 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't miss the Mismatch: Investigating the Objective Function Mismatch for Unsupervised Representation Learning
Paper and Code
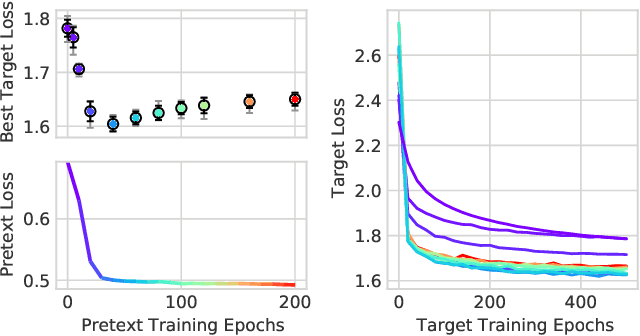
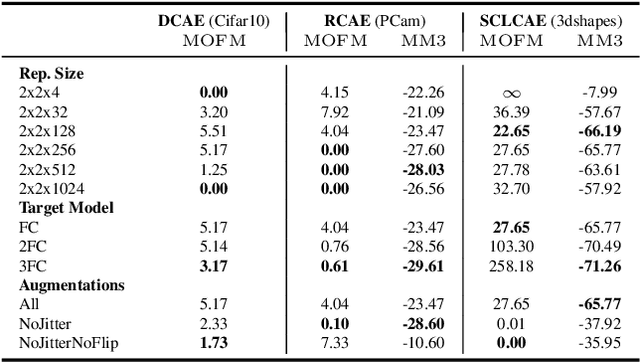
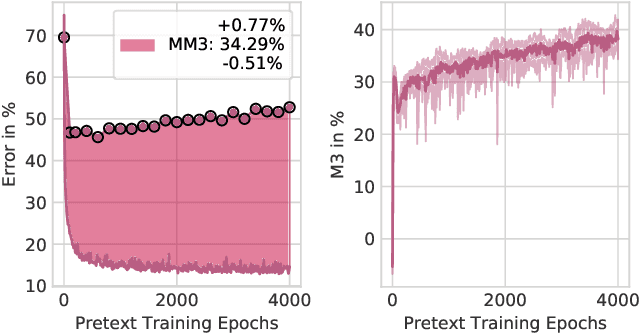
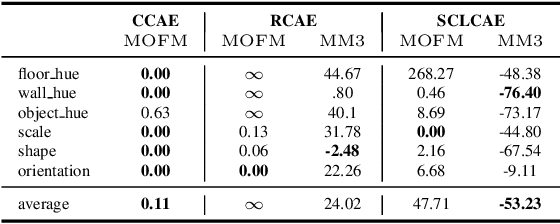
Finding general evaluation metrics for unsupervised representation learning techniques is a challenging open research question, which recently has become more and more necessary due to the increasing interest in unsupervised methods. Even though these methods promise beneficial representation characteristics, most approaches currently suffer from the objective function mismatch. This mismatch states that the performance on a desired target task can decrease when the unsupervised pretext task is learned too long - especially when both tasks are ill-posed. In this work, we build upon the widely used linear evaluation protocol and define new general evaluation metrics to quantitatively capture the objective function mismatch and the more generic metrics mismatch. We discuss the usability and stability of our protocols on a variety of pretext and target tasks and study mismatches in a wide range of experiments. Thereby we disclose dependencies of the objective function mismatch across several pretext and target tasks with respect to the pretext model's representation size, target model complexity, pretext and target augmentations as well as pretext and target task types.