 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplifying Pathological Detection in EEG Signaling Pathways through Cross-Dataset Transfer Learning
Sep 19, 2023


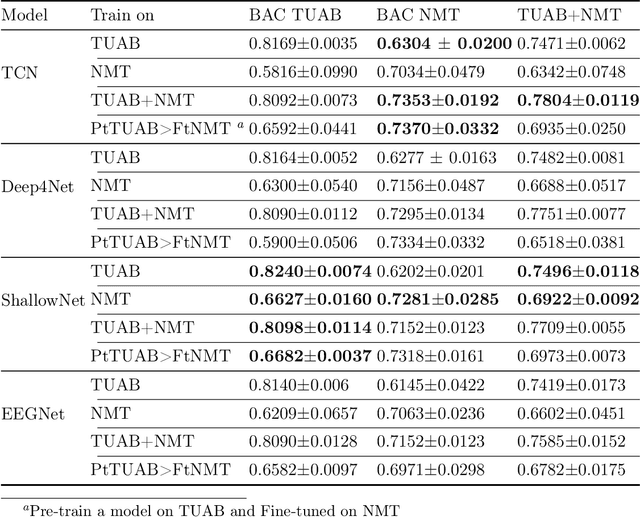
Pathology diagnosis based on EEG signals and decoding brain activity holds immense importance in understanding neurological disorders. With the advancement of artificial intelligence methods and machine learning techniques, the potential for accurate data-driven diagnoses and effective treatments has grown significantly. However, applying machine learning algorithms to real-world datasets presents diverse challenges at multiple levels. The scarcity of labelled data, especially in low regime scenarios with limited availability of real patient cohorts due to high costs of recruitment, underscores the vital deployment of scaling and transfer learning techniques. In this study, we explore a real-world pathology classification task to highlight the effectiveness of data and model scaling and cross-dataset knowledge transfer. As such, we observe varying performance improvements through data scaling, indicating the need for careful evaluation and labelling. Additionally, we identify the challenges of possible negative transfer and emphasize the significance of some key components to overcome distribution shifts and potential spurious correlations and achieve positive transfer. We see improvement in the performance of the target model on the target (NMT) datasets by using the knowledge from the source dataset (TUAB) when a low amount of labelled data was available. Our findings indicate a small and generic model (e.g. ShallowNet) performs well on a single dataset, however, a larger model (e.g. TCN) performs better on transfer and learning from a larger and diverse dataset.
Foundational Models for Continual Learning: An Empirical Study of Latent Replay
Apr 30, 2022
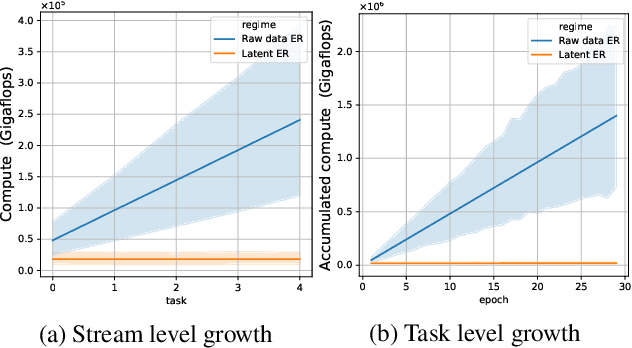
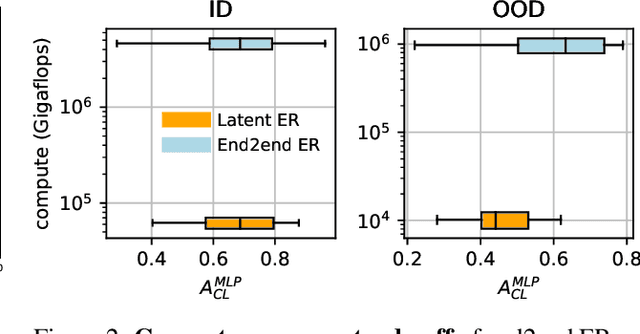
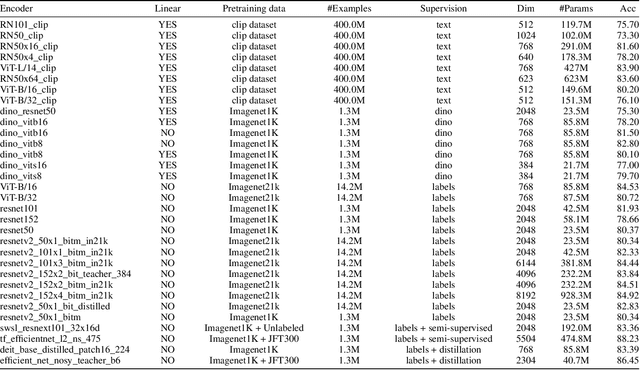
Rapid development of large-scale pre-training has resulted in foundation models that can act as effective feature extractors on a variety of downstream tasks and domains. Motivated by this, we study the efficacy of pre-trained vision models as a foundation for downstream continual learning (CL) scenarios. Our goal is twofold. First, we want to understand the compute-accuracy trade-off between CL in the raw-data space and in the latent space of pre-trained encoders. Second, we investigate how the characteristics of the encoder, the pre-training algorithm and data, as well as of the resulting latent space affect CL performance. For this, we compare the efficacy of various pre-trained models in large-scale benchmarking scenarios with a vanilla replay setting applied in the latent and in the raw-data space. Notably, this study shows how transfer, forgetting, task similarity and learning are dependent on the input data characteristics and not necessarily on the CL algorithms. First, we show that under some circumstances reasonable CL performance can readily be achieved with a non-parametric classifier at negligible compute. We then show how models pre-trained on broader data result in better performance for various replay sizes. We explain this with representational similarity and transfer properties of these representations. Finally, we show the effectiveness of self-supervised pre-training for downstream domains that are out-of-distribution as compared to the pre-training domain. We point out and validate several research directions that can further increase the efficacy of latent CL including representation ensembling. The diverse set of datasets used in this study can serve as a compute-efficient playground for further CL research. The codebase is available under https://github.com/oleksost/latent_CL.
Exploring to learn visual saliency: The RL-IAC approach
Apr 02, 2018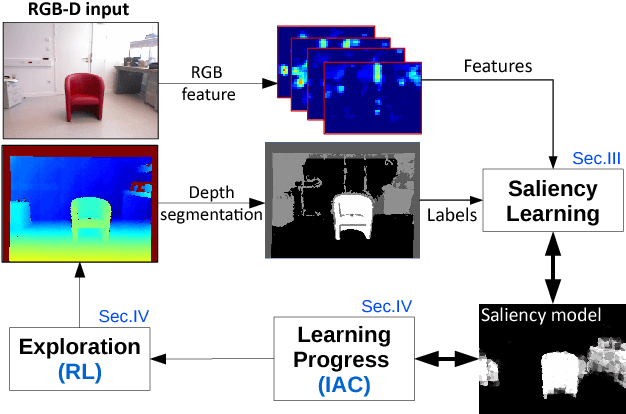
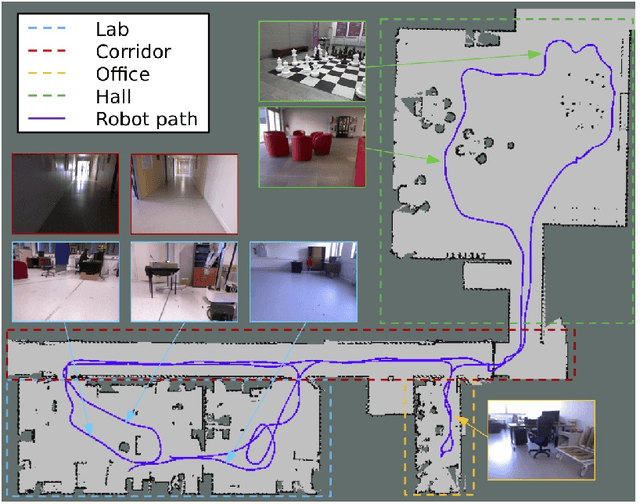

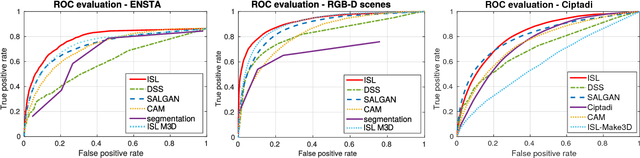
The problem of object localization and recognition on autonomous mobile robots is still an active topic. In this context, we tackle the problem of learning a model of visual saliency directly on a robot. This model, learned and improved on-the-fly during the robot's exploration provides an efficient tool for localizing relevant objects within their environment. The proposed approach includes two intertwined components. On the one hand, we describe a method for learning and incrementally updating a model of visual saliency from a depth-based object detector. This model of saliency can also be exploited to produce bounding box proposals around objects of interest. On the other hand, we investigate an autonomous exploration technique to efficiently learn such a saliency model. The proposed exploration, called Reinforcement Learning-Intelligent Adaptive Curiosity (RL-IAC) is able to drive the robot's exploration so that samples selected by the robot are likely to improve the current model of saliency. We then demonstrate that such a saliency model learned directly on a robot outperforms several state-of-the-art saliency techniques, and that RL-IAC can drastically decrease the required time for learning a reliable saliency model.