 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust multimodal models have outlier features and encode more concepts
Oct 19, 2023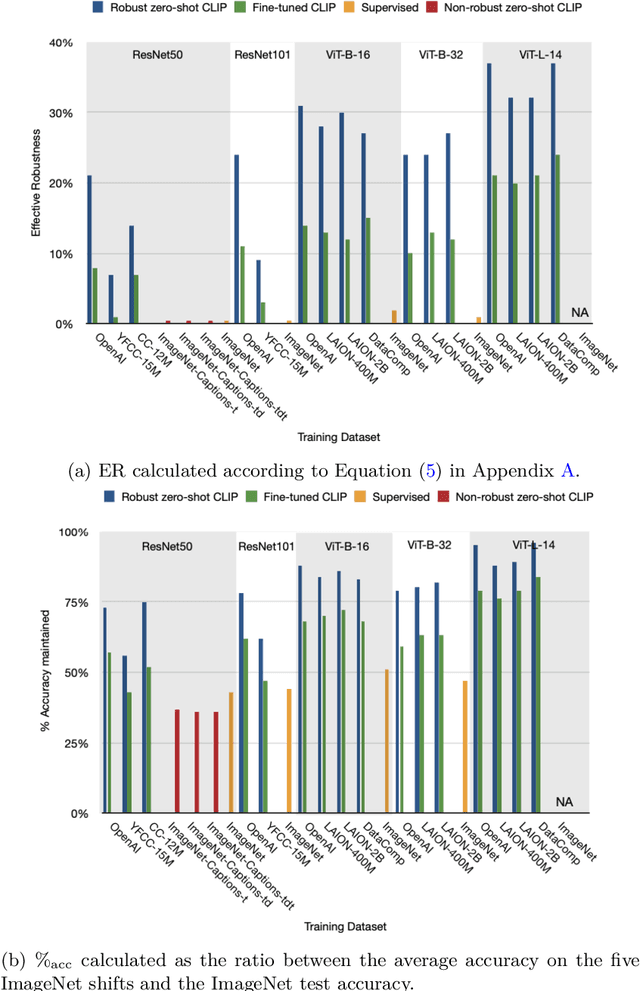
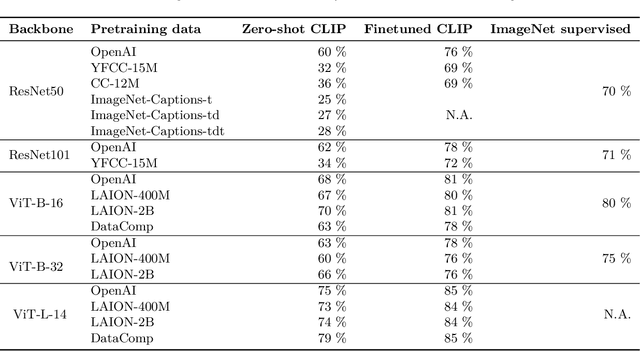
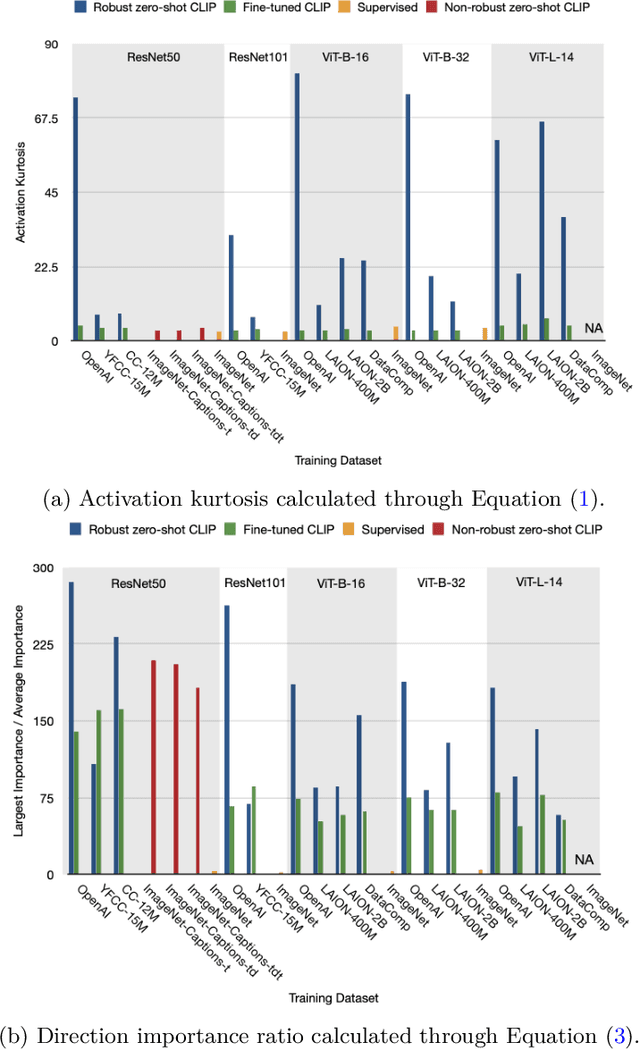
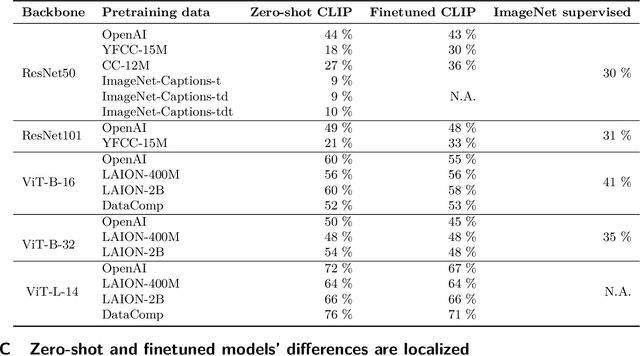
What distinguishes robust models from non-robust ones? This question has gained traction with the appearance of large-scale multimodal models, such as CLIP. These models have demonstrated unprecedented robustness with respect to natural distribution shifts. While it has been shown that such differences in robustness can be traced back to differences in training data, so far it is not known what that translates to in terms of what the model has learned. In this work, we bridge this gap by probing the representation spaces of 12 robust multimodal models with various backbones (ResNets and ViTs) and pretraining sets (OpenAI, LAION-400M, LAION-2B, YFCC15M, CC12M and DataComp). We find two signatures of robustness in the representation spaces of these models: (1) Robust models exhibit outlier features characterized by their activations, with some being several orders of magnitude above average. These outlier features induce privileged directions in the model's representation space. We demonstrate that these privileged directions explain most of the predictive power of the model by pruning up to $80 \%$ of the least important representation space directions without negative impacts on model accuracy and robustness; (2) Robust models encode substantially more concepts in their representation space. While this superposition of concepts allows robust models to store much information, it also results in highly polysemantic features, which makes their interpretation challenging. We discuss how these insights pave the way for future research in various fields, such as model pruning and mechanistic interpretability.
DeepPCR: Parallelizing Sequential Operations in Neural Networks
Sep 28, 2023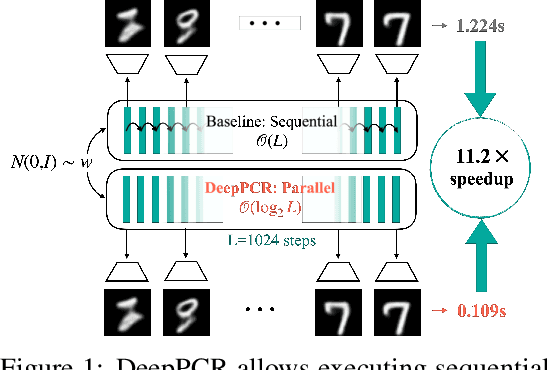



Parallelization techniques have become ubiquitous for accelerating inference and training of deep neural networks. Despite this, several operations are still performed in a sequential manner. For instance, the forward and backward passes are executed layer-by-layer, and the output of diffusion models is produced by applying a sequence of denoising steps. This sequential approach results in a computational cost proportional to the number of steps involved, presenting a potential bottleneck as the number of steps increases. In this work, we introduce DeepPCR, a novel algorithm which parallelizes typically sequential operations used in inference and training of neural networks. DeepPCR is based on interpreting a sequence of $L$ steps as the solution of a specific system of equations, which we recover using the Parallel Cyclic Reduction algorithm. This reduces the complexity of computing the sequential operations from $\mathcal{O}(L)$ to $\mathcal{O}(\log_2L)$, thus yielding a speedup for large $L$. To verify the theoretical lower complexity of the algorithm, and to identify regimes for speedup, we test the effectiveness of DeepPCR in parallelizing the forward and backward pass in multi-layer perceptrons, and reach speedups of up to $30\times$ for forward and $200\times$ for backward pass. We additionally showcase the flexibility of DeepPCR by parallelizing training of ResNets with as many as 1024 layers, and generation in diffusion models, enabling up to $7\times$ faster training and $11\times$ faster generation, respectively, when compared to the sequential approach.
The Role of Entropy and Reconstruction in Multi-View Self-Supervised Learning
Jul 20, 2023



The mechanisms behind the success of multi-view self-supervised learning (MVSSL) are not yet fully understood. Contrastive MVSSL methods have been studied through the lens of InfoNCE, a lower bound of the Mutual Information (MI). However, the relation between other MVSSL methods and MI remains unclear. We consider a different lower bound on the MI consisting of an entropy and a reconstruction term (ER), and analyze the main MVSSL families through its lens. Through this ER bound, we show that clustering-based methods such as DeepCluster and SwAV maximize the MI. We also re-interpret the mechanisms of distillation-based approaches such as BYOL and DINO, showing that they explicitly maximize the reconstruction term and implicitly encourage a stable entropy, and we confirm this empirically. We show that replacing the objectives of common MVSSL methods with this ER bound achieves competitive performance, while making them stable when training with smaller batch sizes or smaller exponential moving average (EMA) coefficients. Github repo: https://github.com/apple/ml-entropy-reconstruction.
Scaling the Number of Tasks in Continual Learning
Jul 10, 2022
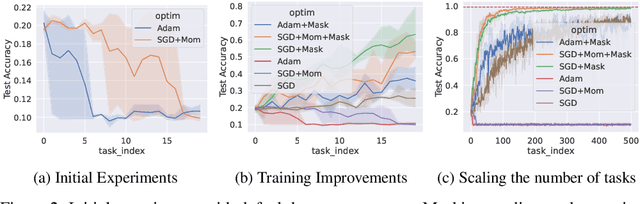

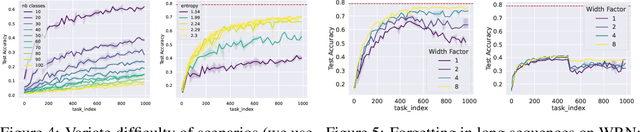
Standard gradient descent algorithms applied to sequences of tasks are known to produce catastrophic forgetting in deep neural networks. When trained on a new task in a sequence, the model updates its parameters on the current task, forgetting past knowledge. This article explores scenarios where we scale the number of tasks in a finite environment. Those scenarios are composed of a long sequence of tasks with reoccurring data. We show that in such setting, stochastic gradient descent can learn, progress, and converge to a solution that according to existing literature needs a continual learning algorithm. In other words, we show that the model performs knowledge retention and accumulation without specific memorization mechanisms. We propose a new experimentation framework, SCoLe (Scaling Continual Learning), to study the knowledge retention and accumulation of algorithms in potentially infinite sequences of tasks. To explore this setting, we performed a large number of experiments on sequences of 1,000 tasks to better understand this new family of settings. We also propose a slight modifications to the vanilla stochastic gradient descent to facilitate continual learning in this setting. The SCoLe framework represents a good simulation of practical training environments with reoccurring situations and allows the study of convergence behavior in long sequences. Our experiments show that previous results on short scenarios cannot always be extrapolated to longer scenarios.
Foundational Models for Continual Learning: An Empirical Study of Latent Replay
Apr 30, 2022
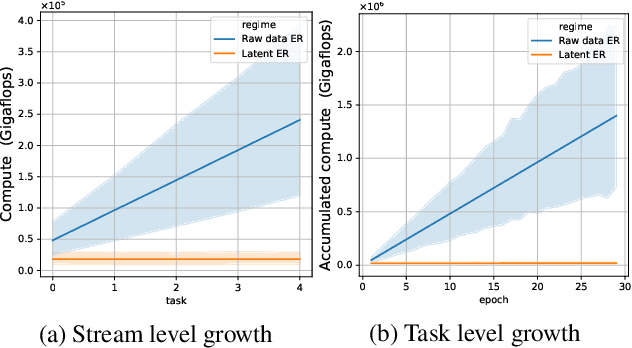
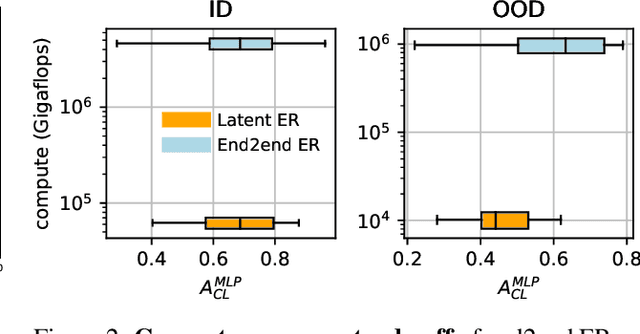
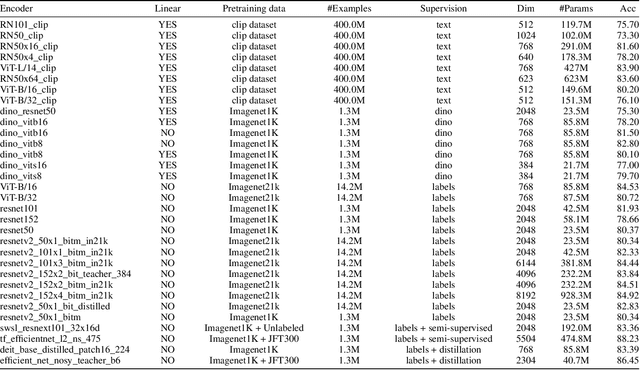
Rapid development of large-scale pre-training has resulted in foundation models that can act as effective feature extractors on a variety of downstream tasks and domains. Motivated by this, we study the efficacy of pre-trained vision models as a foundation for downstream continual learning (CL) scenarios. Our goal is twofold. First, we want to understand the compute-accuracy trade-off between CL in the raw-data space and in the latent space of pre-trained encoders. Second, we investigate how the characteristics of the encoder, the pre-training algorithm and data, as well as of the resulting latent space affect CL performance. For this, we compare the efficacy of various pre-trained models in large-scale benchmarking scenarios with a vanilla replay setting applied in the latent and in the raw-data space. Notably, this study shows how transfer, forgetting, task similarity and learning are dependent on the input data characteristics and not necessarily on the CL algorithms. First, we show that under some circumstances reasonable CL performance can readily be achieved with a non-parametric classifier at negligible compute. We then show how models pre-trained on broader data result in better performance for various replay sizes. We explain this with representational similarity and transfer properties of these representations. Finally, we show the effectiveness of self-supervised pre-training for downstream domains that are out-of-distribution as compared to the pre-training domain. We point out and validate several research directions that can further increase the efficacy of latent CL including representation ensembling. The diverse set of datasets used in this study can serve as a compute-efficient playground for further CL research. The codebase is available under https://github.com/oleksost/latent_CL.
SSR: Semi-supervised Soft Rasterizer for single-view 2D to 3D Reconstruction
Aug 21, 2021

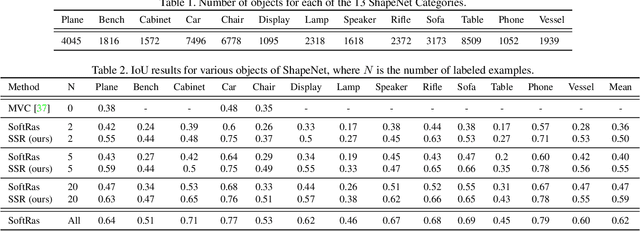

Recent work has made significant progress in learning object meshes with weak supervision. Soft Rasterization methods have achieved accurate 3D reconstruction from 2D images with viewpoint supervision only. In this work, we further reduce the labeling effort by allowing such 3D reconstruction methods leverage unlabeled images. In order to obtain the viewpoints for these unlabeled images, we propose to use a Siamese network that takes two images as input and outputs whether they correspond to the same viewpoint. During training, we minimize the cross entropy loss to maximize the probability of predicting whether a pair of images belong to the same viewpoint or not. To get the viewpoint of a new image, we compare it against different viewpoints obtained from the training samples and select the viewpoint with the highest matching probability. We finally label the unlabeled images with the most confident predicted viewpoint and train a deep network that has a differentiable rasterization layer. Our experiments show that even labeling only two objects yields significant improvement in IoU for ShapeNet when leveraging unlabeled examples. Code is available at https://github.com/IssamLaradji/SSR.
Can Active Learning Preemptively Mitigate Fairness Issues?
Apr 14, 2021



Dataset bias is one of the prevailing causes of unfairness in machine learning. Addressing fairness at the data collection and dataset preparation stages therefore becomes an essential part of training fairer algorithms. In particular, active learning (AL) algorithms show promise for the task by drawing importance to the most informative training samples. However, the effect and interaction between existing AL algorithms and algorithmic fairness remain under-explored. In this paper, we study whether models trained with uncertainty-based AL heuristics such as BALD are fairer in their decisions with respect to a protected class than those trained with identically independently distributed (i.i.d.) sampling. We found a significant improvement on predictive parity when using BALD, while also improving accuracy compared to i.i.d. sampling. We also explore the interaction of algorithmic fairness methods such as gradient reversal (GRAD) and BALD. We found that, while addressing different fairness issues, their interaction further improves the results on most benchmarks and metrics we explored.
Synbols: Probing Learning Algorithms with Synthetic Datasets
Sep 14, 2020
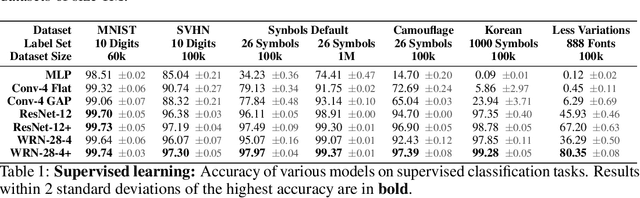
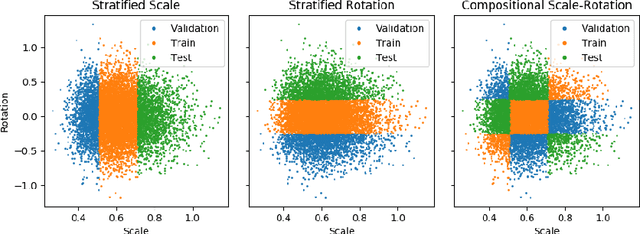
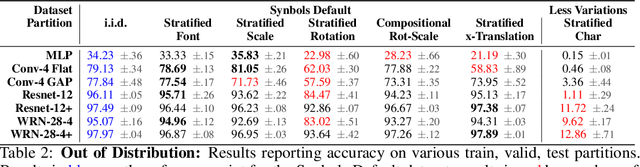
Progress in the field of machine learning has been fueled by the introduction of benchmark datasets pushing the limits of existing algorithms. Enabling the design of datasets to test specific properties and failure modes of learning algorithms is thus a problem of high interest, as it has a direct impact on innovation in the field. In this sense, we introduce Synbols -- Synthetic Symbols -- a tool for rapidly generating new datasets with a rich composition of latent features rendered in low resolution images. Synbols leverages the large amount of symbols available in the Unicode standard and the wide range of artistic font provided by the open font community. Our tool's high-level interface provides a language for rapidly generating new distributions on the latent features, including various types of textures and occlusions. To showcase the versatility of Synbols, we use it to dissect the limitations and flaws in standard learning algorithms in various learning setups including supervised learning, active learning, out of distribution generalization, unsupervised representation learning, and object counting.
Embedding Propagation: Smoother Manifold for Few-Shot Classification
Mar 09, 2020


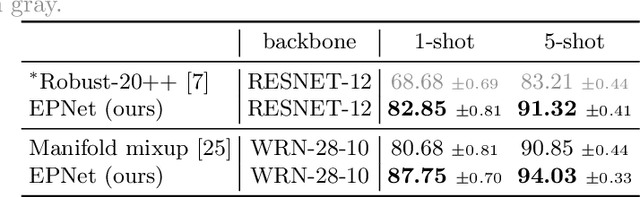
Few-shot classification is challenging because the data distribution of the training set can be widely different to the distribution of the test set as their classes are disjoint. This distribution shift often results in poor generalization. Manifold smoothing has been shown to address the distribution shift problem by extending the decision boundaries and reducing the noise of the class representations. Moreover, manifold smoothness is a key factor for semi-supervised learning and transductive learning algorithms. In this work, we present embedding propagation as an unsupervised non-parametric regularizer for manifold smoothing. Embedding propagation leverages interpolations between the extracted features of a neural network based on a similarity graph. We empirically show that embedding propagation yields a smoother embedding manifold. We also show that incorporating embedding propagation to a transductive classifier leads to new state-of-the-art results in mini-Imagenet, tiered-Imagenet, and CUB. Furthermore, we show that embedding propagation results in additional improvement in performance for semi-supervised learning scenarios.
Attend and Rectify: a Gated Attention Mechanism for Fine-Grained Recovery
Jul 24, 2018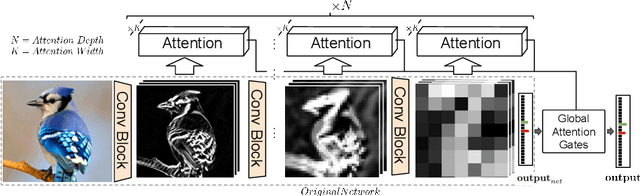
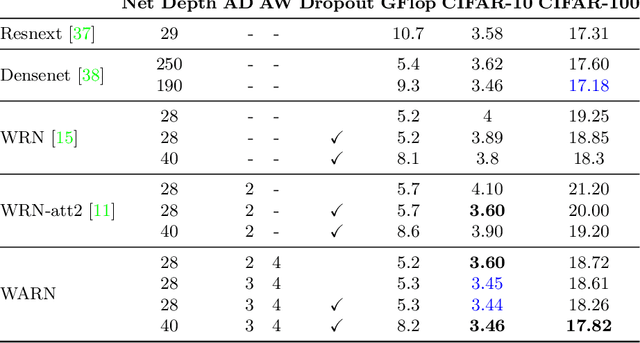
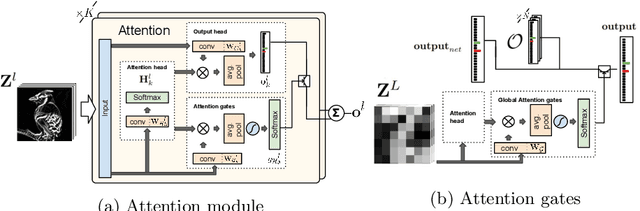

We propose a novel attention mechanism to enhance Convolutional Neural Networks for fine-grained recognition. It learns to attend to lower-level feature activations without requiring part annotations and uses these activations to update and rectify the output likelihood distribution. In contrast to other approaches, the proposed mechanism is modular, architecture-independent and efficient both in terms of parameters and computation required. Experiments show that networks augmented with our approach systematically improve their classification accuracy and become more robust to clutter. As a result, Wide Residual Networks augmented with our proposal surpasses the state of the art classification accuracies in CIFAR-10, the Adience gender recognition task, Stanford dogs, and UEC Food-100.