 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Open Problems in Federated Learning
Dec 10, 2019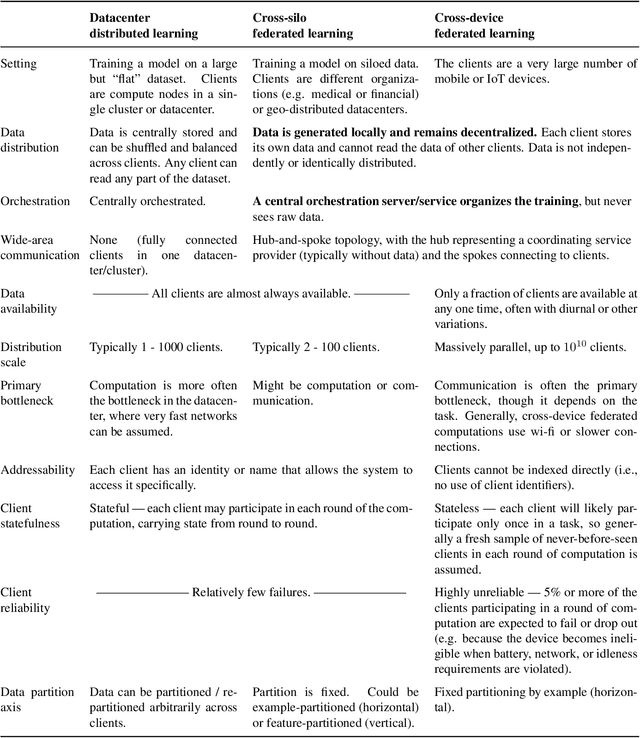
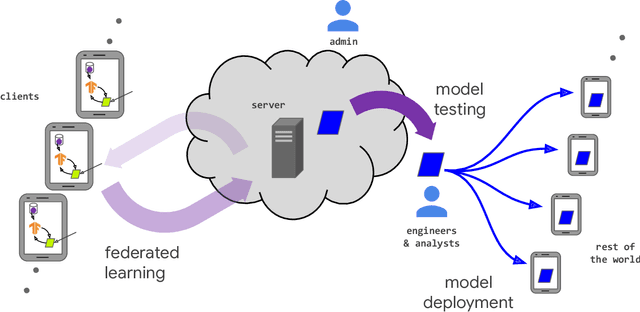
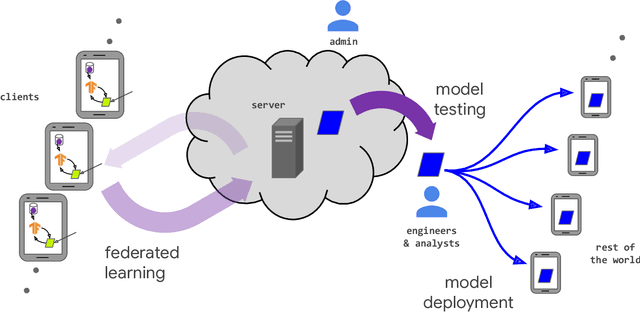

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Automatic Discovery of Privacy-Utility Pareto Fronts
May 26, 2019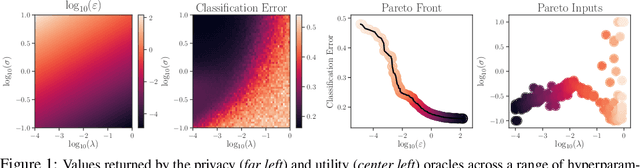
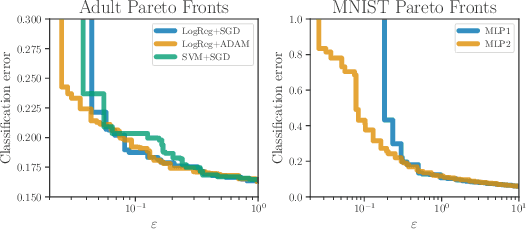
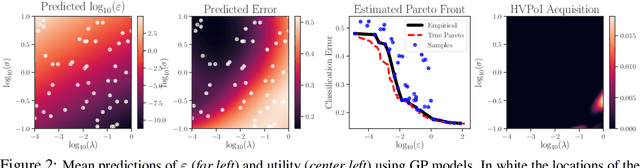

Differential privacy is a mathematical framework for privacy-preserving data analysis. Changing the hyperparameters of a differentially private algorithm allows one to trade off privacy and utility in a principled way. Quantifying this trade-off in advance is essential to decision-makers tasked with deciding how much privacy can be provided in a particular application while keeping acceptable utility. For more complex tasks, such as training neural networks under differential privacy, the utility achieved by a given algorithm can only be measured empirically. This paper presents a Bayesian optimization methodology for efficiently characterizing the privacy-utility trade-off of any differentially private algorithm using only empirical measurements of its utility. The versatility of our method is illustrated on a number of machine learning tasks involving multiple models, optimizers, and datasets.
BLENDER: Enabling Local Search with a Hybrid Differential Privacy Model
Aug 26, 2018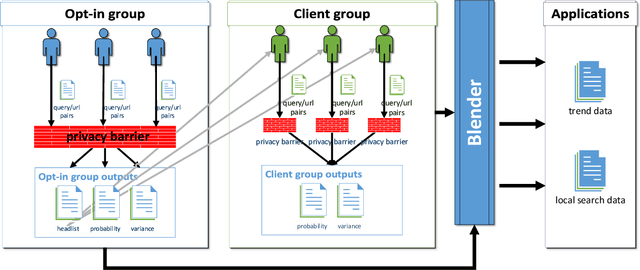



We propose a hybrid model of differential privacy that considers a combination of regular and opt-in users who desire the differential privacy guarantees of the local privacy model and the trusted curator model, respectively. We demonstrate that within this model, it is possible to design a new type of blended algorithm for the task of privately computing the head of a search log. This blended approach provides significant improvements in the utility of obtained data compared to related work while providing users with their desired privacy guarantees. Specifically, on two large search click data sets, comprising 1.75 and 16 GB respectively, our approach attains NDCG values exceeding 95% across a range of privacy budget values.