 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo
Mar 12, 2025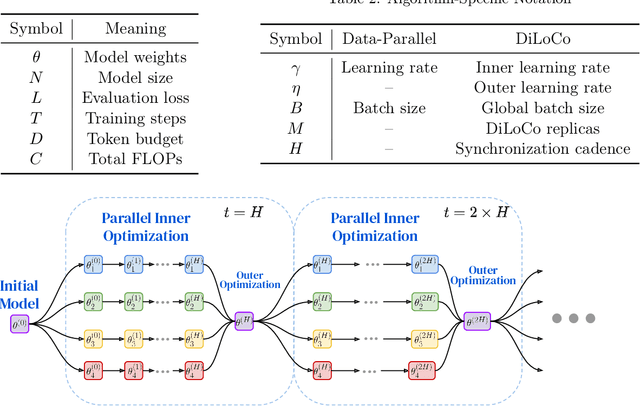
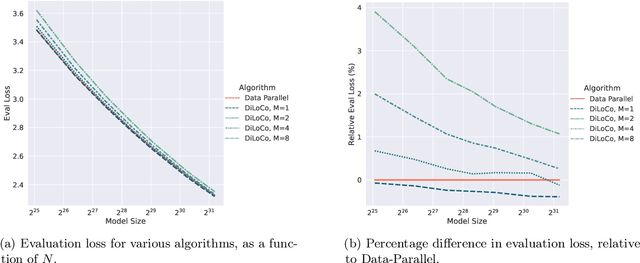
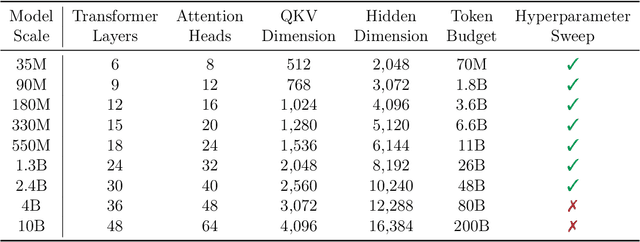
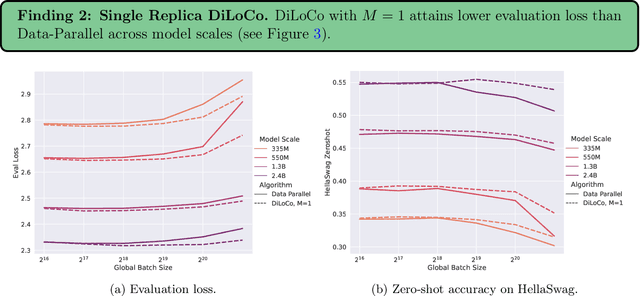
As we scale to more massive machine learning models, the frequent synchronization demands inherent in data-parallel approaches create significant slowdowns, posing a critical challenge to further scaling. Recent work develops an approach (DiLoCo) that relaxes synchronization demands without compromising model quality. However, these works do not carefully analyze how DiLoCo's behavior changes with model size. In this work, we study the scaling law behavior of DiLoCo when training LLMs under a fixed compute budget. We focus on how algorithmic factors, including number of model replicas, hyperparameters, and token budget affect training in ways that can be accurately predicted via scaling laws. We find that DiLoCo scales both predictably and robustly with model size. When well-tuned, DiLoCo scales better than data-parallel training with model size, and can outperform data-parallel training even at small model sizes. Our results showcase a more general set of benefits of DiLoCo than previously documented, including increased optimal batch sizes, improved downstream generalization with scale, and improved evaluation loss for a fixed token budget.
Eager Updates For Overlapped Communication and Computation in DiLoCo
Feb 18, 2025
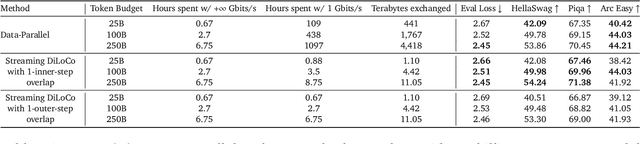
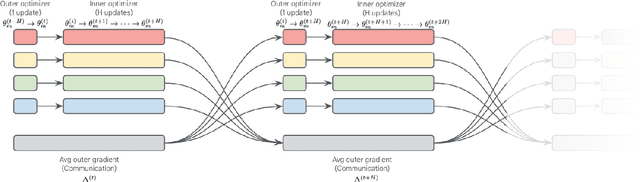
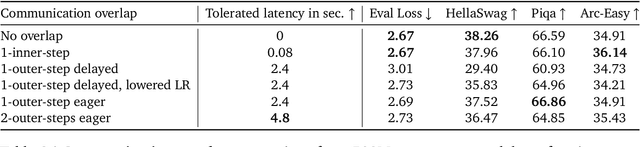
Distributed optimization methods such as DiLoCo have been shown to be effective in training very large models across multiple distributed workers, such as datacenters. These methods split updates into two parts: an inner optimization phase, where the workers independently execute multiple optimization steps on their own local data, and an outer optimization step, where the inner updates are synchronized. While such approaches require orders of magnitude less communication than standard data-parallel training, in settings where the workers are datacenters, even the limited communication requirements of these approaches can still cause significant slow downs due to the blocking necessary at each outer optimization step. In this paper, we investigate techniques to mitigate this issue by overlapping communication with computation in a manner that allows the outer optimization step to fully overlap with the inner optimization phase. We show that a particular variant, dubbed eager updates, provides competitive performance with standard DiLoCo in settings with low bandwidth between workers.
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
Jan 30, 2025Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.
WARP: On the Benefits of Weight Averaged Rewarded Policies
Jun 24, 2024



Reinforcement learning from human feedback (RLHF) aligns large language models (LLMs) by encouraging their generations to have high rewards, using a reward model trained on human preferences. To prevent the forgetting of pre-trained knowledge, RLHF usually incorporates a KL regularization; this forces the policy to remain close to its supervised fine-tuned initialization, though it hinders the reward optimization. To tackle the trade-off between KL and reward, in this paper we introduce a novel alignment strategy named Weight Averaged Rewarded Policies (WARP). WARP merges policies in the weight space at three distinct stages. First, it uses the exponential moving average of the policy as a dynamic anchor in the KL regularization. Second, it applies spherical interpolation to merge independently fine-tuned policies into a new enhanced one. Third, it linearly interpolates between this merged model and the initialization, to recover features from pre-training. This procedure is then applied iteratively, with each iteration's final model used as an advanced initialization for the next, progressively refining the KL-reward Pareto front, achieving superior rewards at fixed KL. Experiments with GEMMA policies validate that WARP improves their quality and alignment, outperforming other open-source LLMs.
A Mechanism-Based Approach to Mitigating Harms from Persuasive Generative AI
Apr 23, 2024



Recent generative AI systems have demonstrated more advanced persuasive capabilities and are increasingly permeating areas of life where they can influence decision-making. Generative AI presents a new risk profile of persuasion due the opportunity for reciprocal exchange and prolonged interactions. This has led to growing concerns about harms from AI persuasion and how they can be mitigated, highlighting the need for a systematic study of AI persuasion. The current definitions of AI persuasion are unclear and related harms are insufficiently studied. Existing harm mitigation approaches prioritise harms from the outcome of persuasion over harms from the process of persuasion. In this paper, we lay the groundwork for the systematic study of AI persuasion. We first put forward definitions of persuasive generative AI. We distinguish between rationally persuasive generative AI, which relies on providing relevant facts, sound reasoning, or other forms of trustworthy evidence, and manipulative generative AI, which relies on taking advantage of cognitive biases and heuristics or misrepresenting information. We also put forward a map of harms from AI persuasion, including definitions and examples of economic, physical, environmental, psychological, sociocultural, political, privacy, and autonomy harm. We then introduce a map of mechanisms that contribute to harmful persuasion. Lastly, we provide an overview of approaches that can be used to mitigate against process harms of persuasion, including prompt engineering for manipulation classification and red teaming. Future work will operationalise these mitigations and study the interaction between different types of mechanisms of persuasion.
DiPaCo: Distributed Path Composition
Mar 15, 2024Progress in machine learning (ML) has been fueled by scaling neural network models. This scaling has been enabled by ever more heroic feats of engineering, necessary for accommodating ML approaches that require high bandwidth communication between devices working in parallel. In this work, we propose a co-designed modular architecture and training approach for ML models, dubbed DIstributed PAth COmposition (DiPaCo). During training, DiPaCo distributes computation by paths through a set of shared modules. Together with a Local-SGD inspired optimization (DiLoCo) that keeps modules in sync with drastically reduced communication, Our approach facilitates training across poorly connected and heterogeneous workers, with a design that ensures robustness to worker failures and preemptions. At inference time, only a single path needs to be executed for each input, without the need for any model compression. We consider this approach as a first prototype towards a new paradigm of large-scale learning, one that is less synchronous and more modular. Our experiments on the widely used C4 benchmark show that, for the same amount of training steps but less wall-clock time, DiPaCo exceeds the performance of a 1 billion-parameter dense transformer language model by choosing one of 256 possible paths, each with a size of 150 million parameters.
Asynchronous Local-SGD Training for Language Modeling
Jan 17, 2024



Local stochastic gradient descent (Local-SGD), also referred to as federated averaging, is an approach to distributed optimization where each device performs more than one SGD update per communication. This work presents an empirical study of {\it asynchronous} Local-SGD for training language models; that is, each worker updates the global parameters as soon as it has finished its SGD steps. We conduct a comprehensive investigation by examining how worker hardware heterogeneity, model size, number of workers, and optimizer could impact the learning performance. We find that with naive implementations, asynchronous Local-SGD takes more iterations to converge than its synchronous counterpart despite updating the (global) model parameters more frequently. We identify momentum acceleration on the global parameters when worker gradients are stale as a key challenge. We propose a novel method that utilizes a delayed Nesterov momentum update and adjusts the workers' local training steps based on their computation speed. This approach, evaluated with models up to 150M parameters on the C4 dataset, matches the performance of synchronous Local-SGD in terms of perplexity per update step, and significantly surpasses it in terms of wall clock time.
DiLoCo: Distributed Low-Communication Training of Language Models
Nov 14, 2023



Large language models (LLM) have become a critical component in many applications of machine learning. However, standard approaches to training LLM require a large number of tightly interconnected accelerators, with devices exchanging gradients and other intermediate states at each optimization step. While it is difficult to build and maintain a single computing cluster hosting many accelerators, it might be easier to find several computing clusters each hosting a smaller number of devices. In this work, we propose a distributed optimization algorithm, Distributed Low-Communication (DiLoCo), that enables training of language models on islands of devices that are poorly connected. The approach is a variant of federated averaging, where the number of inner steps is large, the inner optimizer is AdamW, and the outer optimizer is Nesterov momentum. On the widely used C4 dataset, we show that DiLoCo on 8 workers performs as well as fully synchronous optimization while communicating 500 times less. DiLoCo exhibits great robustness to the data distribution of each worker. It is also robust to resources becoming unavailable over time, and vice versa, it can seamlessly leverage resources that become available during training.
Towards Compute-Optimal Transfer Learning
Apr 25, 2023



The field of transfer learning is undergoing a significant shift with the introduction of large pretrained models which have demonstrated strong adaptability to a variety of downstream tasks. However, the high computational and memory requirements to finetune or use these models can be a hindrance to their widespread use. In this study, we present a solution to this issue by proposing a simple yet effective way to trade computational efficiency for asymptotic performance which we define as the performance a learning algorithm achieves as compute tends to infinity. Specifically, we argue that zero-shot structured pruning of pretrained models allows them to increase compute efficiency with minimal reduction in performance. We evaluate our method on the Nevis'22 continual learning benchmark that offers a diverse set of transfer scenarios. Our results show that pruning convolutional filters of pretrained models can lead to more than 20% performance improvement in low computational regimes.
CoMFormer: Continual Learning in Semantic and Panoptic Segmentation
Nov 25, 2022Continual learning for segmentation has recently seen increasing interest. However, all previous works focus on narrow semantic segmentation and disregard panoptic segmentation, an important task with real-world impacts. %a In this paper, we present the first continual learning model capable of operating on both semantic and panoptic segmentation. Inspired by recent transformer approaches that consider segmentation as a mask-classification problem, we design CoMFormer. Our method carefully exploits the properties of transformer architectures to learn new classes over time. Specifically, we propose a novel adaptive distillation loss along with a mask-based pseudo-labeling technique to effectively prevent forgetting. To evaluate our approach, we introduce a novel continual panoptic segmentation benchmark on the challenging ADE20K dataset. Our CoMFormer outperforms all the existing baselines by forgetting less old classes but also learning more effectively new classes. In addition, we also report an extensive evaluation in the large-scale continual semantic segmentation scenario showing that CoMFormer also significantly outperforms state-of-the-art methods.