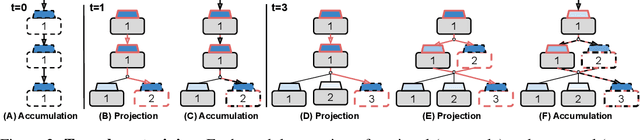
Modularity is a compelling solution to continual learning (CL), the problem of modeling sequences of related tasks. Learning and then composing modules to solve different tasks provides an abstraction to address the principal challenges of CL including catastrophic forgetting, backward and forward transfer across tasks, and sub-linear model growth. We introduce local module composition (LMC), an approach to modular CL where each module is provided a local structural component that estimates a module's relevance to the input. Dynamic module composition is performed layer-wise based on local relevance scores. We demonstrate that agnosticity to task identities (IDs) arises from (local) structural learning that is module-specific as opposed to the task- and/or model-specific as in previous works, making LMC applicable to more CL settings compared to previous works. In addition, LMC also tracks statistics about the input distribution and adds new modules when outlier samples are detected. In the first set of experiments, LMC performs favorably compared to existing methods on the recent Continual Transfer-learning Benchmark without requiring task identities. In another study, we show that the locality of structural learning allows LMC to interpolate to related but unseen tasks (OOD), as well as to compose modular networks trained independently on different task sequences into a third modular network without any fine-tuning. Finally, in search for limitations of LMC we study it on more challenging sequences of 30 and 100 tasks, demonstrating that local module selection becomes much more challenging in presence of a large number of candidate modules. In this setting best performing LMC spawns much fewer modules compared to an oracle based baseline, however, it reaches a lower overall accuracy. The codebase is available under https://github.com/oleksost/LMC.
Sequoia: A Software Framework to Unify Continual Learning Research
Aug 03, 2021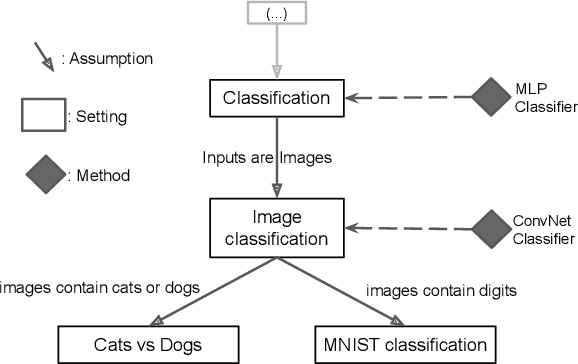
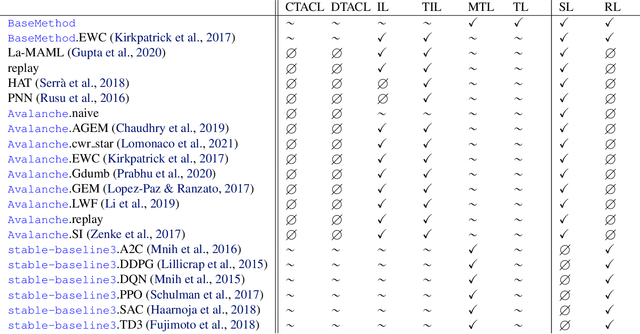
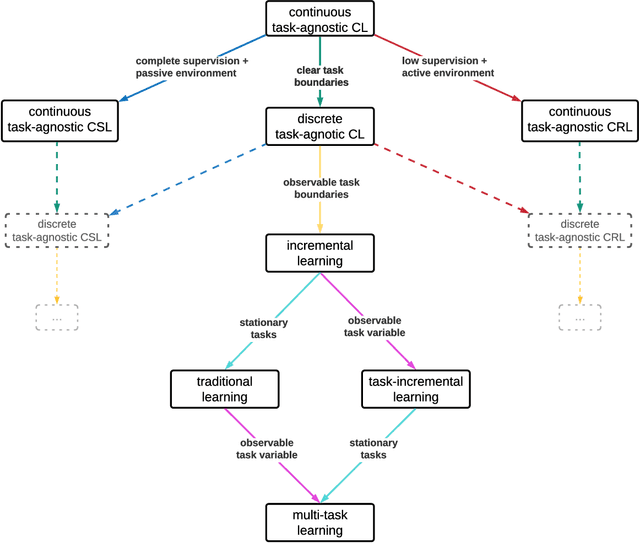
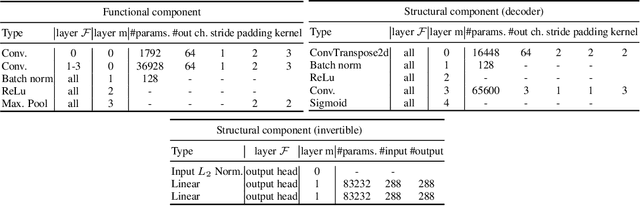
The field of Continual Learning (CL) seeks to develop algorithms that accumulate knowledge and skills over time through interaction with non-stationary environments and data distributions. Measuring progress in CL can be difficult because a plethora of evaluation procedures (ettings) and algorithmic solutions (methods) have emerged, each with their own potentially disjoint set of assumptions about the CL problem. In this work, we view each setting as a set of assumptions. We then create a tree-shaped hierarchy of the research settings in CL, in which more general settings become the parents of those with more restrictive assumptions. This makes it possible to use inheritance to share and reuse research, as developing a method for a given setting also makes it directly applicable onto any of its children. We instantiate this idea as a publicly available software framework called Sequoia, which features a variety of settings from both the Continual Supervised Learning (CSL) and Continual Reinforcement Learning (CRL) domains. Sequoia also includes a growing suite of methods which are easy to extend and customize, in addition to more specialized methods from third-party libraries. We hope that this new paradigm and its first implementation can serve as a foundation for the unification and acceleration of research in CL. You can help us grow the tree by visiting www.github.com/lebrice/Sequoia.
Online Fast Adaptation and Knowledge Accumulation: a New Approach to Continual Learning
Mar 12, 2020
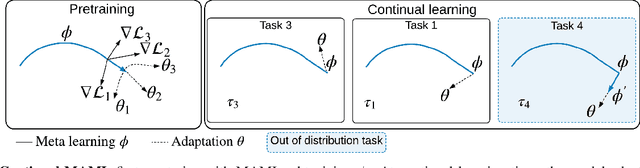
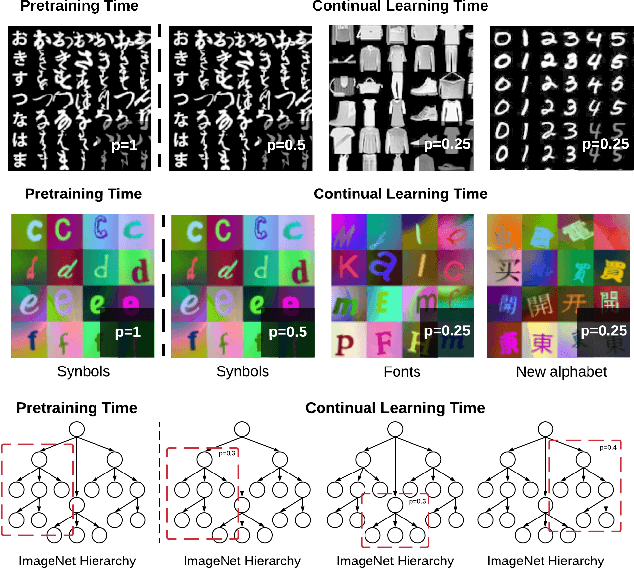
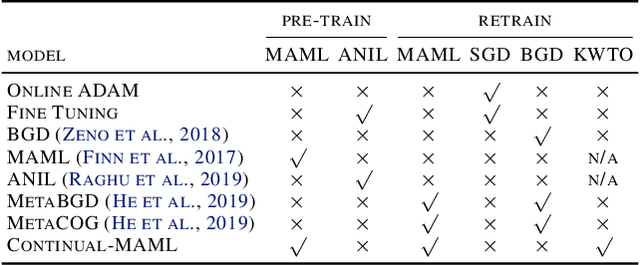
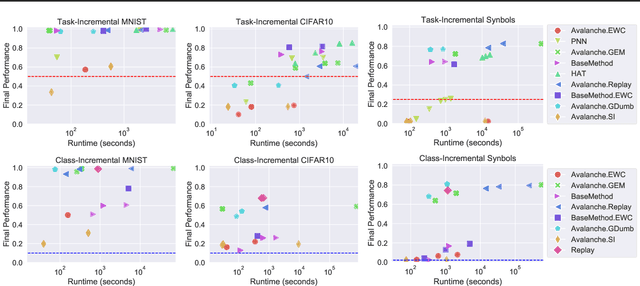
Learning from non-stationary data remains a great challenge for machine learning. Continual learning addresses this problem in scenarios where the learning agent faces a stream of changing tasks. In these scenarios, the agent is expected to retain its highest performance on previous tasks without revisiting them while adapting well to the new tasks. Two new recent continual-learning scenarios have been proposed. In meta-continual learning, the model is pre-trained to minimize catastrophic forgetting when trained on a sequence of tasks. In continual-meta learning, the goal is faster remembering, i.e., focusing on how quickly the agent recovers performance rather than measuring the agent's performance without any adaptation. Both scenarios have the potential to propel the field forward. Yet in their original formulations, they each have limitations. As a remedy, we propose a more general scenario where an agent must quickly solve (new) out-of-distribution tasks, while also requiring fast remembering. We show that current continual learning, meta learning, meta-continual learning, and continual-meta learning techniques fail in this new scenario. Accordingly, we propose a strong baseline: Continual-MAML, an online extension of the popular MAML algorithm. In our empirical experiments, we show that our method is better suited to the new scenario than the methodologies mentioned above, as well as standard continual learning and meta learning approaches.
Pruning at a Glance: Global Neural Pruning for Model Compression
Dec 03, 2019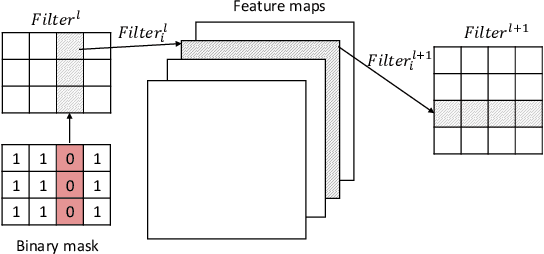
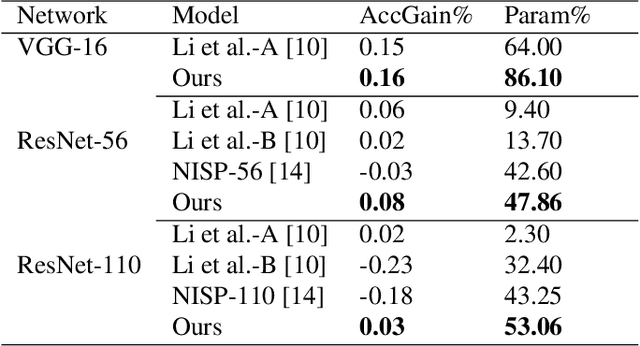
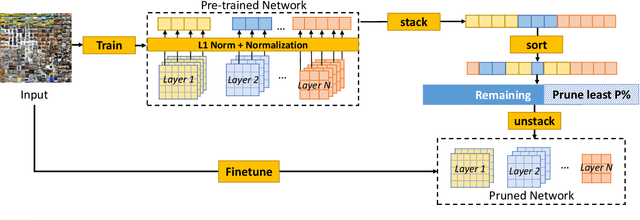
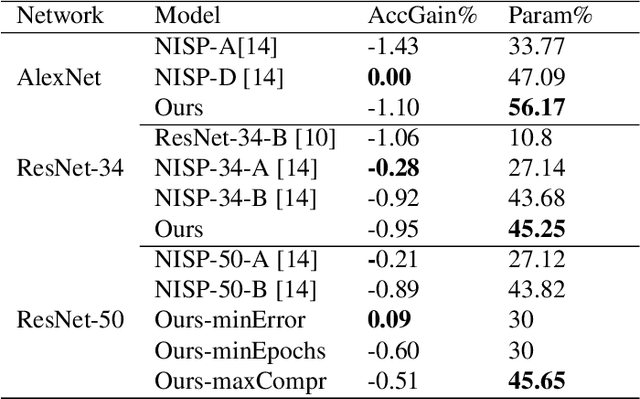
Deep Learning models have become the dominant approach in several areas due to their high performance. Unfortunately, the size and hence computational requirements of operating such models can be considerably high. Therefore, this constitutes a limitation for deployment on memory and battery constrained devices such as mobile phones or embedded systems. To address these limitations, we propose a novel and simple pruning method that compresses neural networks by removing entire filters and neurons according to a global threshold across the network without any pre-calculation of layer sensitivity. The resulting model is compact, non-sparse, with the same accuracy as the non-compressed model, and most importantly requires no special infrastructure for deployment. We prove the viability of our method by producing highly compressed models, namely VGG-16, ResNet-56, and ResNet-110 respectively on CIFAR10 without losing any performance compared to the baseline, as well as ResNet-34 and ResNet-50 on ImageNet without a significant loss of accuracy. We also provide a well-retrained 30% compressed ResNet-50 that slightly surpasses the base model accuracy. Additionally, compressing more than 56% and 97% of AlexNet and LeNet-5 respectively. Interestingly, the resulted models' pruning patterns are highly similar to the other methods using layer sensitivity pre-calculation step. Our method does not only exhibit good performance but what is more also easy to implement.