 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing the State-of-the-Art in Empirical Privacy Auditing
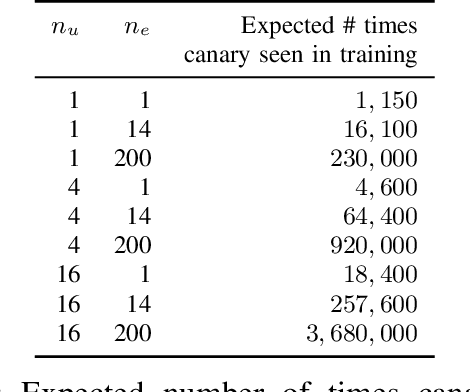
Jun 09, 2026Parameter-efficient fine-tuning of large language models (LLMs) can exhibit problematic memorization of individual training examples. Empirical privacy auditing (EPA) quantifies this risk by measuring realistic data leakage on membership inference (MI) or reconstruction attacks. A key challenge in EPA is designing ``canary'' examples that are mixed with the privacy-sensitive training data. We propose generating synthetic canaries via high-temperature sampling ($T \geq 0.8$) from LLMs, using prompts tailored to the privacy-sensitive training data. These canaries act as high-influence outliers, ensuring high identifiability and hence strong audits. Further, since the canaries are themselves non-private, they are inspectable and can be inserted with repetition without jeopardizing the privacy of the real data. An important use of models fine-tuned on privacy-sensitive data is the generation of synthetic data. This also comes with privacy risk. We introduce a powerful synthetic data audit based on fine-tuning an auxiliary model on the synthetic data. Auditing the auxiliary model for the original canaries then provides a strong estimate of the privacy leakage through the synthetic data. Finally, leveraging our strong auditing methodologies, we perform a systematic investigation into the interacting effects of model capacity and canary entropy on memorization.
Unleashing the Power of Randomization in Auditing Differentially Private ML
May 29, 2023



We present a rigorous methodology for auditing differentially private machine learning algorithms by adding multiple carefully designed examples called canaries. We take a first principles approach based on three key components. First, we introduce Lifted Differential Privacy (LiDP) that expands the definition of differential privacy to handle randomized datasets. This gives us the freedom to design randomized canaries. Second, we audit LiDP by trying to distinguish between the model trained with $K$ canaries versus $K - 1$ canaries in the dataset, leaving one canary out. By drawing the canaries i.i.d., LiDP can leverage the symmetry in the design and reuse each privately trained model to run multiple statistical tests, one for each canary. Third, we introduce novel confidence intervals that take advantage of the multiple test statistics by adapting to the empirical higher-order correlations. Together, this new recipe demonstrates significant improvements in sample complexity, both theoretically and empirically, using synthetic and real data. Further, recent advances in designing stronger canaries can be readily incorporated into the new framework.
Federated Learning of Gboard Language Models with Differential Privacy
May 29, 2023



We train language models (LMs) with federated learning (FL) and differential privacy (DP) in the Google Keyboard (Gboard). We apply the DP-Follow-the-Regularized-Leader (DP-FTRL)~\citep{kairouz21b} algorithm to achieve meaningfully formal DP guarantees without requiring uniform sampling of client devices. To provide favorable privacy-utility trade-offs, we introduce a new client participation criterion and discuss the implication of its configuration in large scale systems. We show how quantile-based clip estimation~\citep{andrew2019differentially} can be combined with DP-FTRL to adaptively choose the clip norm during training or reduce the hyperparameter tuning in preparation for training. With the help of pretraining on public data, we train and deploy more than twenty Gboard LMs that achieve high utility and $\rho-$zCDP privacy guarantees with $\rho \in (0.2, 2)$, with two models additionally trained with secure aggregation~\citep{bonawitz2017practical}. We are happy to announce that all the next word prediction neural network LMs in Gboard now have DP guarantees, and all future launches of Gboard neural network LMs will require DP guarantees. We summarize our experience and provide concrete suggestions on DP training for practitioners.
One-shot Empirical Privacy Estimation for Federated Learning
Feb 08, 2023

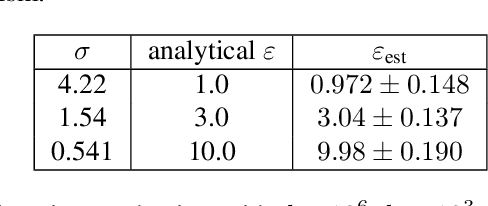
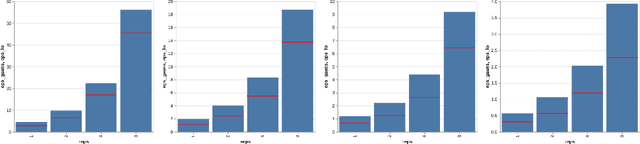
Privacy auditing techniques for differentially private (DP) algorithms are useful for estimating the privacy loss to compare against analytical bounds, or empirically measure privacy in settings where known analytical bounds on the DP loss are not tight. However, existing privacy auditing techniques usually make strong assumptions on the adversary (e.g., knowledge of intermediate model iterates or the training data distribution), are tailored to specific tasks and model architectures, and require retraining the model many times (typically on the order of thousands). These shortcomings make deploying such techniques at scale difficult in practice, especially in federated settings where model training can take days or weeks. In this work, we present a novel "one-shot" approach that can systematically address these challenges, allowing efficient auditing or estimation of the privacy loss of a model during the same, single training run used to fit model parameters. Our privacy auditing method for federated learning does not require a priori knowledge about the model architecture or task. We show that our method provides provably correct estimates for privacy loss under the Gaussian mechanism, and we demonstrate its performance on a well-established FL benchmark dataset under several adversarial models.
A Field Guide to Federated Optimization
Jul 14, 2021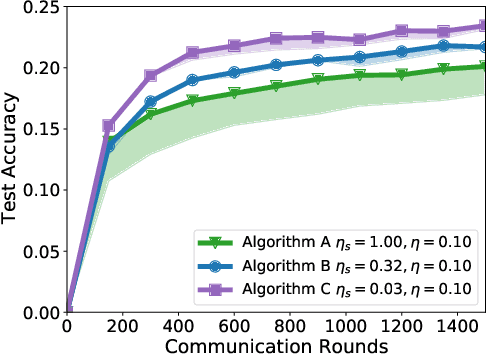


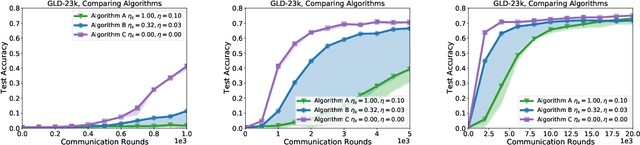
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Training Production Language Models without Memorizing User Data
Sep 21, 2020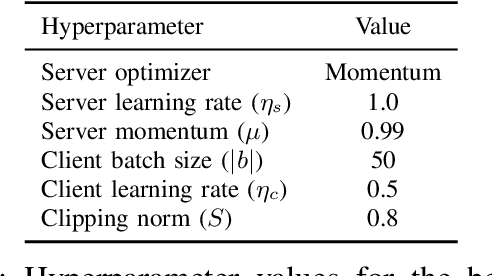
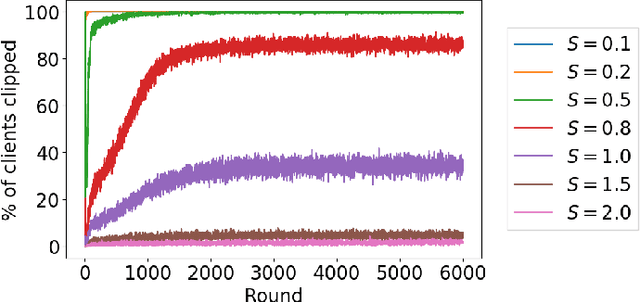
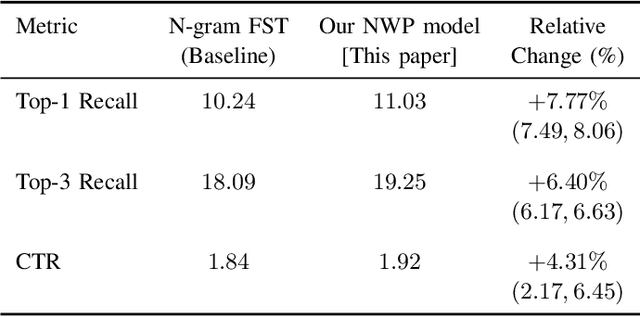
This paper presents the first consumer-scale next-word prediction (NWP) model trained with Federated Learning (FL) while leveraging the Differentially Private Federated Averaging (DP-FedAvg) technique. There has been prior work on building practical FL infrastructure, including work demonstrating the feasibility of training language models on mobile devices using such infrastructure. It has also been shown (in simulations on a public corpus) that it is possible to train NWP models with user-level differential privacy using the DP-FedAvg algorithm. Nevertheless, training production-quality NWP models with DP-FedAvg in a real-world production environment on a heterogeneous fleet of mobile phones requires addressing numerous challenges. For instance, the coordinating central server has to keep track of the devices available at the start of each round and sample devices uniformly at random from them, while ensuring \emph{secrecy of the sample}, etc. Unlike all prior privacy-focused FL work of which we are aware, for the first time we demonstrate the deployment of a differentially private mechanism for the training of a production neural network in FL, as well as the instrumentation of the production training infrastructure to perform an end-to-end empirical measurement of unintended memorization.
Differentially Private Learning with Adaptive Clipping
May 09, 2019
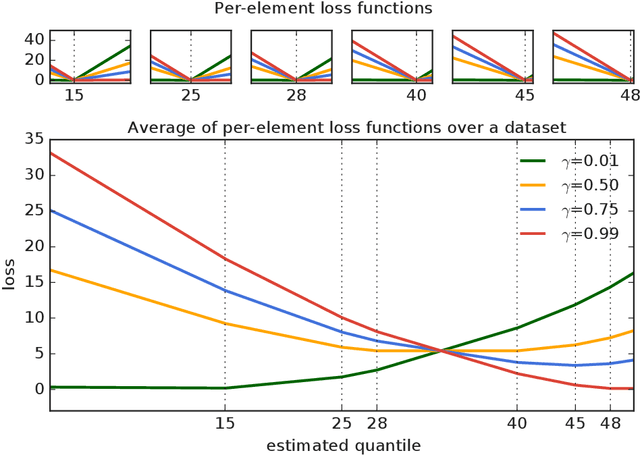
We introduce a new adaptive clipping technique for training learning models with user-level differential privacy that removes the need for extensive parameter tuning. Previous approaches to this problem use the Federated Stochastic Gradient Descent or the Federated Averaging algorithm with noised updates, and compute a differential privacy guarantee using the Moments Accountant. These approaches rely on choosing a norm bound for each user's update to the model, which needs to be tuned carefully. The best value depends on the learning rate, model architecture, number of passes made over each user's data, and possibly various other parameters. We show that adaptively setting the clipping norm applied to each user's update, based on a differentially private estimate of a target quantile of the distribution of unclipped norms, is sufficient to remove the need for such extensive parameter tuning.
A General Approach to Adding Differential Privacy to Iterative Training Procedures
Dec 15, 2018
In this work we address the practical challenges of training machine learning models on privacy-sensitive datasets by introducing a modular approach that minimizes changes to training algorithms, provides a variety of configuration strategies for the privacy mechanism, and then isolates and simplifies the critical logic that computes the final privacy guarantees. A key challenge is that training algorithms often require estimating many different quantities (vectors) from the same set of examples --- for example, gradients of different layers in a deep learning architecture, as well as metrics and batch normalization parameters. Each of these may have different properties like dimensionality, magnitude, and tolerance to noise. By extending previous work on the Moments Accountant for the subsampled Gaussian mechanism, we can provide privacy for such heterogeneous sets of vectors, while also structuring the approach to minimize software engineering challenges.
Applied Federated Learning: Improving Google Keyboard Query Suggestions
Dec 07, 2018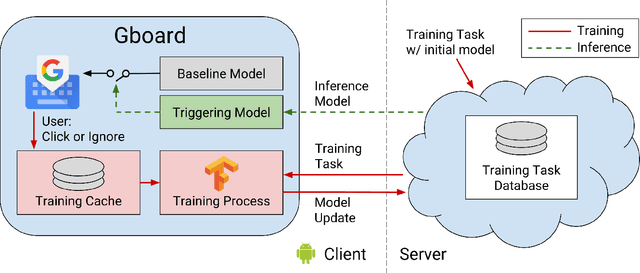

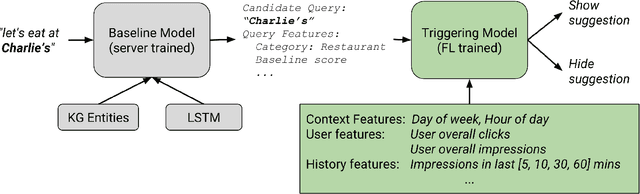

Federated learning is a distributed form of machine learning where both the training data and model training are decentralized. In this paper, we use federated learning in a commercial, global-scale setting to train, evaluate and deploy a model to improve virtual keyboard search suggestion quality without direct access to the underlying user data. We describe our observations in federated training, compare metrics to live deployments, and present resulting quality increases. In whole, we demonstrate how federated learning can be applied end-to-end to both improve user experiences and enhance user privacy.