 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPS: Federated data Preprocessing via aggregated Statistics
Feb 11, 2026Federated Learning (FL) enables multiple parties to collaboratively train machine learning models without sharing raw data. However, before training, data must be preprocessed to address missing values, inconsistent formats, and heterogeneous feature scales. This preprocessing stage is critical for model performance but is largely overlooked in FL research. In practical FL systems, privacy constraints prohibit centralizing raw data, while communication efficiency introduces further challenges for distributed preprocessing. We introduce FedPS, a unified framework for federated data preprocessing based on aggregated statistics. FedPS leverages data-sketching techniques to efficiently summarize local datasets while preserving essential statistical information. Building on these summaries, we design federated algorithms for feature scaling, encoding, discretization, and missing-value imputation, and extend preprocessing-related models such as k-Means, k-Nearest Neighbors, and Bayesian Linear Regression to both horizontal and vertical FL settings. FedPS provides flexible, communication-efficient, and consistent preprocessing pipelines for practical FL deployments.
GEM+: Scalable State-of-the-Art Private Synthetic Data with Generator Networks
Nov 12, 2025
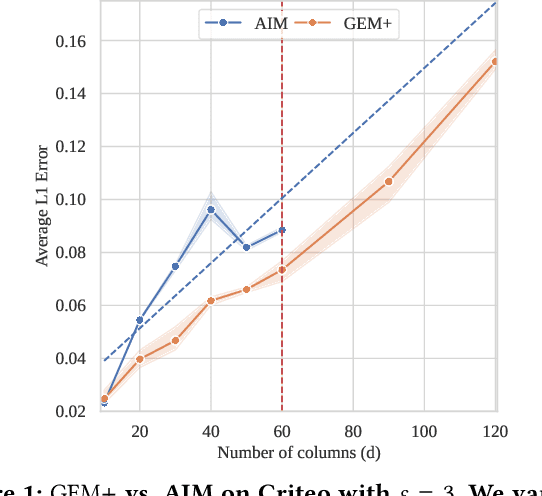
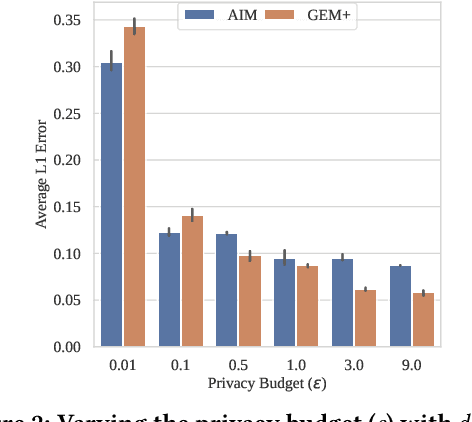

State-of-the-art differentially private synthetic tabular data has been defined by adaptive 'select-measure-generate' frameworks, exemplified by methods like AIM. These approaches iteratively measure low-order noisy marginals and fit graphical models to produce synthetic data, enabling systematic optimisation of data quality under privacy constraints. Graphical models, however, are inefficient for high-dimensional data because they require substantial memory and must be retrained from scratch whenever the graph structure changes, leading to significant computational overhead. Recent methods, like GEM, overcome these limitations by using generator neural networks for improved scalability. However, empirical comparisons have mostly focused on small datasets, limiting real-world applicability. In this work, we introduce GEM+, which integrates AIM's adaptive measurement framework with GEM's scalable generator network. Our experiments show that GEM+ outperforms AIM in both utility and scalability, delivering state-of-the-art results while efficiently handling datasets with over a hundred columns, where AIM fails due to memory and computational overheads.
Federated Computation of ROC and PR Curves
Oct 06, 2025



Receiver Operating Characteristic (ROC) and Precision-Recall (PR) curves are fundamental tools for evaluating machine learning classifiers, offering detailed insights into the trade-offs between true positive rate vs. false positive rate (ROC) or precision vs. recall (PR). However, in Federated Learning (FL) scenarios, where data is distributed across multiple clients, computing these curves is challenging due to privacy and communication constraints. Specifically, the server cannot access raw prediction scores and class labels, which are used to compute the ROC and PR curves in a centralized setting. In this paper, we propose a novel method for approximating ROC and PR curves in a federated setting by estimating quantiles of the prediction score distribution under distributed differential privacy. We provide theoretical bounds on the Area Error (AE) between the true and estimated curves, demonstrating the trade-offs between approximation accuracy, privacy, and communication cost. Empirical results on real-world datasets demonstrate that our method achieves high approximation accuracy with minimal communication and strong privacy guarantees, making it practical for privacy-preserving model evaluation in federated systems.
Power Transform Revisited: Numerically Stable, and Federated
Oct 06, 2025



Power transforms are popular parametric techniques for making data more Gaussian-like, and are widely used as preprocessing steps in statistical analysis and machine learning. However, we find that direct implementations of power transforms suffer from severe numerical instabilities, which can lead to incorrect results or even crashes. In this paper, we provide a comprehensive analysis of the sources of these instabilities and propose effective remedies. We further extend power transforms to the federated learning setting, addressing both numerical and distributional challenges that arise in this context. Experiments on real-world datasets demonstrate that our methods are both effective and robust, substantially improving stability compared to existing approaches.
Private Federated Multiclass Post-hoc Calibration
Oct 02, 2025



Calibrating machine learning models so that predicted probabilities better reflect the true outcome frequencies is crucial for reliable decision-making across many applications. In Federated Learning (FL), the goal is to train a global model on data which is distributed across multiple clients and cannot be centralized due to privacy concerns. FL is applied in key areas such as healthcare and finance where calibration is strongly required, yet federated private calibration has been largely overlooked. This work introduces the integration of post-hoc model calibration techniques within FL. Specifically, we transfer traditional centralized calibration methods such as histogram binning and temperature scaling into federated environments and define new methods to operate them under strong client heterogeneity. We study (1) a federated setting and (2) a user-level Differential Privacy (DP) setting and demonstrate how both federation and DP impacts calibration accuracy. We propose strategies to mitigate degradation commonly observed under heterogeneity and our findings highlight that our federated temperature scaling works best for DP-FL whereas our weighted binning approach is best when DP is not required.
Synthetic Tabular Data: Methods, Attacks and Defenses
Jun 06, 2025Synthetic data is often positioned as a solution to replace sensitive fixed-size datasets with a source of unlimited matching data, freed from privacy concerns. There has been much progress in synthetic data generation over the last decade, leveraging corresponding advances in machine learning and data analytics. In this survey, we cover the key developments and the main concepts in tabular synthetic data generation, including paradigms based on probabilistic graphical models and on deep learning. We provide background and motivation, before giving a technical deep-dive into the methodologies. We also address the limitations of synthetic data, by studying attacks that seek to retrieve information about the original sensitive data. Finally, we present extensions and open problems in this area.
Leveraging Vertical Public-Private Split for Improved Synthetic Data Generation
Apr 15, 2025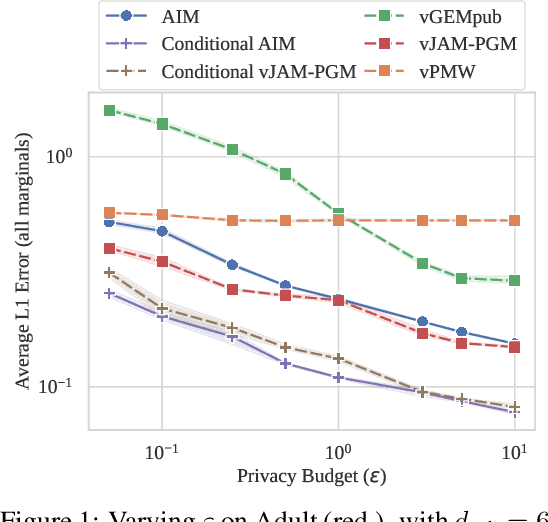


Differentially Private Synthetic Data Generation (DP-SDG) is a key enabler of private and secure tabular-data sharing, producing artificial data that carries through the underlying statistical properties of the input data. This typically involves adding carefully calibrated statistical noise to guarantee individual privacy, at the cost of synthetic data quality. Recent literature has explored scenarios where a small amount of public data is used to help enhance the quality of synthetic data. These methods study a horizontal public-private partitioning which assumes access to a small number of public rows that can be used for model initialization, providing a small utility gain. However, realistic datasets often naturally consist of public and private attributes, making a vertical public-private partitioning relevant for practical synthetic data deployments. We propose a novel framework that adapts horizontal public-assisted methods into the vertical setting. We compare this framework against our alternative approach that uses conditional generation, highlighting initial limitations of public-data assisted methods and proposing future research directions to address these challenges.
Federated Analytics in Practice: Engineering for Privacy, Scalability and Practicality
Dec 03, 2024



Cross-device Federated Analytics (FA) is a distributed computation paradigm designed to answer analytics queries about and derive insights from data held locally on users' devices. On-device computations combined with other privacy and security measures ensure that only minimal data is transmitted off-device, achieving a high standard of data protection. Despite FA's broad relevance, the applicability of existing FA systems is limited by compromised accuracy; lack of flexibility for data analytics; and an inability to scale effectively. In this paper, we describe our approach to combine privacy, scalability, and practicality to build and deploy a system that overcomes these limitations. Our FA system leverages trusted execution environments (TEEs) and optimizes the use of on-device computing resources to facilitate federated data processing across large fleets of devices, while ensuring robust, defensible, and verifiable privacy safeguards. We focus on federated analytics (statistics and monitoring), in contrast to systems for federated learning (ML workloads), and we flag the key differences.
Distributed, communication-efficient, and differentially private estimation of KL divergence
Nov 25, 2024



A key task in managing distributed, sensitive data is to measure the extent to which a distribution changes. Understanding this drift can effectively support a variety of federated learning and analytics tasks. However, in many practical settings sharing such information can be undesirable (e.g., for privacy concerns) or infeasible (e.g., for high communication costs). In this work, we describe novel algorithmic approaches for estimating the KL divergence of data across federated models of computation, under differential privacy. We analyze their theoretical properties and present an empirical study of their performance. We explore parameter settings that optimize the accuracy of the algorithm catering to each of the settings; these provide sub-variations that are applicable to real-world tasks, addressing different context- and application-specific trust level requirements. Our experimental results confirm that our private estimators achieve accuracy comparable to a baseline algorithm without differential privacy guarantees.
Towards Robust Federated Analytics via Differentially Private Measurements of Statistical Heterogeneity
Nov 07, 2024



Statistical heterogeneity is a measure of how skewed the samples of a dataset are. It is a common problem in the study of differential privacy that the usage of a statistically heterogeneous dataset results in a significant loss of accuracy. In federated scenarios, statistical heterogeneity is more likely to happen, and so the above problem is even more pressing. We explore the three most promising ways to measure statistical heterogeneity and give formulae for their accuracy, while simultaneously incorporating differential privacy. We find the optimum privacy parameters via an analytic mechanism, which incorporates root finding methods. We validate the main theorems and related hypotheses experimentally, and test the robustness of the analytic mechanism to different heterogeneity levels. The analytic mechanism in a distributed setting delivers superior accuracy to all combinations involving the classic mechanism and/or the centralized setting. All measures of statistical heterogeneity do not lose significant accuracy when a heterogeneous sample is used.