 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogAct: Enabling Agentic Reliability via Shared Logs
Apr 09, 2026Agents are LLM-driven components that can mutate environments in powerful, arbitrary ways. Extracting guarantees for the execution of agents in production environments can be challenging due to asynchrony and failures. In this paper, we propose a new abstraction called LogAct, where each agent is a deconstructed state machine playing a shared log. In LogAct, agentic actions are visible in the shared log before they are executed; can be stopped prior to execution by pluggable, decoupled voters; and recovered consistently in the case of agent or environment failure. LogAct enables agentic introspection, allowing the agent to analyze its own execution history using LLM inference, which in turn enables semantic variants of recovery, health check, and optimization. In our evaluation, LogAct agents recover efficiently and correctly from failures; debug their own performance; optimize token usage in swarms; and stop all unwanted actions for a target model on a representative benchmark with just a 3% drop in benign utility.
Observational Auditing of Label Privacy
Nov 18, 2025Differential privacy (DP) auditing is essential for evaluating privacy guarantees in machine learning systems. Existing auditing methods, however, pose a significant challenge for large-scale systems since they require modifying the training dataset -- for instance, by injecting out-of-distribution canaries or removing samples from training. Such interventions on the training data pipeline are resource-intensive and involve considerable engineering overhead. We introduce a novel observational auditing framework that leverages the inherent randomness of data distributions, enabling privacy evaluation without altering the original dataset. Our approach extends privacy auditing beyond traditional membership inference to protected attributes, with labels as a special case, addressing a key gap in existing techniques. We provide theoretical foundations for our method and perform experiments on Criteo and CIFAR-10 datasets that demonstrate its effectiveness in auditing label privacy guarantees. This work opens new avenues for practical privacy auditing in large-scale production environments.
BLIA: Detect model memorization in binary classification model through passive Label Inference attack
Mar 17, 2025Model memorization has implications for both the generalization capacity of machine learning models and the privacy of their training data. This paper investigates label memorization in binary classification models through two novel passive label inference attacks (BLIA). These attacks operate passively, relying solely on the outputs of pre-trained models, such as confidence scores and log-loss values, without interacting with or modifying the training process. By intentionally flipping 50% of the labels in controlled subsets, termed "canaries," we evaluate the extent of label memorization under two conditions: models trained without label differential privacy (Label-DP) and those trained with randomized response-based Label-DP. Despite the application of varying degrees of Label-DP, the proposed attacks consistently achieve success rates exceeding 50%, surpassing the baseline of random guessing and conclusively demonstrating that models memorize training labels, even when these labels are deliberately uncorrelated with the features.
Green Federated Learning
Mar 26, 2023



The rapid progress of AI is fueled by increasingly large and computationally intensive machine learning models and datasets. As a consequence, the amount of compute used in training state-of-the-art models is exponentially increasing (doubling every 10 months between 2015 and 2022), resulting in a large carbon footprint. Federated Learning (FL) - a collaborative machine learning technique for training a centralized model using data of decentralized entities - can also be resource-intensive and have a significant carbon footprint, particularly when deployed at scale. Unlike centralized AI that can reliably tap into renewables at strategically placed data centers, cross-device FL may leverage as many as hundreds of millions of globally distributed end-user devices with diverse energy sources. Green AI is a novel and important research area where carbon footprint is regarded as an evaluation criterion for AI, alongside accuracy, convergence speed, and other metrics. In this paper, we propose the concept of Green FL, which involves optimizing FL parameters and making design choices to minimize carbon emissions consistent with competitive performance and training time. The contributions of this work are two-fold. First, we adopt a data-driven approach to quantify the carbon emissions of FL by directly measuring real-world at-scale FL tasks running on millions of phones. Second, we present challenges, guidelines, and lessons learned from studying the trade-off between energy efficiency, performance, and time-to-train in a production FL system. Our findings offer valuable insights into how FL can reduce its carbon footprint, and they provide a foundation for future research in the area of Green AI.
Reconciling Security and Communication Efficiency in Federated Learning
Jul 26, 2022

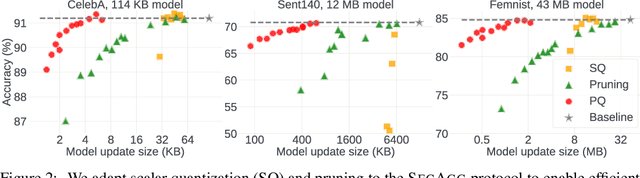
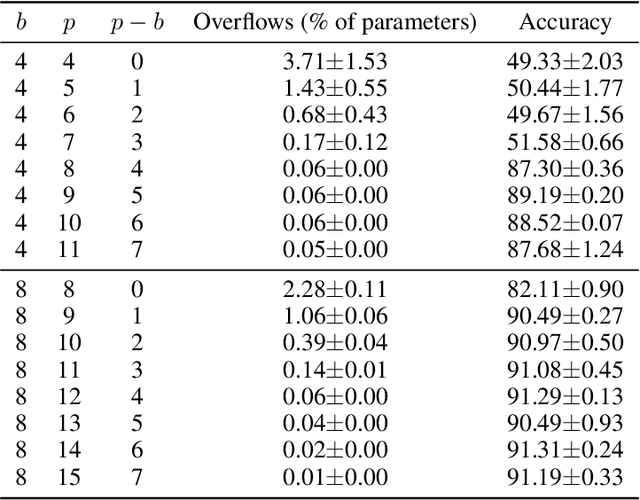
Cross-device Federated Learning is an increasingly popular machine learning setting to train a model by leveraging a large population of client devices with high privacy and security guarantees. However, communication efficiency remains a major bottleneck when scaling federated learning to production environments, particularly due to bandwidth constraints during uplink communication. In this paper, we formalize and address the problem of compressing client-to-server model updates under the Secure Aggregation primitive, a core component of Federated Learning pipelines that allows the server to aggregate the client updates without accessing them individually. In particular, we adapt standard scalar quantization and pruning methods to Secure Aggregation and propose Secure Indexing, a variant of Secure Aggregation that supports quantization for extreme compression. We establish state-of-the-art results on LEAF benchmarks in a secure Federated Learning setup with up to 40$\times$ compression in uplink communication with no meaningful loss in utility compared to uncompressed baselines.
FEL: High Capacity Learning for Recommendation and Ranking via Federated Ensemble Learning
Jun 07, 2022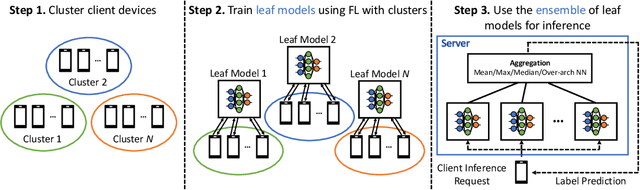
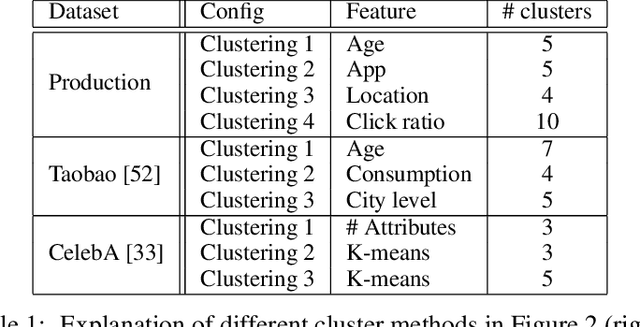
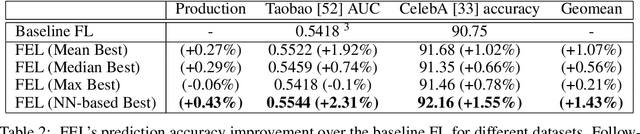
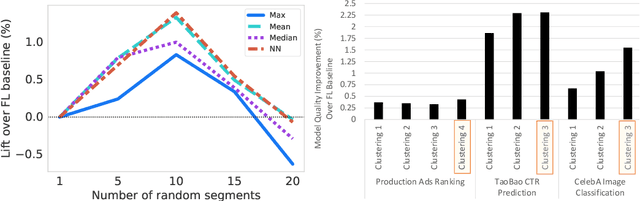
Federated learning (FL) has emerged as an effective approach to address consumer privacy needs. FL has been successfully applied to certain machine learning tasks, such as training smart keyboard models and keyword spotting. Despite FL's initial success, many important deep learning use cases, such as ranking and recommendation tasks, have been limited from on-device learning. One of the key challenges faced by practical FL adoption for DL-based ranking and recommendation is the prohibitive resource requirements that cannot be satisfied by modern mobile systems. We propose Federated Ensemble Learning (FEL) as a solution to tackle the large memory requirement of deep learning ranking and recommendation tasks. FEL enables large-scale ranking and recommendation model training on-device by simultaneously training multiple model versions on disjoint clusters of client devices. FEL integrates the trained sub-models via an over-arch layer into an ensemble model that is hosted on the server. Our experiments demonstrate that FEL leads to 0.43-2.31% model quality improvement over traditional on-device federated learning - a significant improvement for ranking and recommendation system use cases.
Defending against Reconstruction Attacks with Rényi Differential Privacy
Feb 15, 2022

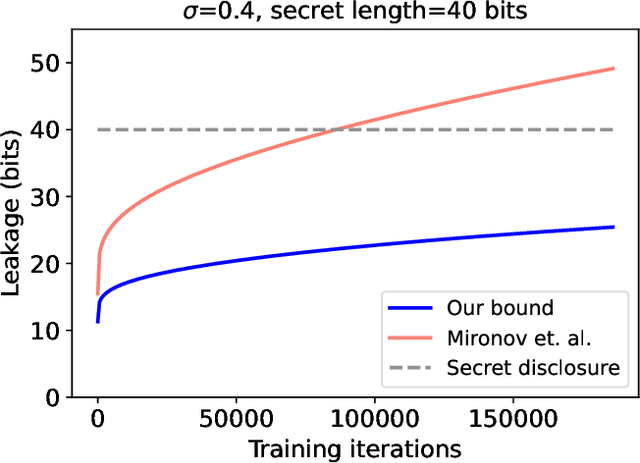
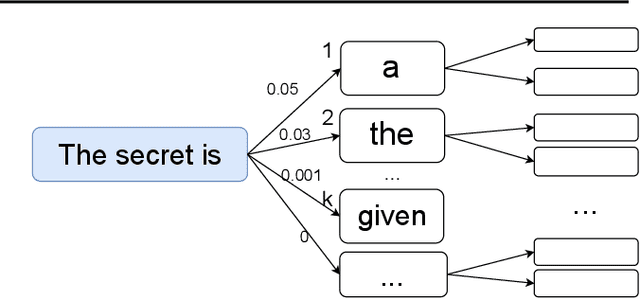
Reconstruction attacks allow an adversary to regenerate data samples of the training set using access to only a trained model. It has been recently shown that simple heuristics can reconstruct data samples from language models, making this threat scenario an important aspect of model release. Differential privacy is a known solution to such attacks, but is often used with a relatively large privacy budget (epsilon > 8) which does not translate to meaningful guarantees. In this paper we show that, for a same mechanism, we can derive privacy guarantees for reconstruction attacks that are better than the traditional ones from the literature. In particular, we show that larger privacy budgets do not protect against membership inference, but can still protect extraction of rare secrets. We show experimentally that our guarantees hold against various language models, including GPT-2 finetuned on Wikitext-103.
Opacus: User-Friendly Differential Privacy Library in PyTorch
Oct 05, 2021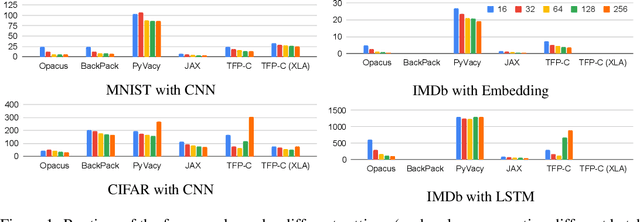
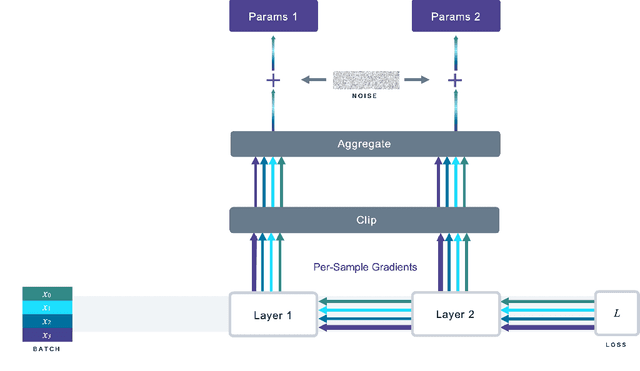
We introduce Opacus, a free, open-source PyTorch library for training deep learning models with differential privacy (hosted at opacus.ai). Opacus is designed for simplicity, flexibility, and speed. It provides a simple and user-friendly API, and enables machine learning practitioners to make a training pipeline private by adding as little as two lines to their code. It supports a wide variety of layers, including multi-head attention, convolution, LSTM, and embedding, right out of the box, and it also provides the means for supporting other user-defined layers. Opacus computes batched per-sample gradients, providing better efficiency compared to the traditional "micro batch" approach. In this paper we present Opacus, detail the principles that drove its implementation and unique features, and compare its performance against other frameworks for differential privacy in ML.
Antipodes of Label Differential Privacy: PATE and ALIBI
Jun 07, 2021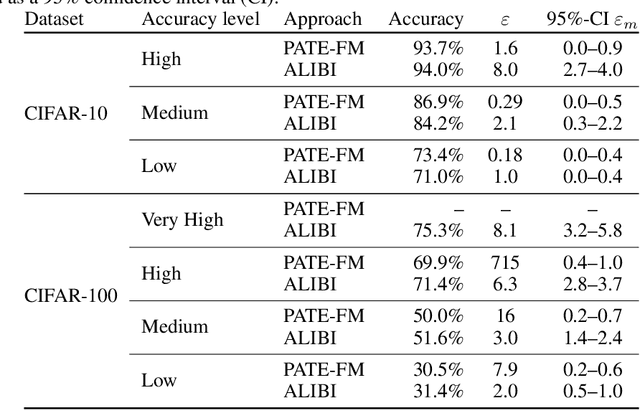
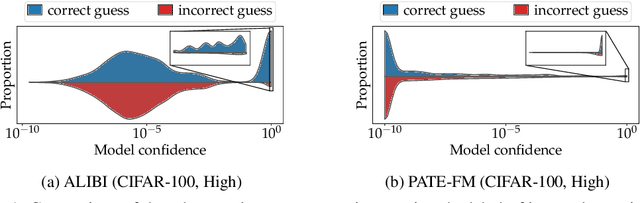
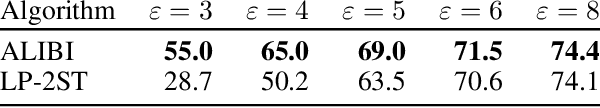
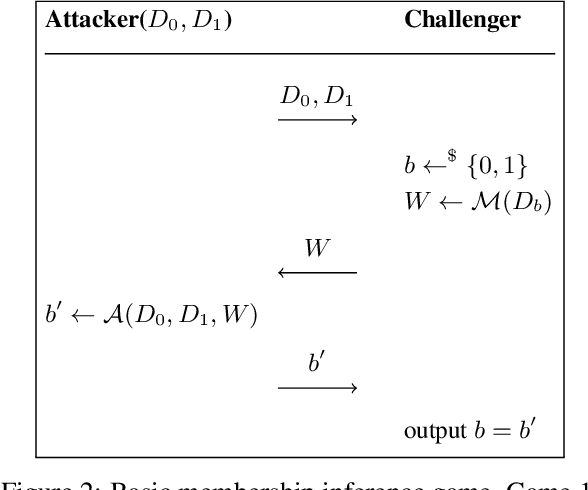
We consider the privacy-preserving machine learning (ML) setting where the trained model must satisfy differential privacy (DP) with respect to the labels of the training examples. We propose two novel approaches based on, respectively, the Laplace mechanism and the PATE framework, and demonstrate their effectiveness on standard benchmarks. While recent work by Ghazi et al. proposed Label DP schemes based on a randomized response mechanism, we argue that additive Laplace noise coupled with Bayesian inference (ALIBI) is a better fit for typical ML tasks. Moreover, we show how to achieve very strong privacy levels in some regimes, with our adaptation of the PATE framework that builds on recent advances in semi-supervised learning. We complement theoretical analysis of our algorithms' privacy guarantees with empirical evaluation of their memorization properties. Our evaluation suggests that comparing different algorithms according to their provable DP guarantees can be misleading and favor a less private algorithm with a tighter analysis.
Wide Network Learning with Differential Privacy
Mar 01, 2021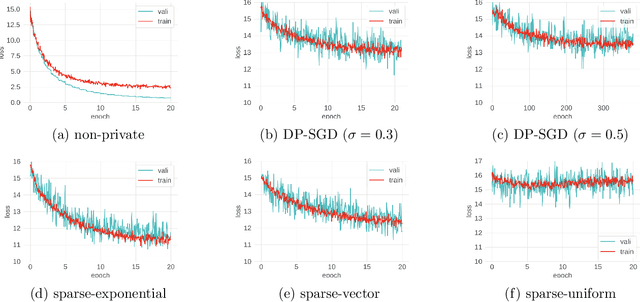
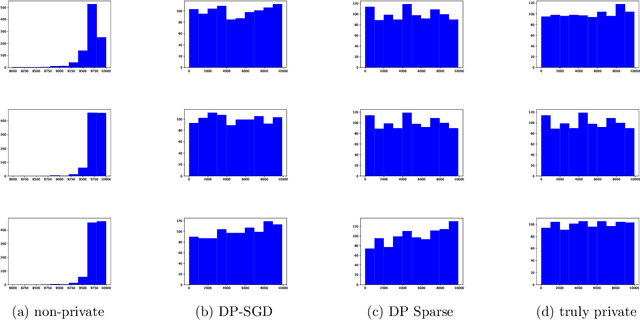
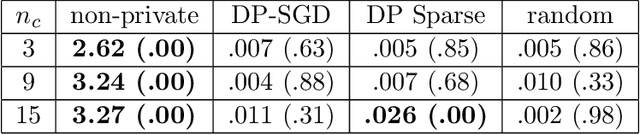
Despite intense interest and considerable effort, the current generation of neural networks suffers a significant loss of accuracy under most practically relevant privacy training regimes. One particularly challenging class of neural networks are the wide ones, such as those deployed for NLP typeahead prediction or recommender systems. Observing that these models share something in common--an embedding layer that reduces the dimensionality of the input--we focus on developing a general approach towards training these models that takes advantage of the sparsity of the gradients. More abstractly, we address the problem of differentially private Empirical Risk Minimization (ERM) for models that admit sparse gradients. We demonstrate that for non-convex ERM problems, the loss is logarithmically dependent on the number of parameters, in contrast with polynomial dependence for the general case. Following the same intuition, we propose a novel algorithm for privately training neural networks. Finally, we provide an empirical study of a DP wide neural network on a real-world dataset, which has been rarely explored in the previous work.