 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Long-Range Context for Graph Neural Networks with Global Attention
Jan 21, 2022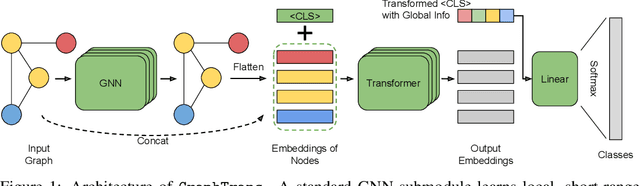
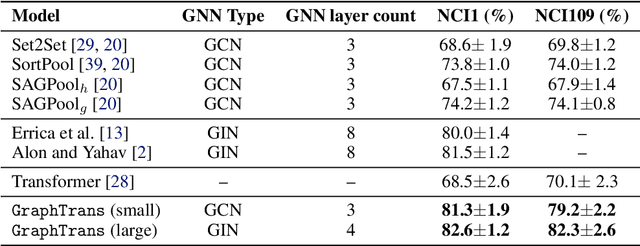
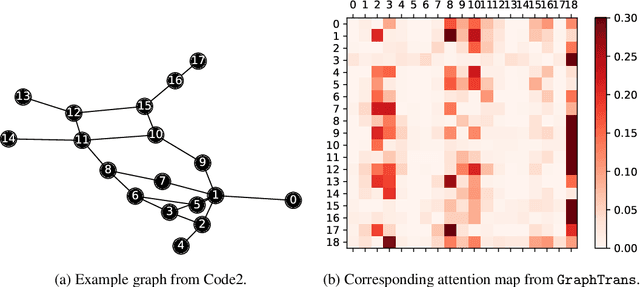
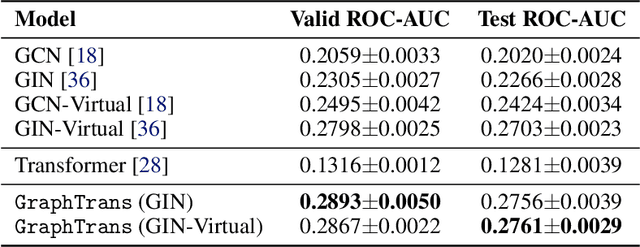
Graph neural networks are powerful architectures for structured datasets. However, current methods struggle to represent long-range dependencies. Scaling the depth or width of GNNs is insufficient to broaden receptive fields as larger GNNs encounter optimization instabilities such as vanishing gradients and representation oversmoothing, while pooling-based approaches have yet to become as universally useful as in computer vision. In this work, we propose the use of Transformer-based self-attention to learn long-range pairwise relationships, with a novel "readout" mechanism to obtain a global graph embedding. Inspired by recent computer vision results that find position-invariant attention performant in learning long-range relationships, our method, which we call GraphTrans, applies a permutation-invariant Transformer module after a standard GNN module. This simple architecture leads to state-of-the-art results on several graph classification tasks, outperforming methods that explicitly encode graph structure. Our results suggest that purely-learning-based approaches without graph structure may be suitable for learning high-level, long-range relationships on graphs. Code for GraphTrans is available at https://github.com/ucbrise/graphtrans.
Transformers are Deep Infinite-Dimensional Non-Mercer Binary Kernel Machines
Jun 02, 2021

Despite their ubiquity in core AI fields like natural language processing, the mechanics of deep attention-based neural networks like the Transformer model are not fully understood. In this article, we present a new perspective towards understanding how Transformers work. In particular, we show that the "dot-product attention" that is the core of the Transformer's operation can be characterized as a kernel learning method on a pair of Banach spaces. In particular, the Transformer's kernel is characterized as having an infinite feature dimension. Along the way we consider an extension of the standard kernel learning problem to a binary setting, where data come from two input domains and a response is defined for every cross-domain pair. We prove a new representer theorem for these binary kernel machines with non-Mercer (indefinite, asymmetric) kernels (implying that the functions learned are elements of reproducing kernel Banach spaces rather than Hilbert spaces), and also prove a new universal approximation theorem showing that the Transformer calculation can learn any binary non-Mercer reproducing kernel Banach space pair. We experiment with new kernels in Transformers, and obtain results that suggest the infinite dimensionality of the standard Transformer kernel is partially responsible for its performance. This paper's results provide a new theoretical understanding of a very important but poorly understood model in modern machine~learning.
Contingencies from Observations: Tractable Contingency Planning with Learned Behavior Models
Apr 21, 2021



Humans have a remarkable ability to make decisions by accurately reasoning about future events, including the future behaviors and states of mind of other agents. Consider driving a car through a busy intersection: it is necessary to reason about the physics of the vehicle, the intentions of other drivers, and their beliefs about your own intentions. If you signal a turn, another driver might yield to you, or if you enter the passing lane, another driver might decelerate to give you room to merge in front. Competent drivers must plan how they can safely react to a variety of potential future behaviors of other agents before they make their next move. This requires contingency planning: explicitly planning a set of conditional actions that depend on the stochastic outcome of future events. In this work, we develop a general-purpose contingency planner that is learned end-to-end using high-dimensional scene observations and low-dimensional behavioral observations. We use a conditional autoregressive flow model to create a compact contingency planning space, and show how this model can tractably learn contingencies from behavioral observations. We developed a closed-loop control benchmark of realistic multi-agent scenarios in a driving simulator (CARLA), on which we compare our method to various noncontingent methods that reason about multi-agent future behavior, including several state-of-the-art deep learning-based planning approaches. We illustrate that these noncontingent planning methods fundamentally fail on this benchmark, and find that our deep contingency planning method achieves significantly superior performance. Code to run our benchmark and reproduce our results is available at https://sites.google.com/view/contingency-planning
Pylot: A Modular Platform for Exploring Latency-Accuracy Tradeoffs in Autonomous Vehicles
Apr 16, 2021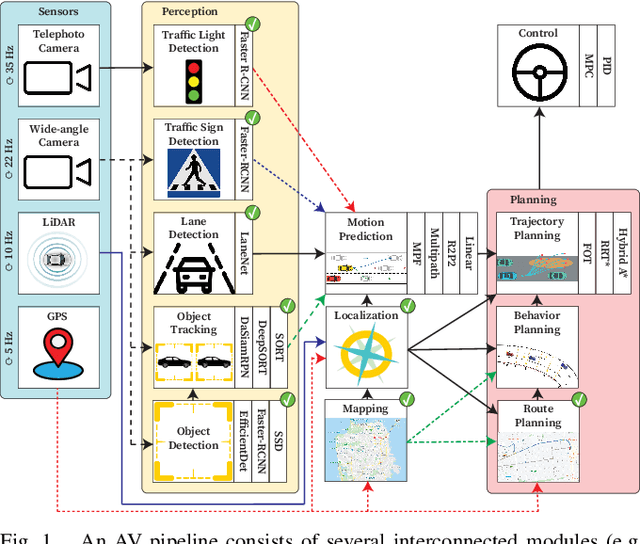

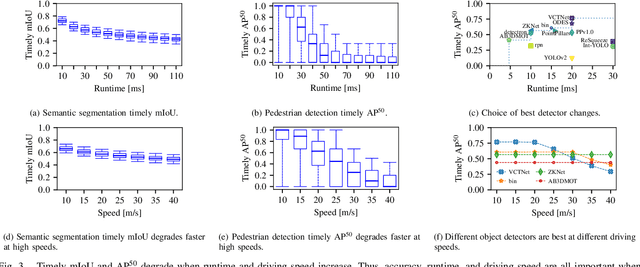
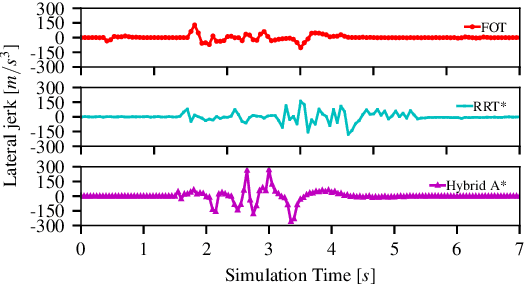
We present Pylot, a platform for autonomous vehicle (AV) research and development, built with the goal to allow researchers to study the effects of the latency and accuracy of their models and algorithms on the end-to-end driving behavior of an AV. This is achieved through a modular structure enabled by our high-performance dataflow system that represents AV software pipeline components (object detectors, motion planners, etc.) as a dataflow graph of operators which communicate on data streams using timestamped messages. Pylot readily interfaces with popular AV simulators like CARLA, and is easily deployable to real-world vehicles with minimal code changes. To reduce the burden of developing an entire pipeline for evaluating a single component, Pylot provides several state-of-the-art reference implementations for the various components of an AV pipeline. Using these reference implementations, a Pylot-based AV pipeline is able to drive a real vehicle, and attains a high score on the CARLA Autonomous Driving Challenge. We also present several case studies enabled by Pylot, including evidence of a need for context-dependent components, and per-component time allocation. Pylot is open source, with the code available at https://github.com/erdos-project/pylot.
Attentional Policies for Cross-Context Multi-Agent Reinforcement Learning
May 31, 2019

Many potential applications of reinforcement learning in the real world involve interacting with other agents whose numbers vary over time. We propose new neural policy architectures for these multi-agent problems. In contrast to other methods of training an individual, discrete policy for each agent and then enforcing cooperation through some additional inter-policy mechanism, we follow the spirit of recent work on the power of relational inductive biases in deep networks by learning multi-agent relationships at the policy level via an attentional architecture. In our method, all agents share the same policy, but independently apply it in their own context to aggregate the other agents' state information when selecting their next action. The structure of our architectures allow them to be applied on environments with varying numbers of agents. We demonstrate our architecture on a benchmark multi-agent autonomous vehicle coordination problem, obtaining superior results to a full-knowledge, fully-centralized reference solution, and significantly outperforming it when scaling to large numbers of agents.
Neural-Attention-Based Deep Learning Architectures for Modeling Traffic Dynamics on Lane Graphs
Apr 23, 2019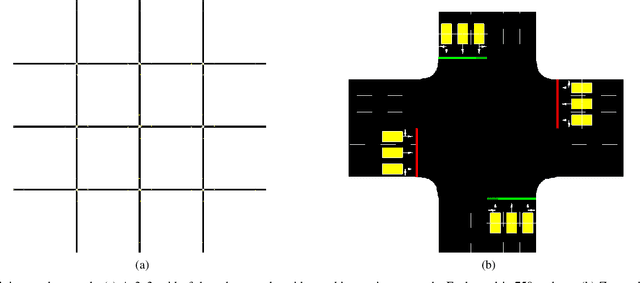
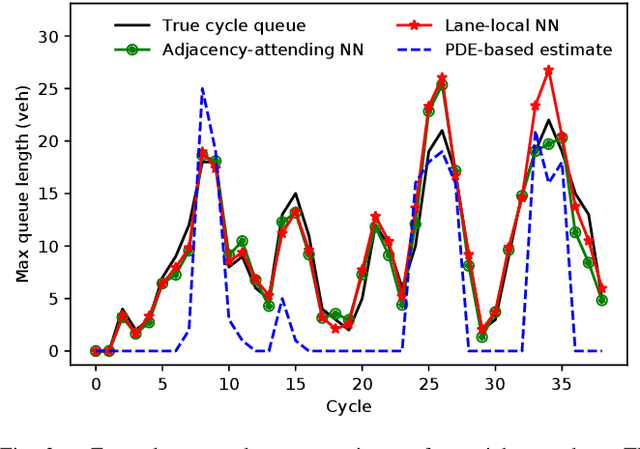

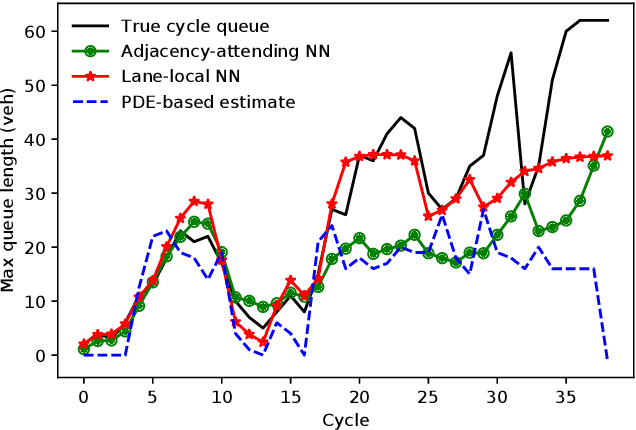
Deep neural networks can be powerful tools, but require careful application-specific design to ensure that the most informative relationships in the data are learnable. In this paper, we apply deep neural networks to the nonlinear spatiotemporal physics problem of vehicle traffic dynamics. We consider problems of estimating macroscopic quantities (e.g., the queue at an intersection) at a lane level. First-principles modeling at the lane scale has been a challenge due to complexities in modeling social behaviors like lane changes, and those behaviors' resultant macro-scale effects. Following domain knowledge that upstream/downstream lanes and neighboring lanes affect each others' traffic flows in distinct ways, we apply a form of neural attention that allows the neural network layers to aggregate information from different lanes in different manners. Using a microscopic traffic simulator as a testbed, we obtain results showing that an attentional neural network model can use information from nearby lanes to improve predictions, and, that explicitly encoding the lane-to-lane relationship types significantly improves performance. We also demonstrate the transfer of our learned neural network to a more complex road network, discuss how its performance degradation may be attributable to new traffic behaviors induced by increased topological complexity, and motivate learning dynamics models from many road network topologies.