 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEL: High Capacity Learning for Recommendation and Ranking via Federated Ensemble Learning
Jun 07, 2022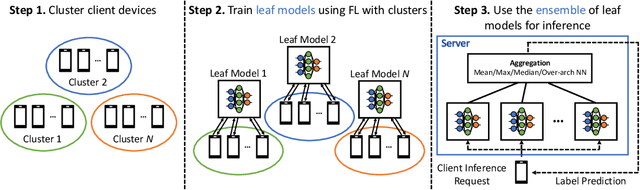
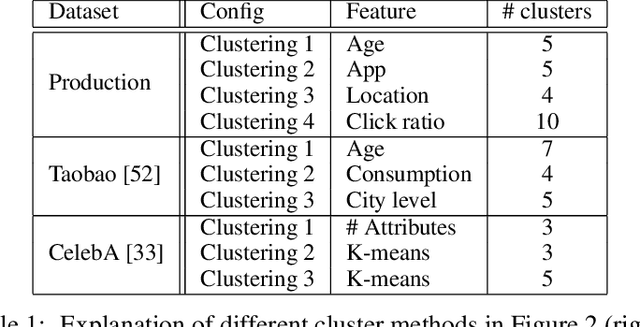
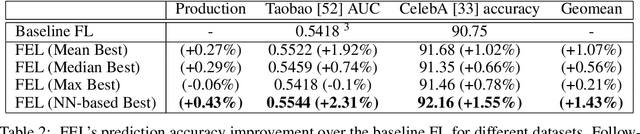
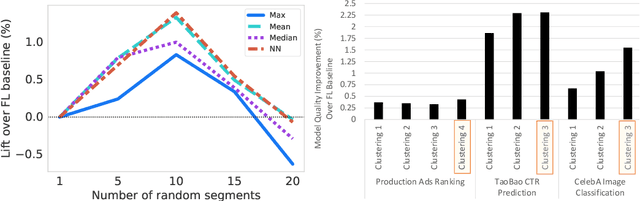
Federated learning (FL) has emerged as an effective approach to address consumer privacy needs. FL has been successfully applied to certain machine learning tasks, such as training smart keyboard models and keyword spotting. Despite FL's initial success, many important deep learning use cases, such as ranking and recommendation tasks, have been limited from on-device learning. One of the key challenges faced by practical FL adoption for DL-based ranking and recommendation is the prohibitive resource requirements that cannot be satisfied by modern mobile systems. We propose Federated Ensemble Learning (FEL) as a solution to tackle the large memory requirement of deep learning ranking and recommendation tasks. FEL enables large-scale ranking and recommendation model training on-device by simultaneously training multiple model versions on disjoint clusters of client devices. FEL integrates the trained sub-models via an over-arch layer into an ensemble model that is hosted on the server. Our experiments demonstrate that FEL leads to 0.43-2.31% model quality improvement over traditional on-device federated learning - a significant improvement for ranking and recommendation system use cases.
Wide Network Learning with Differential Privacy
Mar 01, 2021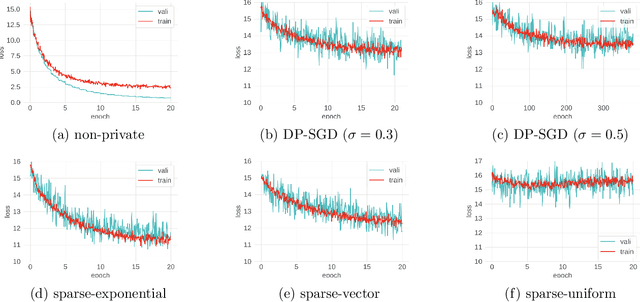
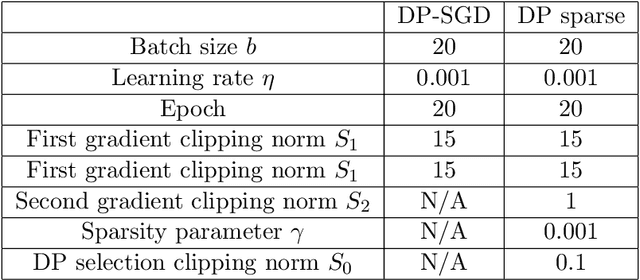
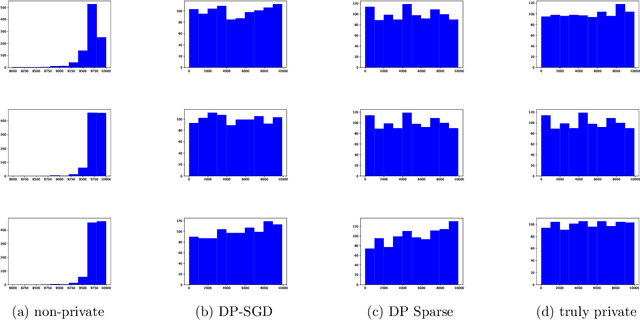
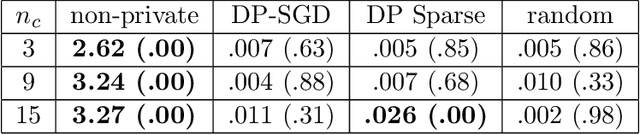
Despite intense interest and considerable effort, the current generation of neural networks suffers a significant loss of accuracy under most practically relevant privacy training regimes. One particularly challenging class of neural networks are the wide ones, such as those deployed for NLP typeahead prediction or recommender systems. Observing that these models share something in common--an embedding layer that reduces the dimensionality of the input--we focus on developing a general approach towards training these models that takes advantage of the sparsity of the gradients. More abstractly, we address the problem of differentially private Empirical Risk Minimization (ERM) for models that admit sparse gradients. We demonstrate that for non-convex ERM problems, the loss is logarithmically dependent on the number of parameters, in contrast with polynomial dependence for the general case. Following the same intuition, we propose a novel algorithm for privately training neural networks. Finally, we provide an empirical study of a DP wide neural network on a real-world dataset, which has been rarely explored in the previous work.
Accelerated learning from recommender systems using multi-armed bandit
Aug 16, 2019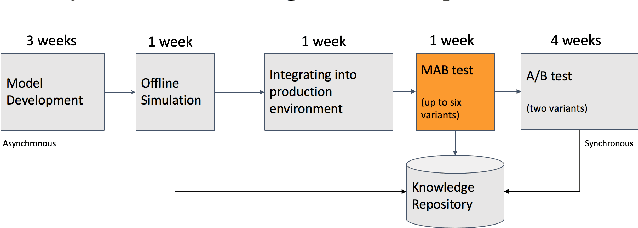
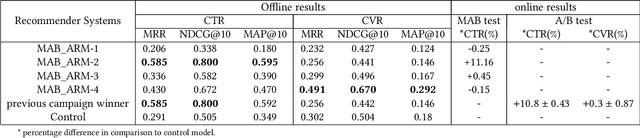
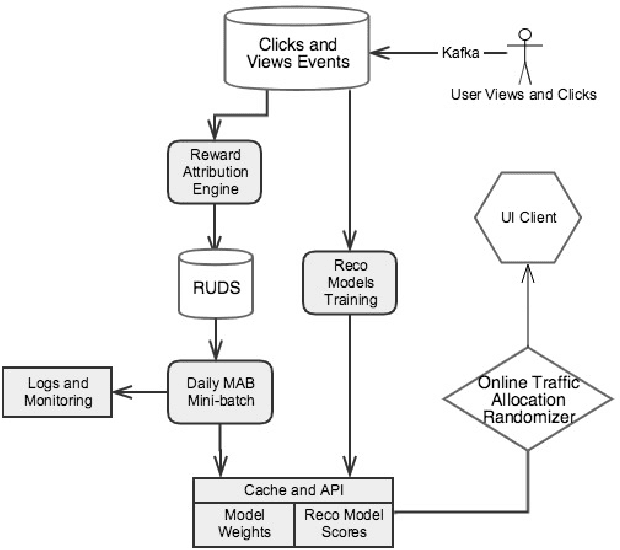
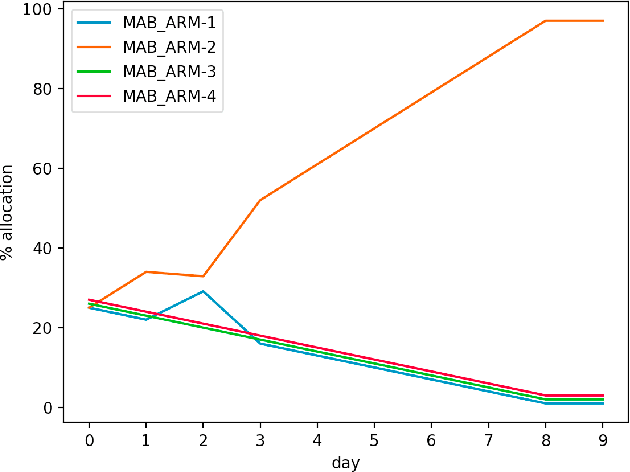
Recommendation systems are a vital component of many online marketplaces, where there are often millions of items to potentially present to users who have a wide variety of wants or needs. Evaluating recommender system algorithms is a hard task, given all the inherent bias in the data, and successful companies must be able to rapidly iterate on their solution to maintain their competitive advantage. The gold standard for evaluating recommendation algorithms has been the A/B test since it is an unbiased way to estimate how well one or more algorithms compare in the real world. However, there are a number of issues with A/B testing that make it impractical to be the sole method of testing, including long lead time, and high cost of exploration. We argue that multi armed bandit (MAB) testing as a solution to these issues. We showcase how we implemented a MAB solution as an extra step between offline and online A/B testing in a production system. We present the result of our experiment and compare all the offline, MAB, and online A/B tests metrics for our use case.
A Simple Deep Personalized Recommendation System
Aug 06, 2019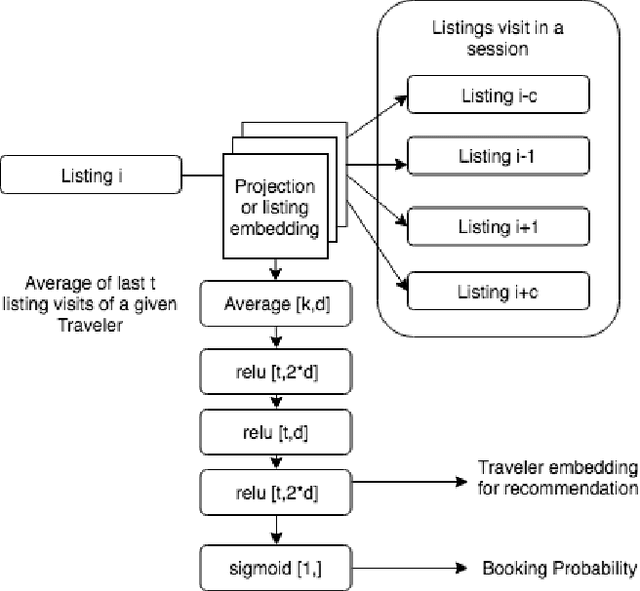
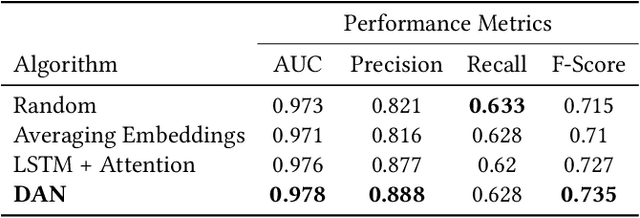
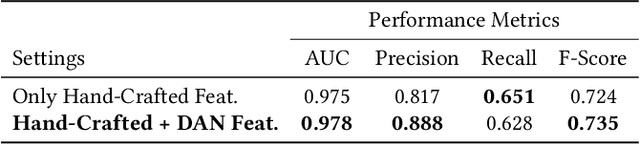
Recommender systems are critical tools to match listings and travelers in two-sided vacation rental marketplaces. Such systems require high capacity to extract user preferences for items from implicit signals at scale. To learn those preferences, we propose a Simple Deep Personalized Recommendation System to compute travelers' conditional embeddings. Our method combines listing embeddings in a supervised structure to build short-term historical context to personalize recommendations for travelers. Deployed in the production environment, this approach is computationally efficient and scalable, and allows us to capture non-linear dependencies. Our offline evaluation indicates that traveler embeddings created using a Deep Average Network can improve the precision of a downstream conversion prediction model by seven percent, outperforming more complex benchmark methods for online shopping experience personalization.
Deep Personalized Re-targeting
Jul 10, 2019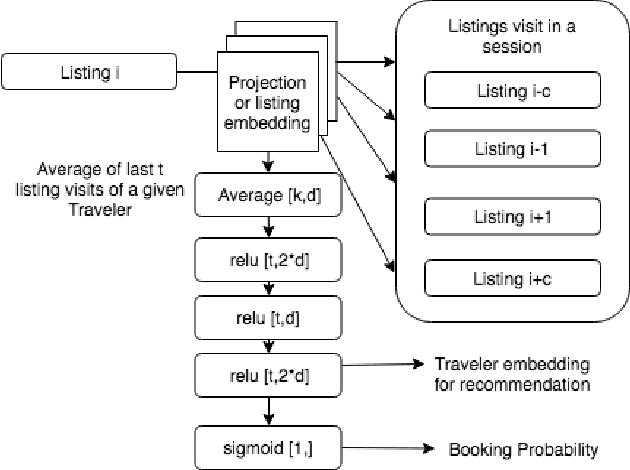
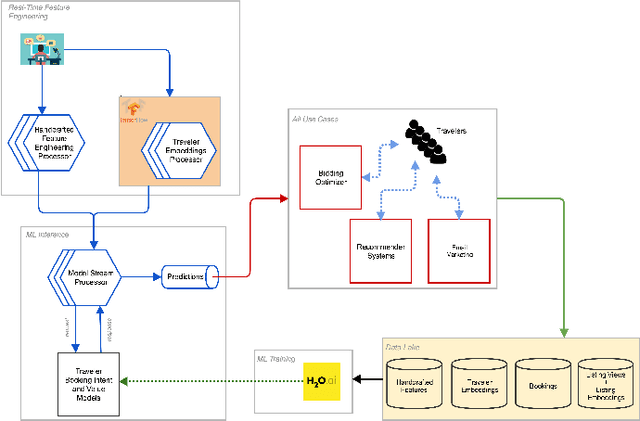

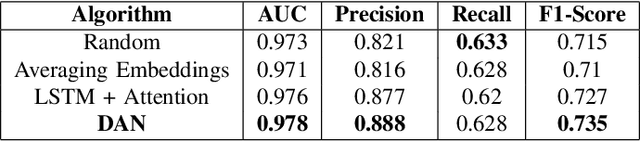
Predicting booking probability and value at the traveler level plays a central role in computational advertising for massive two-sided vacation rental marketplaces. These marketplaces host millions of travelers with long shopping cycles, spending a lot of time in the discovery phase. The footprint of the travelers in their discovery is a useful data source to help these marketplaces to predict shopping probability and value. However, there is no one-size-fits-all solution for this purpose. In this paper, we propose a hybrid model that infuses deep and shallow neural network embeddings into a gradient boosting tree model. This approach allows the latent preferences of millions of travelers to be automatically learned from sparse session logs. In addition, we present the architecture that we deployed into our production system. We find that there is a pragmatic sweet spot between expensive complex deep neural networks and simple shallow neural networks that can increase the prediction performance of a model by seven percent, based on offline analysis.