 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Discriminators for Content-Consistent Unpaired Image-to-Image Translation
Sep 22, 2023A common goal of unpaired image-to-image translation is to preserve content consistency between source images and translated images while mimicking the style of the target domain. Due to biases between the datasets of both domains, many methods suffer from inconsistencies caused by the translation process. Most approaches introduced to mitigate these inconsistencies do not constrain the discriminator, leading to an even more ill-posed training setup. Moreover, none of these approaches is designed for larger crop sizes. In this work, we show that masking the inputs of a global discriminator for both domains with a content-based mask is sufficient to reduce content inconsistencies significantly. However, this strategy leads to artifacts that can be traced back to the masking process. To reduce these artifacts, we introduce a local discriminator that operates on pairs of small crops selected with a similarity sampling strategy. Furthermore, we apply this sampling strategy to sample global input crops from the source and target dataset. In addition, we propose feature-attentive denormalization to selectively incorporate content-based statistics into the generator stream. In our experiments, we show that our method achieves state-of-the-art performance in photorealistic sim-to-real translation and weather translation and also performs well in day-to-night translation. Additionally, we propose the cKVD metric, which builds on the sKVD metric and enables the examination of translation quality at the class or category level.
Don't miss the Mismatch: Investigating the Objective Function Mismatch for Unsupervised Representation Learning
Sep 04, 2020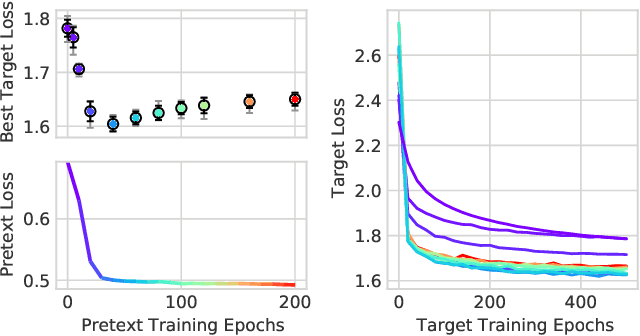
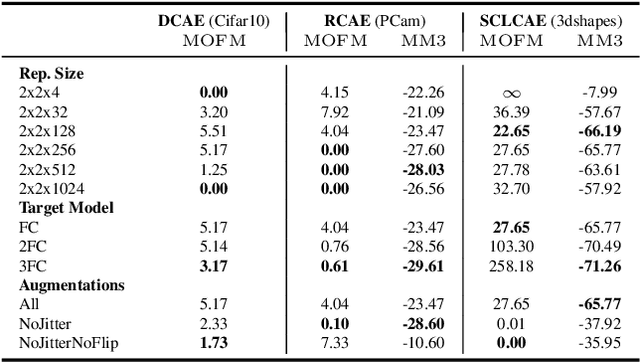
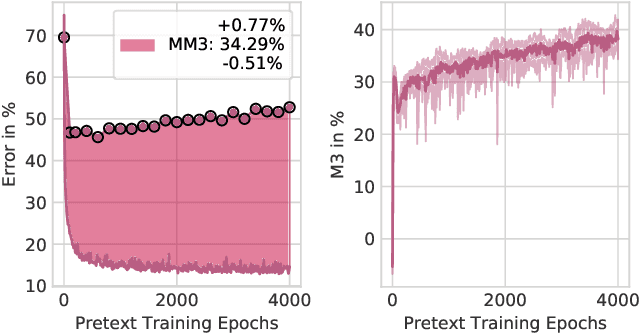
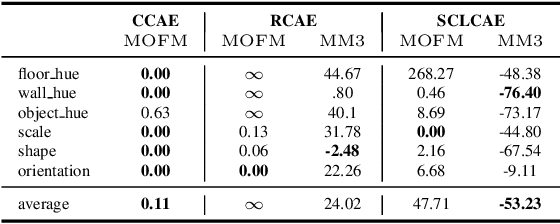
Finding general evaluation metrics for unsupervised representation learning techniques is a challenging open research question, which recently has become more and more necessary due to the increasing interest in unsupervised methods. Even though these methods promise beneficial representation characteristics, most approaches currently suffer from the objective function mismatch. This mismatch states that the performance on a desired target task can decrease when the unsupervised pretext task is learned too long - especially when both tasks are ill-posed. In this work, we build upon the widely used linear evaluation protocol and define new general evaluation metrics to quantitatively capture the objective function mismatch and the more generic metrics mismatch. We discuss the usability and stability of our protocols on a variety of pretext and target tasks and study mismatches in a wide range of experiments. Thereby we disclose dependencies of the objective function mismatch across several pretext and target tasks with respect to the pretext model's representation size, target model complexity, pretext and target augmentations as well as pretext and target task types.
CSNNs: Unsupervised, Backpropagation-free Convolutional Neural Networks for Representation Learning
Jan 29, 2020



This work combines Convolutional Neural Networks (CNNs), clustering via Self-Organizing Maps (SOMs) and Hebbian Learning to propose the building blocks of Convolutional Self-Organizing Neural Networks (CSNNs), which learn representations in an unsupervised and Backpropagation-free manner. Our approach replaces the learning of traditional convolutional layers from CNNs with the competitive learning procedure of SOMs and simultaneously learns local masks between those layers with separate Hebbian-like learning rules to overcome the problem of disentangling factors of variation when filters are learned through clustering. We investigate the learned representation by designing two simple models with our building blocks, achieving comparable performance to many methods which use Backpropagation, while we reach comparable performance on Cifar10 and give baseline performances on Cifar100, Tiny ImageNet and a small subset of ImageNet for Backpropagation-free methods.