 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning in Practice: Reflections and Projections
Oct 11, 2024

Federated Learning (FL) is a machine learning technique that enables multiple entities to collaboratively learn a shared model without exchanging their local data. Over the past decade, FL systems have achieved substantial progress, scaling to millions of devices across various learning domains while offering meaningful differential privacy (DP) guarantees. Production systems from organizations like Google, Apple, and Meta demonstrate the real-world applicability of FL. However, key challenges remain, including verifying server-side DP guarantees and coordinating training across heterogeneous devices, limiting broader adoption. Additionally, emerging trends such as large (multi-modal) models and blurred lines between training, inference, and personalization challenge traditional FL frameworks. In response, we propose a redefined FL framework that prioritizes privacy principles rather than rigid definitions. We also chart a path forward by leveraging trusted execution environments and open-source ecosystems to address these challenges and facilitate future advancements in FL.
Confidential Federated Computations
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.
A Field Guide to Federated Optimization
Jul 14, 2021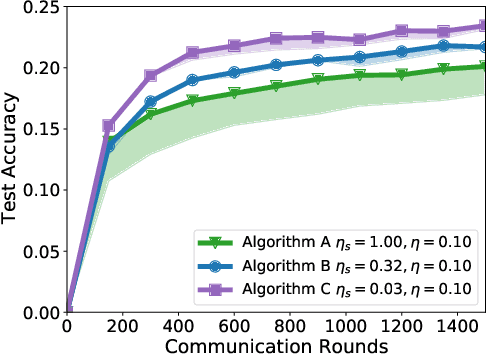


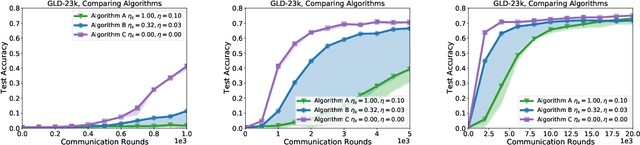
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.