 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocoon: A System Architecture for Differentially Private Training with Correlated Noises
Oct 08, 2025Machine learning (ML) models memorize and leak training data, causing serious privacy issues to data owners. Training algorithms with differential privacy (DP), such as DP-SGD, have been gaining attention as a solution. However, DP-SGD adds a noise at each training iteration, which degrades the accuracy of the trained model. To improve accuracy, a new family of approaches adds carefully designed correlated noises, so that noises cancel out each other across iterations. We performed an extensive characterization study of these new mechanisms, for the first time to the best of our knowledge, and show they incur non-negligible overheads when the model is large or uses large embedding tables. Motivated by the analysis, we propose Cocoon, a hardware-software co-designed framework for efficient training with correlated noises. Cocoon accelerates models with embedding tables through pre-computing and storing correlated noises in a coalesced format (Cocoon-Emb), and supports large models through a custom near-memory processing device (Cocoon-NMP). On a real system with an FPGA-based NMP device prototype, Cocoon improves the performance by 2.33-10.82x(Cocoon-Emb) and 1.55-3.06x (Cocoon-NMP).
Towards Better Optimization For Listwise Preference in Diffusion Models
Oct 02, 2025



Reinforcement learning from human feedback (RLHF) has proven effectiveness for aligning text-to-image (T2I) diffusion models with human preferences. Although Direct Preference Optimization (DPO) is widely adopted for its computational efficiency and avoidance of explicit reward modeling, its applications to diffusion models have primarily relied on pairwise preferences. The precise optimization of listwise preferences remains largely unaddressed. In practice, human feedback on image preferences often contains implicit ranked information, which conveys more precise human preferences than pairwise comparisons. In this work, we propose Diffusion-LPO, a simple and effective framework for Listwise Preference Optimization in diffusion models with listwise data. Given a caption, we aggregate user feedback into a ranked list of images and derive a listwise extension of the DPO objective under the Plackett-Luce model. Diffusion-LPO enforces consistency across the entire ranking by encouraging each sample to be preferred over all of its lower-ranked alternatives. We empirically demonstrate the effectiveness of Diffusion-LPO across various tasks, including text-to-image generation, image editing, and personalized preference alignment. Diffusion-LPO consistently outperforms pairwise DPO baselines on visual quality and preference alignment.
LazyDP: Co-Designing Algorithm-Software for Scalable Training of Differentially Private Recommendation Models
Apr 12, 2024Differential privacy (DP) is widely being employed in the industry as a practical standard for privacy protection. While private training of computer vision or natural language processing applications has been studied extensively, the computational challenges of training of recommender systems (RecSys) with DP have not been explored. In this work, we first present our detailed characterization of private RecSys training using DP-SGD, root-causing its several performance bottlenecks. Specifically, we identify DP-SGD's noise sampling and noisy gradient update stage to suffer from a severe compute and memory bandwidth limitation, respectively, causing significant performance overhead in training private RecSys. Based on these findings, we propose LazyDP, an algorithm-software co-design that addresses the compute and memory challenges of training RecSys with DP-SGD. Compared to a state-of-the-art DP-SGD training system, we demonstrate that LazyDP provides an average 119x training throughput improvement while also ensuring mathematically equivalent, differentially private RecSys models to be trained.
Approximating ReLU on a Reduced Ring for Efficient MPC-based Private Inference
Sep 09, 2023



Secure multi-party computation (MPC) allows users to offload machine learning inference on untrusted servers without having to share their privacy-sensitive data. Despite their strong security properties, MPC-based private inference has not been widely adopted in the real world due to their high communication overhead. When evaluating ReLU layers, MPC protocols incur a significant amount of communication between the parties, making the end-to-end execution time multiple orders slower than its non-private counterpart. This paper presents HummingBird, an MPC framework that reduces the ReLU communication overhead significantly by using only a subset of the bits to evaluate ReLU on a smaller ring. Based on theoretical analyses, HummingBird identifies bits in the secret share that are not crucial for accuracy and excludes them during ReLU evaluation to reduce communication. With its efficient search engine, HummingBird discards 87--91% of the bits during ReLU and still maintains high accuracy. On a real MPC setup involving multiple servers, HummingBird achieves on average 2.03--2.67x end-to-end speedup without introducing any errors, and up to 8.64x average speedup when some amount of accuracy degradation can be tolerated, due to its up to 8.76x communication reduction.
Information Flow Control in Machine Learning through Modular Model Architecture
Jun 05, 2023
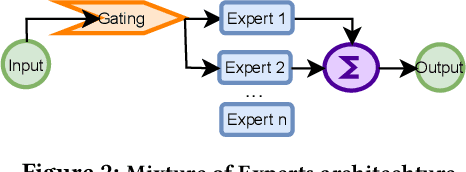

In today's machine learning (ML) models, any part of the training data can affect its output. This lack of control for information flow from training data to model output is a major obstacle in training models on sensitive data when access control only allows individual users to access a subset of data. To enable secure machine learning for access controlled data, we propose the notion of information flow control for machine learning, and develop a secure Transformer-based language model based on the Mixture-of-Experts (MoE) architecture. The secure MoE architecture controls information flow by limiting the influence of training data from each security domain to a single expert module, and only enabling a subset of experts at inference time based on an access control policy. The evaluation using a large corpus of text data shows that the proposed MoE architecture has minimal (1.9%) performance overhead and can significantly improve model accuracy (up to 37%) by enabling training on access-controlled data.
Bounding the Invertibility of Privacy-preserving Instance Encoding using Fisher Information
May 06, 2023Privacy-preserving instance encoding aims to encode raw data as feature vectors without revealing their privacy-sensitive information. When designed properly, these encodings can be used for downstream ML applications such as training and inference with limited privacy risk. However, the vast majority of existing instance encoding schemes are based on heuristics and their privacy-preserving properties are only validated empirically against a limited set of attacks. In this paper, we propose a theoretically-principled measure for the privacy of instance encoding based on Fisher information. We show that our privacy measure is intuitive, easily applicable, and can be used to bound the invertibility of encodings both theoretically and empirically.
Green Federated Learning
Mar 26, 2023



The rapid progress of AI is fueled by increasingly large and computationally intensive machine learning models and datasets. As a consequence, the amount of compute used in training state-of-the-art models is exponentially increasing (doubling every 10 months between 2015 and 2022), resulting in a large carbon footprint. Federated Learning (FL) - a collaborative machine learning technique for training a centralized model using data of decentralized entities - can also be resource-intensive and have a significant carbon footprint, particularly when deployed at scale. Unlike centralized AI that can reliably tap into renewables at strategically placed data centers, cross-device FL may leverage as many as hundreds of millions of globally distributed end-user devices with diverse energy sources. Green AI is a novel and important research area where carbon footprint is regarded as an evaluation criterion for AI, alongside accuracy, convergence speed, and other metrics. In this paper, we propose the concept of Green FL, which involves optimizing FL parameters and making design choices to minimize carbon emissions consistent with competitive performance and training time. The contributions of this work are two-fold. First, we adopt a data-driven approach to quantify the carbon emissions of FL by directly measuring real-world at-scale FL tasks running on millions of phones. Second, we present challenges, guidelines, and lessons learned from studying the trade-off between energy efficiency, performance, and time-to-train in a production FL system. Our findings offer valuable insights into how FL can reduce its carbon footprint, and they provide a foundation for future research in the area of Green AI.
GPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
Data Leakage via Access Patterns of Sparse Features in Deep Learning-based Recommendation Systems
Dec 12, 2022Online personalized recommendation services are generally hosted in the cloud where users query the cloud-based model to receive recommended input such as merchandise of interest or news feed. State-of-the-art recommendation models rely on sparse and dense features to represent users' profile information and the items they interact with. Although sparse features account for 99% of the total model size, there was not enough attention paid to the potential information leakage through sparse features. These sparse features are employed to track users' behavior, e.g., their click history, object interactions, etc., potentially carrying each user's private information. Sparse features are represented as learned embedding vectors that are stored in large tables, and personalized recommendation is performed by using a specific user's sparse feature to index through the tables. Even with recently-proposed methods that hides the computation happening in the cloud, an attacker in the cloud may be able to still track the access patterns to the embedding tables. This paper explores the private information that may be learned by tracking a recommendation model's sparse feature access patterns. We first characterize the types of attacks that can be carried out on sparse features in recommendation models in an untrusted cloud, followed by a demonstration of how each of these attacks leads to extracting users' private information or tracking users by their behavior over time.
Measuring and Controlling Split Layer Privacy Leakage Using Fisher Information
Sep 21, 2022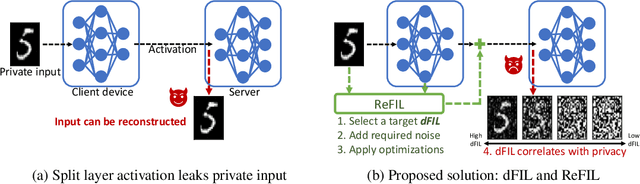
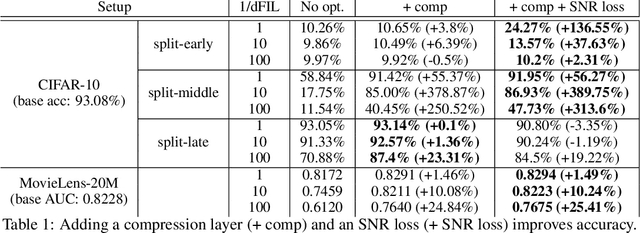
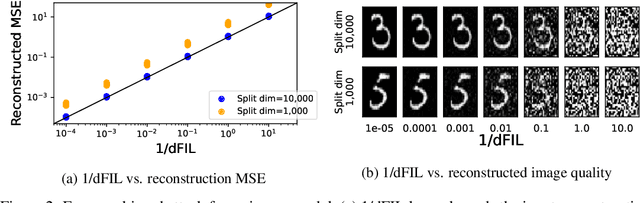
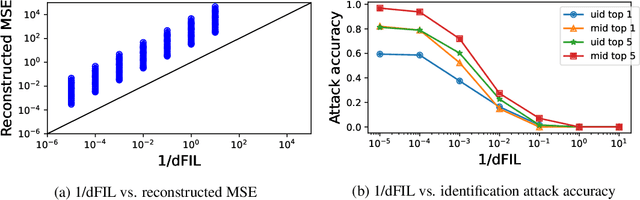
Split learning and inference propose to run training/inference of a large model that is split across client devices and the cloud. However, such a model splitting imposes privacy concerns, because the activation flowing through the split layer may leak information about the clients' private input data. There is currently no good way to quantify how much private information is being leaked through the split layer, nor a good way to improve privacy up to the desired level. In this work, we propose to use Fisher information as a privacy metric to measure and control the information leakage. We show that Fisher information can provide an intuitive understanding of how much private information is leaking through the split layer, in the form of an error bound for an unbiased reconstruction attacker. We then propose a privacy-enhancing technique, ReFIL, that can enforce a user-desired level of Fisher information leakage at the split layer to achieve high privacy, while maintaining reasonable utility.