 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiPaCo: Distributed Path Composition
Mar 15, 2024Progress in machine learning (ML) has been fueled by scaling neural network models. This scaling has been enabled by ever more heroic feats of engineering, necessary for accommodating ML approaches that require high bandwidth communication between devices working in parallel. In this work, we propose a co-designed modular architecture and training approach for ML models, dubbed DIstributed PAth COmposition (DiPaCo). During training, DiPaCo distributes computation by paths through a set of shared modules. Together with a Local-SGD inspired optimization (DiLoCo) that keeps modules in sync with drastically reduced communication, Our approach facilitates training across poorly connected and heterogeneous workers, with a design that ensures robustness to worker failures and preemptions. At inference time, only a single path needs to be executed for each input, without the need for any model compression. We consider this approach as a first prototype towards a new paradigm of large-scale learning, one that is less synchronous and more modular. Our experiments on the widely used C4 benchmark show that, for the same amount of training steps but less wall-clock time, DiPaCo exceeds the performance of a 1 billion-parameter dense transformer language model by choosing one of 256 possible paths, each with a size of 150 million parameters.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022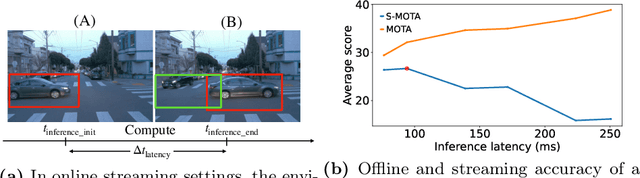
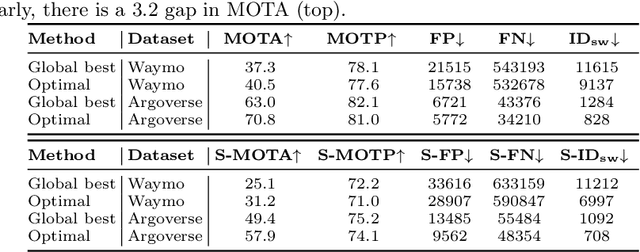
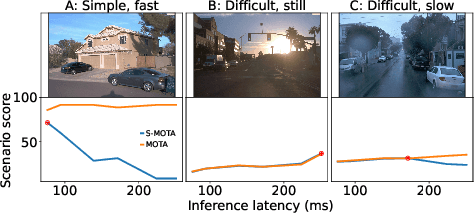
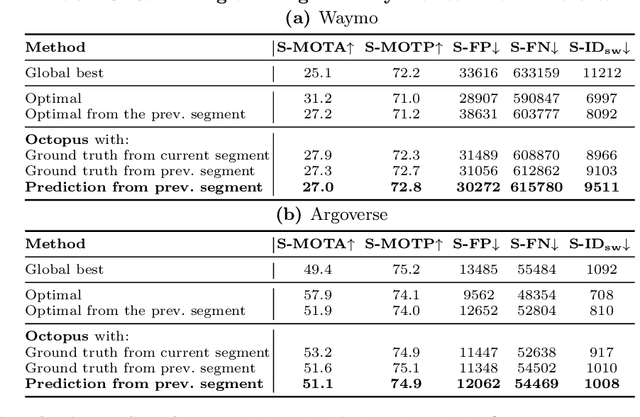
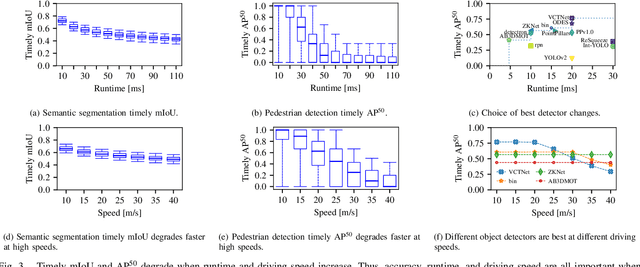
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Pylot: A Modular Platform for Exploring Latency-Accuracy Tradeoffs in Autonomous Vehicles
Apr 16, 2021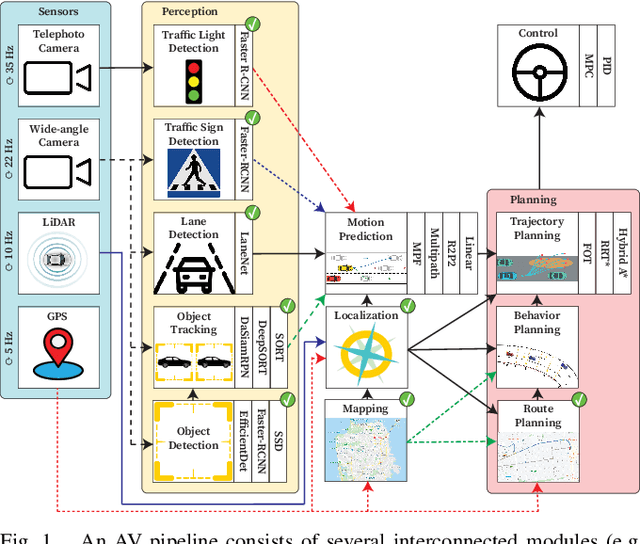

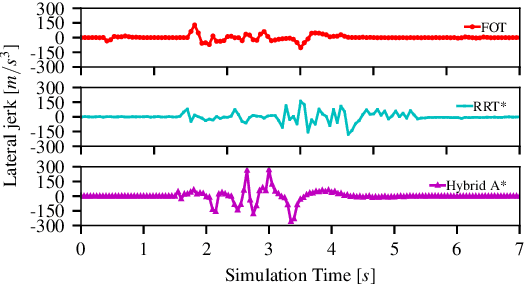
We present Pylot, a platform for autonomous vehicle (AV) research and development, built with the goal to allow researchers to study the effects of the latency and accuracy of their models and algorithms on the end-to-end driving behavior of an AV. This is achieved through a modular structure enabled by our high-performance dataflow system that represents AV software pipeline components (object detectors, motion planners, etc.) as a dataflow graph of operators which communicate on data streams using timestamped messages. Pylot readily interfaces with popular AV simulators like CARLA, and is easily deployable to real-world vehicles with minimal code changes. To reduce the burden of developing an entire pipeline for evaluating a single component, Pylot provides several state-of-the-art reference implementations for the various components of an AV pipeline. Using these reference implementations, a Pylot-based AV pipeline is able to drive a real vehicle, and attains a high score on the CARLA Autonomous Driving Challenge. We also present several case studies enabled by Pylot, including evidence of a need for context-dependent components, and per-component time allocation. Pylot is open source, with the code available at https://github.com/erdos-project/pylot.
BEV-Seg: Bird's Eye View Semantic Segmentation Using Geometry and Semantic Point Cloud
Jun 23, 2020
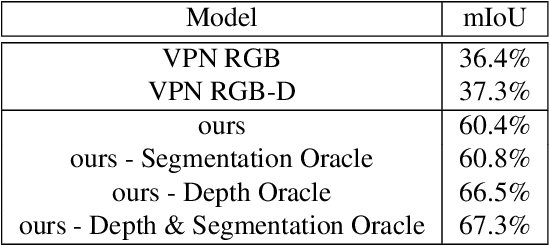
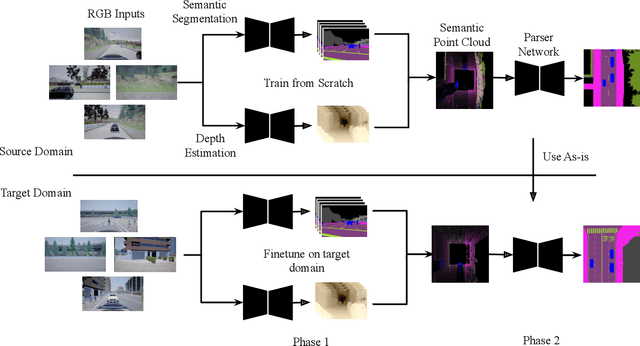

Bird's-eye-view (BEV) is a powerful and widely adopted representation for road scenes that captures surrounding objects and their spatial locations, along with overall context in the scene. In this work, we focus on bird's eye semantic segmentation, a task that predicts pixel-wise semantic segmentation in BEV from side RGB images. This task is made possible by simulators such as Carla, which allow for cheap data collection, arbitrary camera placements, and supervision in ways otherwise not possible in the real world. There are two main challenges to this task: the view transformation from side view to bird's eye view, as well as transfer learning to unseen domains. Existing work transforms between views through fully connected layers and transfer learns via GANs. This suffers from a lack of depth reasoning and performance degradation across domains. Our novel 2-staged perception pipeline explicitly predicts pixel depths and combines them with pixel semantics in an efficient manner, allowing the model to leverage depth information to infer objects' spatial locations in the BEV. In addition, we transfer learning by abstracting high-level geometric features and predicting an intermediate representation that is common across different domains. We publish a new dataset called BEVSEG-Carla and show that our approach improves state-of-the-art by 24% mIoU and performs well when transferred to a new domain.