 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEV-Seg: Bird's Eye View Semantic Segmentation Using Geometry and Semantic Point Cloud
Jun 23, 2020
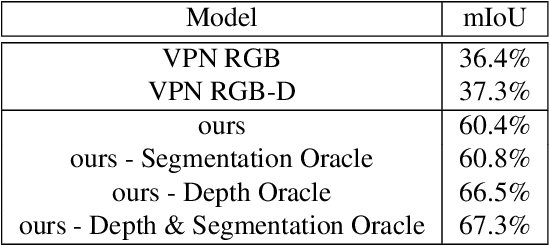
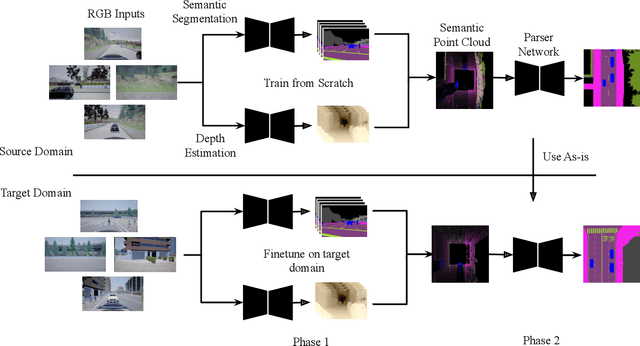

Bird's-eye-view (BEV) is a powerful and widely adopted representation for road scenes that captures surrounding objects and their spatial locations, along with overall context in the scene. In this work, we focus on bird's eye semantic segmentation, a task that predicts pixel-wise semantic segmentation in BEV from side RGB images. This task is made possible by simulators such as Carla, which allow for cheap data collection, arbitrary camera placements, and supervision in ways otherwise not possible in the real world. There are two main challenges to this task: the view transformation from side view to bird's eye view, as well as transfer learning to unseen domains. Existing work transforms between views through fully connected layers and transfer learns via GANs. This suffers from a lack of depth reasoning and performance degradation across domains. Our novel 2-staged perception pipeline explicitly predicts pixel depths and combines them with pixel semantics in an efficient manner, allowing the model to leverage depth information to infer objects' spatial locations in the BEV. In addition, we transfer learning by abstracting high-level geometric features and predicting an intermediate representation that is common across different domains. We publish a new dataset called BEVSEG-Carla and show that our approach improves state-of-the-art by 24% mIoU and performs well when transferred to a new domain.