 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo
Mar 12, 2025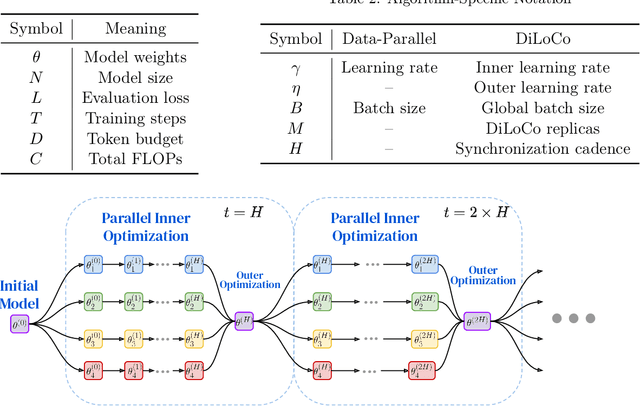
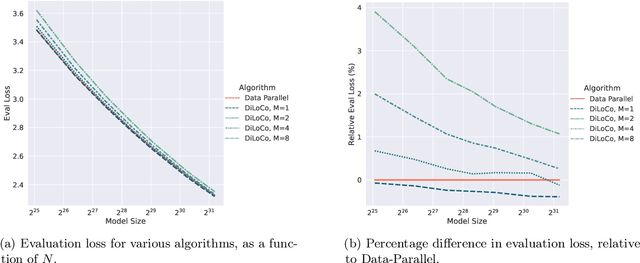
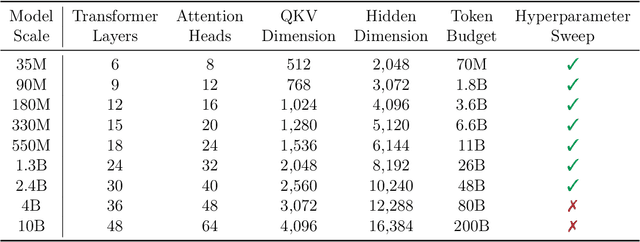
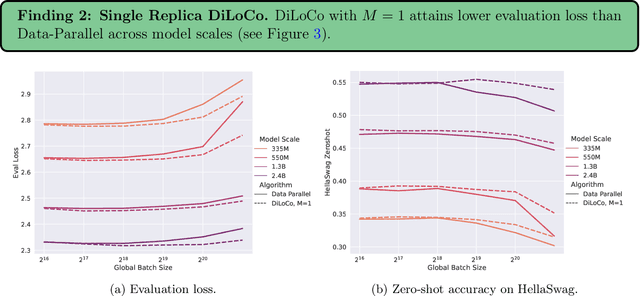
As we scale to more massive machine learning models, the frequent synchronization demands inherent in data-parallel approaches create significant slowdowns, posing a critical challenge to further scaling. Recent work develops an approach (DiLoCo) that relaxes synchronization demands without compromising model quality. However, these works do not carefully analyze how DiLoCo's behavior changes with model size. In this work, we study the scaling law behavior of DiLoCo when training LLMs under a fixed compute budget. We focus on how algorithmic factors, including number of model replicas, hyperparameters, and token budget affect training in ways that can be accurately predicted via scaling laws. We find that DiLoCo scales both predictably and robustly with model size. When well-tuned, DiLoCo scales better than data-parallel training with model size, and can outperform data-parallel training even at small model sizes. Our results showcase a more general set of benefits of DiLoCo than previously documented, including increased optimal batch sizes, improved downstream generalization with scale, and improved evaluation loss for a fixed token budget.
Confidential Federated Computations
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.