 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Discriminators for Content-Consistent Unpaired Image-to-Image Translation
Sep 22, 2023A common goal of unpaired image-to-image translation is to preserve content consistency between source images and translated images while mimicking the style of the target domain. Due to biases between the datasets of both domains, many methods suffer from inconsistencies caused by the translation process. Most approaches introduced to mitigate these inconsistencies do not constrain the discriminator, leading to an even more ill-posed training setup. Moreover, none of these approaches is designed for larger crop sizes. In this work, we show that masking the inputs of a global discriminator for both domains with a content-based mask is sufficient to reduce content inconsistencies significantly. However, this strategy leads to artifacts that can be traced back to the masking process. To reduce these artifacts, we introduce a local discriminator that operates on pairs of small crops selected with a similarity sampling strategy. Furthermore, we apply this sampling strategy to sample global input crops from the source and target dataset. In addition, we propose feature-attentive denormalization to selectively incorporate content-based statistics into the generator stream. In our experiments, we show that our method achieves state-of-the-art performance in photorealistic sim-to-real translation and weather translation and also performs well in day-to-night translation. Additionally, we propose the cKVD metric, which builds on the sKVD metric and enables the examination of translation quality at the class or category level.
Attend and Rectify: a Gated Attention Mechanism for Fine-Grained Recovery
Jul 24, 2018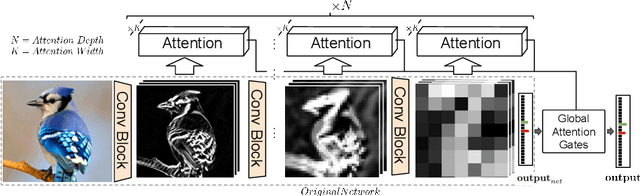
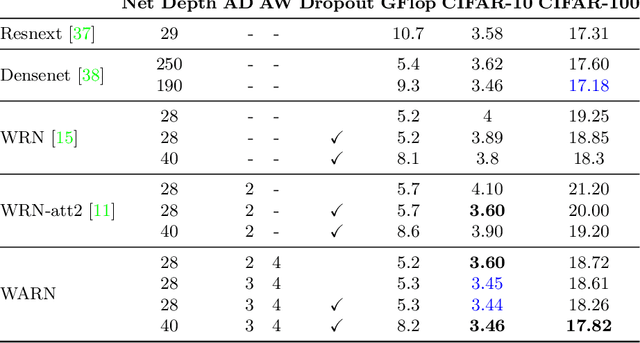
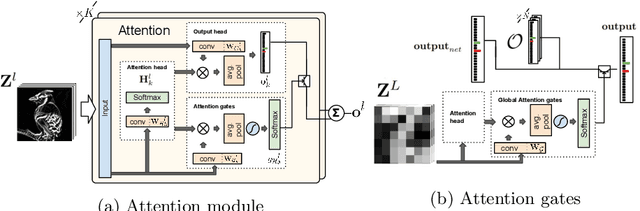

We propose a novel attention mechanism to enhance Convolutional Neural Networks for fine-grained recognition. It learns to attend to lower-level feature activations without requiring part annotations and uses these activations to update and rectify the output likelihood distribution. In contrast to other approaches, the proposed mechanism is modular, architecture-independent and efficient both in terms of parameters and computation required. Experiments show that networks augmented with our approach systematically improve their classification accuracy and become more robust to clutter. As a result, Wide Residual Networks augmented with our proposal surpasses the state of the art classification accuracies in CIFAR-10, the Adience gender recognition task, Stanford dogs, and UEC Food-100.
Beyond One-hot Encoding: lower dimensional target embedding
Jun 28, 2018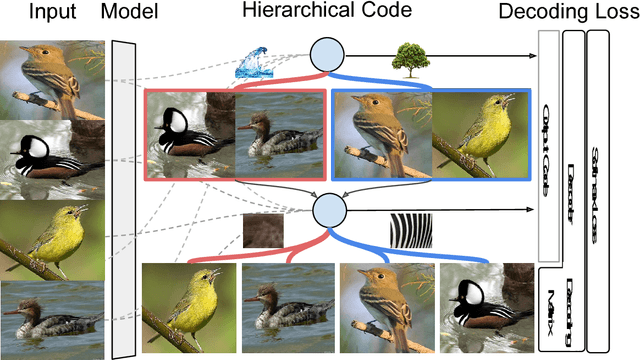
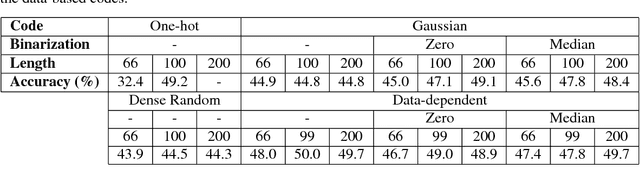
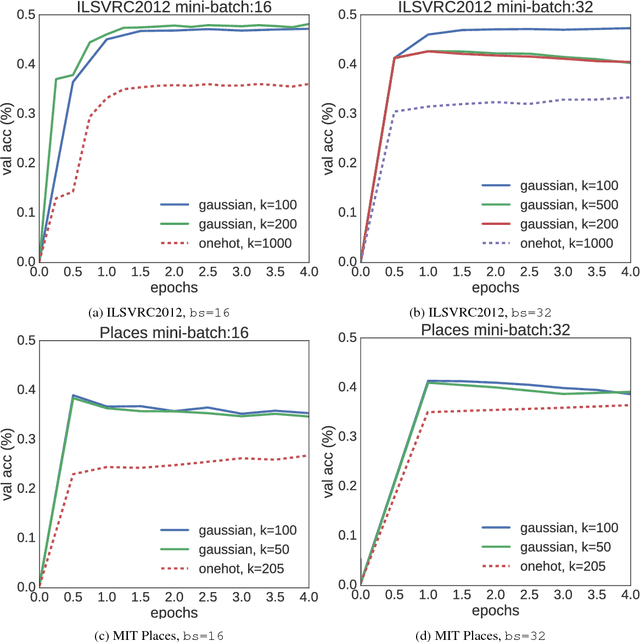
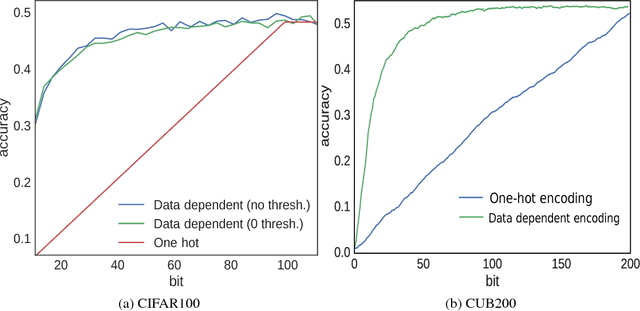
Target encoding plays a central role when learning Convolutional Neural Networks. In this realm, One-hot encoding is the most prevalent strategy due to its simplicity. However, this so widespread encoding schema assumes a flat label space, thus ignoring rich relationships existing among labels that can be exploited during training. In large-scale datasets, data does not span the full label space, but instead lies in a low-dimensional output manifold. Following this observation, we embed the targets into a low-dimensional space, drastically improving convergence speed while preserving accuracy. Our contribution is two fold: (i) We show that random projections of the label space are a valid tool to find such lower dimensional embeddings, boosting dramatically convergence rates at zero computational cost; and (ii) we propose a normalized eigenrepresentation of the class manifold that encodes the targets with minimal information loss, improving the accuracy of random projections encoding while enjoying the same convergence rates. Experiments on CIFAR-100, CUB200-2011, Imagenet, and MIT Places demonstrate that the proposed approach drastically improves convergence speed while reaching very competitive accuracy rates.
Deep Inference of Personality Traits by Integrating Image and Word Use in Social Networks
Feb 06, 2018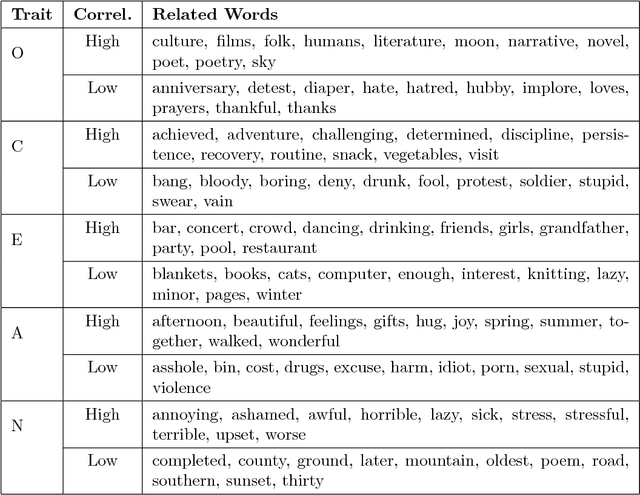
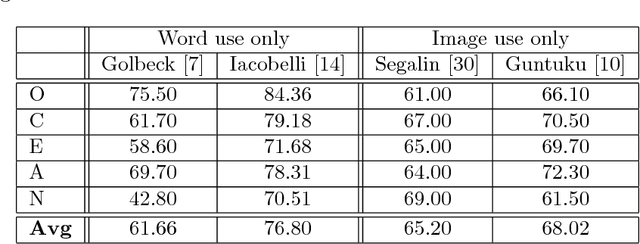
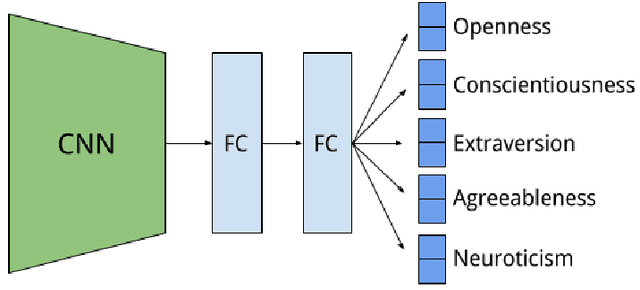
Social media, as a major platform for communication and information exchange, is a rich repository of the opinions and sentiments of 2.3 billion users about a vast spectrum of topics. To sense the whys of certain social user's demands and cultural-driven interests, however, the knowledge embedded in the 1.8 billion pictures which are uploaded daily in public profiles has just started to be exploited since this process has been typically been text-based. Following this trend on visual-based social analysis, we present a novel methodology based on Deep Learning to build a combined image-and-text based personality trait model, trained with images posted together with words found highly correlated to specific personality traits. So the key contribution here is to explore whether OCEAN personality trait modeling can be addressed based on images, here called \emph{Mind{P}ics}, appearing with certain tags with psychological insights. We found that there is a correlation between those posted images and their accompanying texts, which can be successfully modeled using deep neural networks for personality estimation. The experimental results are consistent with previous cyber-psychology results based on texts or images. In addition, classification results on some traits show that some patterns emerge in the set of images corresponding to a specific text, in essence to those representing an abstract concept. These results open new avenues of research for further refining the proposed personality model under the supervision of psychology experts.
Regularizing CNNs with Locally Constrained Decorrelations
Mar 15, 2017
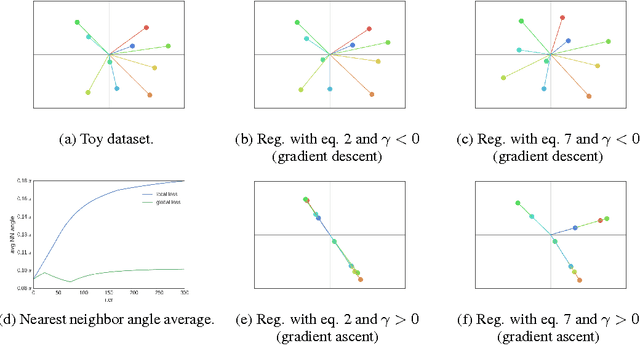

Regularization is key for deep learning since it allows training more complex models while keeping lower levels of overfitting. However, the most prevalent regularizations do not leverage all the capacity of the models since they rely on reducing the effective number of parameters. Feature decorrelation is an alternative for using the full capacity of the models but the overfitting reduction margins are too narrow given the overhead it introduces. In this paper, we show that regularizing negatively correlated features is an obstacle for effective decorrelation and present OrthoReg, a novel regularization technique that locally enforces feature orthogonality. As a result, imposing locality constraints in feature decorrelation removes interferences between negatively correlated feature weights, allowing the regularizer to reach higher decorrelation bounds, and reducing the overfitting more effectively. In particular, we show that the models regularized with OrthoReg have higher accuracy bounds even when batch normalization and dropout are present. Moreover, since our regularization is directly performed on the weights, it is especially suitable for fully convolutional neural networks, where the weight space is constant compared to the feature map space. As a result, we are able to reduce the overfitting of state-of-the-art CNNs on CIFAR-10, CIFAR-100, and SVHN.