 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing and Adapting Error Correction Data for Mobile Large Language Model Applications
May 24, 2025Error correction is an important capability when applying large language models (LLMs) to facilitate user typing on mobile devices. In this paper, we use LLMs to synthesize a high-quality dataset of error correction pairs to evaluate and improve LLMs for mobile applications. We first prompt LLMs with error correction domain knowledge to build a scalable and reliable addition to the existing data synthesis pipeline. We then adapt the synthetic data distribution to match the mobile application domain by reweighting the samples. The reweighting model is learnt by predicting (a handful of) live A/B test metrics when deploying LLMs in production, given the LLM performance on offline evaluation data and scores from a small privacy-preserving on-device language model. Finally, we present best practices for mixing our synthetic data with other data sources to improve model performance on error correction in both offline evaluation and production live A/B testing.
Trusted Machine Learning Models Unlock Private Inference for Problems Currently Infeasible with Cryptography
Jan 15, 2025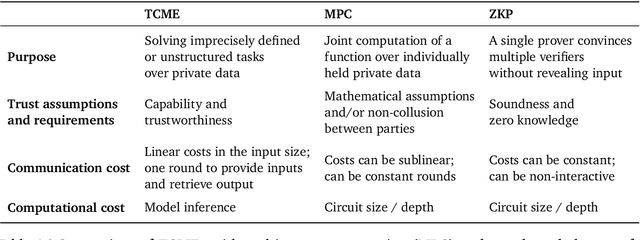
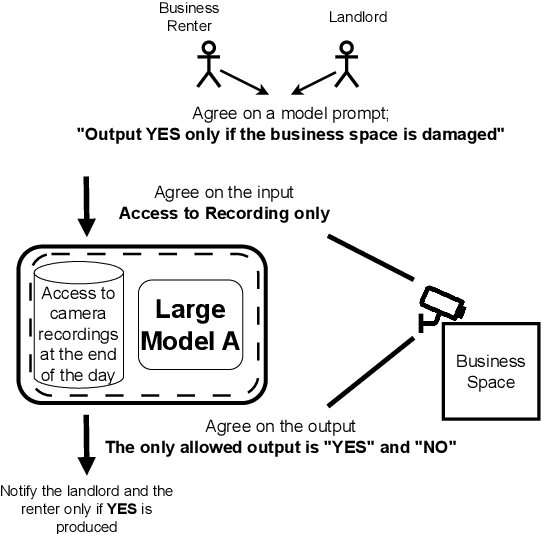
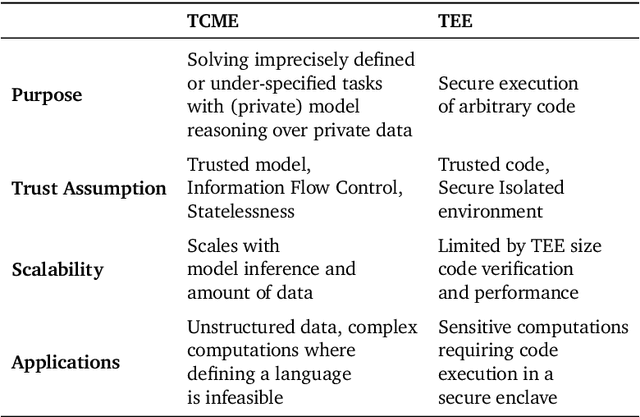
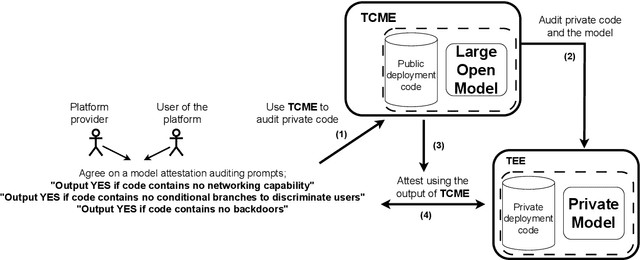
We often interact with untrusted parties. Prioritization of privacy can limit the effectiveness of these interactions, as achieving certain goals necessitates sharing private data. Traditionally, addressing this challenge has involved either seeking trusted intermediaries or constructing cryptographic protocols that restrict how much data is revealed, such as multi-party computations or zero-knowledge proofs. While significant advances have been made in scaling cryptographic approaches, they remain limited in terms of the size and complexity of applications they can be used for. In this paper, we argue that capable machine learning models can fulfill the role of a trusted third party, thus enabling secure computations for applications that were previously infeasible. In particular, we describe Trusted Capable Model Environments (TCMEs) as an alternative approach for scaling secure computation, where capable machine learning model(s) interact under input/output constraints, with explicit information flow control and explicit statelessness. This approach aims to achieve a balance between privacy and computational efficiency, enabling private inference where classical cryptographic solutions are currently infeasible. We describe a number of use cases that are enabled by TCME, and show that even some simple classic cryptographic problems can already be solved with TCME. Finally, we outline current limitations and discuss the path forward in implementing them.
Federated Learning in Practice: Reflections and Projections
Oct 11, 2024

Federated Learning (FL) is a machine learning technique that enables multiple entities to collaboratively learn a shared model without exchanging their local data. Over the past decade, FL systems have achieved substantial progress, scaling to millions of devices across various learning domains while offering meaningful differential privacy (DP) guarantees. Production systems from organizations like Google, Apple, and Meta demonstrate the real-world applicability of FL. However, key challenges remain, including verifying server-side DP guarantees and coordinating training across heterogeneous devices, limiting broader adoption. Additionally, emerging trends such as large (multi-modal) models and blurred lines between training, inference, and personalization challenge traditional FL frameworks. In response, we propose a redefined FL framework that prioritizes privacy principles rather than rigid definitions. We also chart a path forward by leveraging trusted execution environments and open-source ecosystems to address these challenges and facilitate future advancements in FL.
Air Gap: Protecting Privacy-Conscious Conversational Agents
May 08, 2024



The growing use of large language model (LLM)-based conversational agents to manage sensitive user data raises significant privacy concerns. While these agents excel at understanding and acting on context, this capability can be exploited by malicious actors. We introduce a novel threat model where adversarial third-party apps manipulate the context of interaction to trick LLM-based agents into revealing private information not relevant to the task at hand. Grounded in the framework of contextual integrity, we introduce AirGapAgent, a privacy-conscious agent designed to prevent unintended data leakage by restricting the agent's access to only the data necessary for a specific task. Extensive experiments using Gemini, GPT, and Mistral models as agents validate our approach's effectiveness in mitigating this form of context hijacking while maintaining core agent functionality. For example, we show that a single-query context hijacking attack on a Gemini Ultra agent reduces its ability to protect user data from 94% to 45%, while an AirGapAgent achieves 97% protection, rendering the same attack ineffective.
Confidential Federated Computations
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.
Prompt Public Large Language Models to Synthesize Data for Private On-device Applications
Apr 05, 2024



Pre-training on public data is an effective method to improve the performance for federated learning (FL) with differential privacy (DP). This paper investigates how large language models (LLMs) trained on public data can improve the quality of pre-training data for the on-device language models trained with DP and FL. We carefully design LLM prompts to filter and transform existing public data, and generate new data to resemble the real user data distribution. The model pre-trained on our synthetic dataset achieves relative improvement of 19.0% and 22.8% in next word prediction accuracy compared to the baseline model pre-trained on a standard public dataset, when evaluated over the real user data in Gboard (Google Keyboard, a production mobile keyboard application). Furthermore, our method achieves evaluation accuracy better than or comparable to the baseline during the DP FL fine-tuning over millions of mobile devices, and our final model outperforms the baseline in production A/B testing. Our experiments demonstrate the strengths of LLMs in synthesizing data close to the private distribution even without accessing the private data, and also suggest future research directions to further reduce the distribution gap.
Back to the Drawing Board: A Critical Evaluation of Poisoning Attacks on Federated Learning
Aug 23, 2021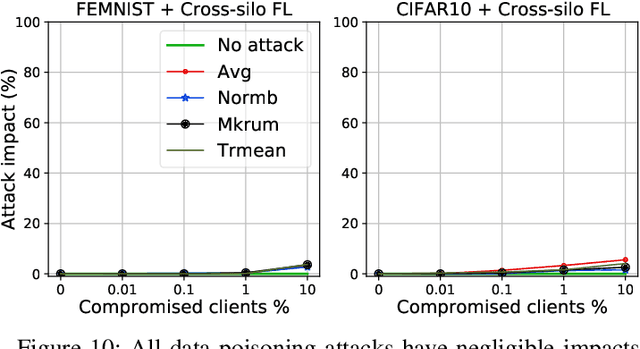
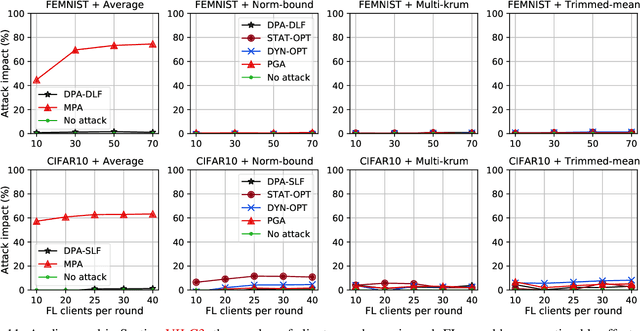
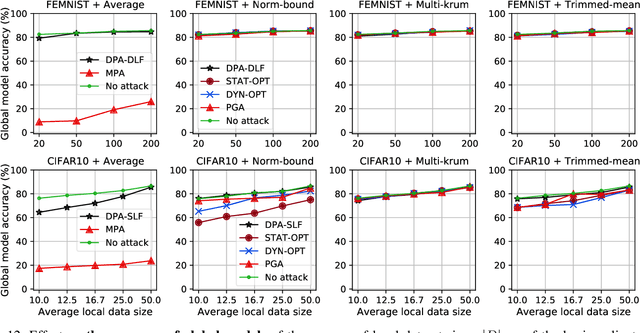
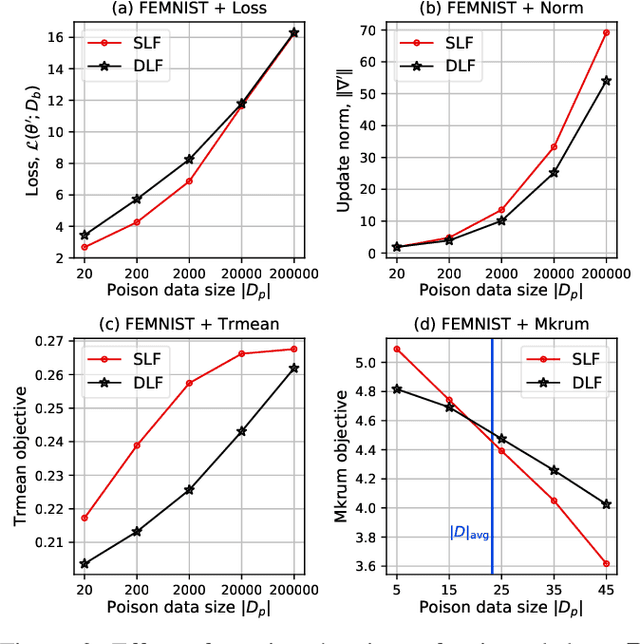
While recent works have indicated that federated learning (FL) is vulnerable to poisoning attacks by compromised clients, we show that these works make a number of unrealistic assumptions and arrive at somewhat misleading conclusions. For instance, they often use impractically high percentages of compromised clients or assume unrealistic capabilities for the adversary. We perform the first critical analysis of poisoning attacks under practical production FL environments by carefully characterizing the set of realistic threat models and adversarial capabilities. Our findings are rather surprising: contrary to the established belief, we show that FL, even without any defenses, is highly robust in practice. In fact, we go even further and propose novel, state-of-the-art poisoning attacks under two realistic threat models, and show via an extensive set of experiments across three benchmark datasets how (in)effective poisoning attacks are, especially when simple defense mechanisms are used. We correct previous misconceptions and give concrete guidelines that we hope will encourage our community to conduct more accurate research in this space and build stronger (and more realistic) attacks and defenses.
Advances and Open Problems in Federated Learning
Dec 10, 2019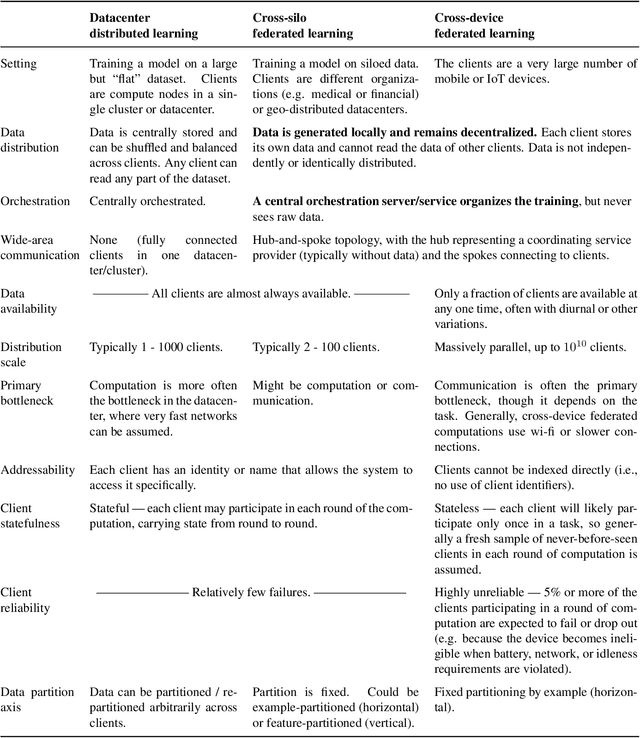

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Generative Models for Effective ML on Private, Decentralized Datasets
Nov 15, 2019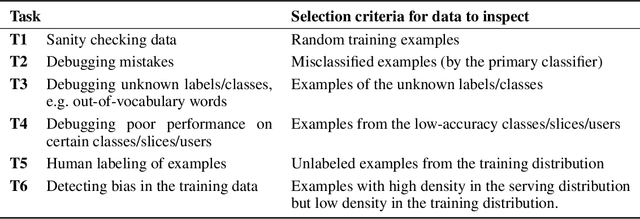
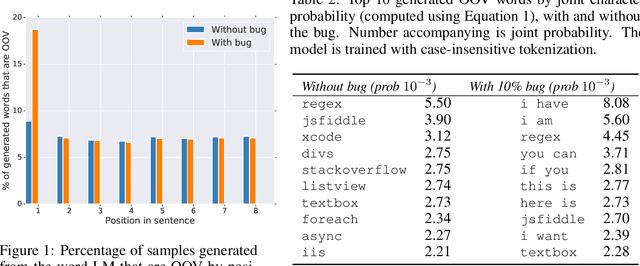
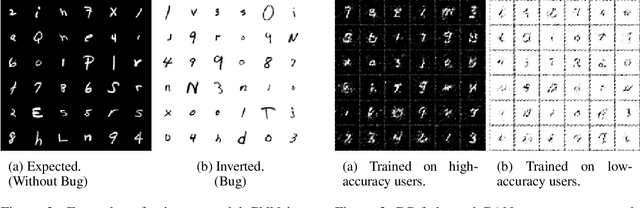
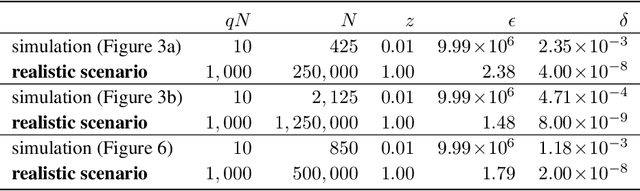
To improve real-world applications of machine learning, experienced modelers develop intuition about their datasets, their models, and how the two interact. Manual inspection of raw data - of representative samples, of outliers, of misclassifications - is an essential tool in a) identifying and fixing problems in the data, b) generating new modeling hypotheses, and c) assigning or refining human-provided labels. However, manual data inspection is problematic for privacy sensitive datasets, such as those representing the behavior of real-world individuals. Furthermore, manual data inspection is impossible in the increasingly important setting of federated learning, where raw examples are stored at the edge and the modeler may only access aggregated outputs such as metrics or model parameters. This paper demonstrates that generative models - trained using federated methods and with formal differential privacy guarantees - can be used effectively to debug many commonly occurring data issues even when the data cannot be directly inspected. We explore these methods in applications to text with differentially private federated RNNs and to images using a novel algorithm for differentially private federated GANs.
Context-Aware Local Differential Privacy
Oct 31, 2019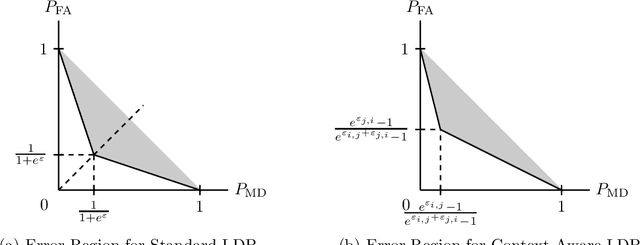
Local differential privacy (LDP) is a strong notion of privacy for individual users that often comes at the expense of a significant drop in utility. The classical definition of LDP assumes that all elements in the data domain are equally sensitive. However, in many applications, some symbols are more sensitive than others. This work proposes a context-aware framework of local differential privacy that allows a privacy designer to incorporate the application's context into the privacy definition. For binary data domains, we provide a universally optimal privatization scheme and highlight its connections to Warner's randomized response (RR) and Mangat's improved response. Motivated by geolocation and web search applications, for $k$-ary data domains, we consider two special cases of context-aware LDP: block-structured LDP and high-low LDP. We study discrete distribution estimation and provide communication-efficient, sample-optimal schemes and information-theoretic lower bounds for both models. We show that using contextual information can require fewer samples than classical LDP to achieve the same accuracy.