 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
LazyDP: Co-Designing Algorithm-Software for Scalable Training of Differentially Private Recommendation Models
Apr 12, 2024Differential privacy (DP) is widely being employed in the industry as a practical standard for privacy protection. While private training of computer vision or natural language processing applications has been studied extensively, the computational challenges of training of recommender systems (RecSys) with DP have not been explored. In this work, we first present our detailed characterization of private RecSys training using DP-SGD, root-causing its several performance bottlenecks. Specifically, we identify DP-SGD's noise sampling and noisy gradient update stage to suffer from a severe compute and memory bandwidth limitation, respectively, causing significant performance overhead in training private RecSys. Based on these findings, we propose LazyDP, an algorithm-software co-design that addresses the compute and memory challenges of training RecSys with DP-SGD. Compared to a state-of-the-art DP-SGD training system, we demonstrate that LazyDP provides an average 119x training throughput improvement while also ensuring mathematically equivalent, differentially private RecSys models to be trained.
Training Personalized Recommendation Systems from (GPU) Scratch: Look Forward not Backwards
May 10, 2022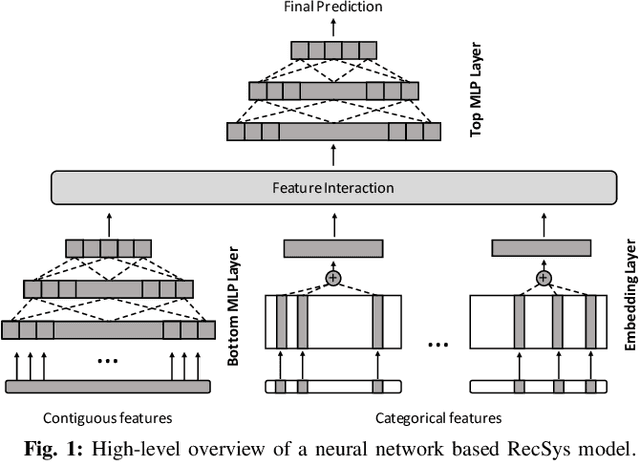
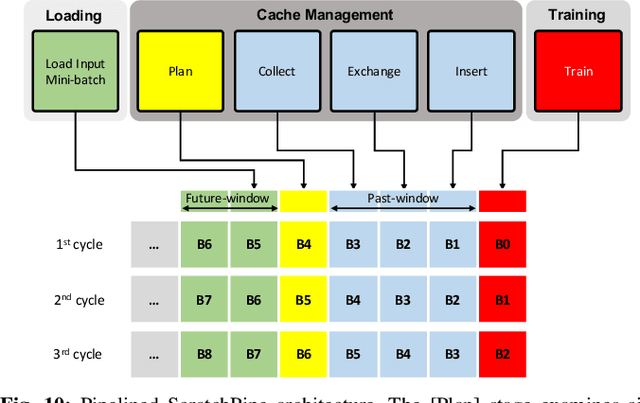
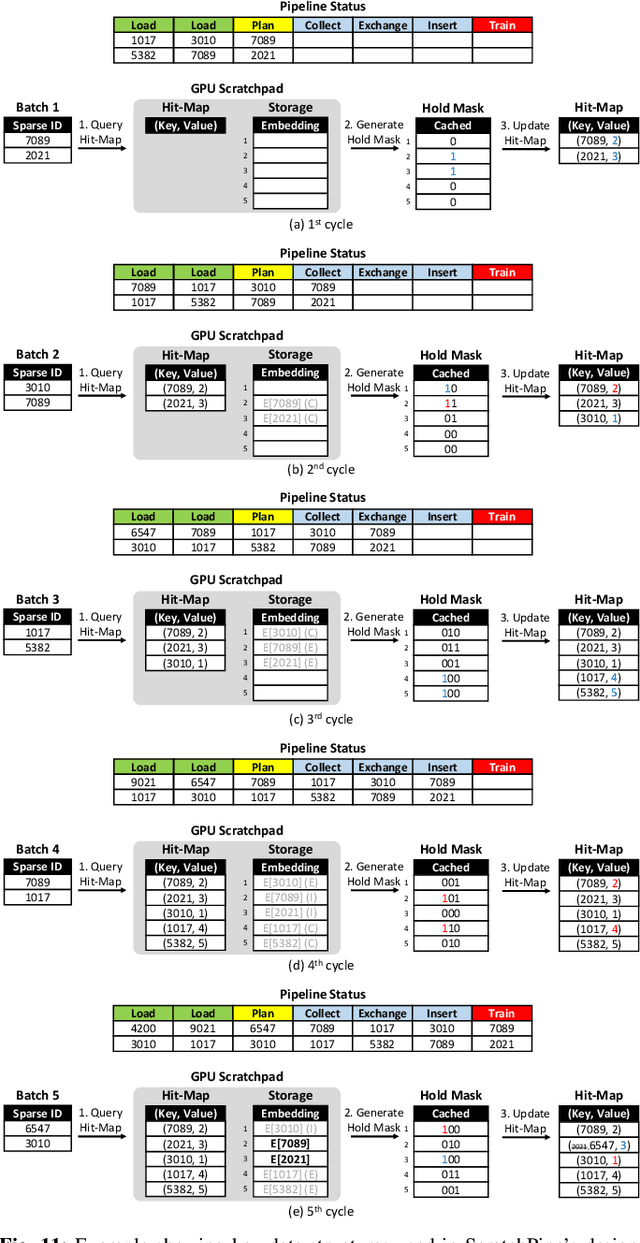
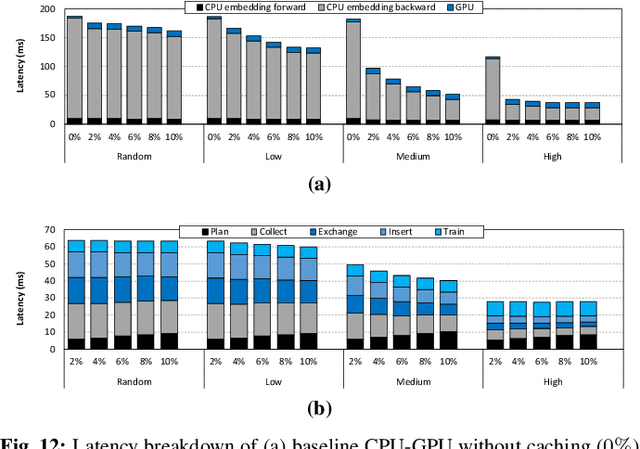
Personalized recommendation models (RecSys) are one of the most popular machine learning workload serviced by hyperscalers. A critical challenge of training RecSys is its high memory capacity requirements, reaching hundreds of GBs to TBs of model size. In RecSys, the so-called embedding layers account for the majority of memory usage so current systems employ a hybrid CPU-GPU design to have the large CPU memory store the memory hungry embedding layers. Unfortunately, training embeddings involve several memory bandwidth intensive operations which is at odds with the slow CPU memory, causing performance overheads. Prior work proposed to cache frequently accessed embeddings inside GPU memory as means to filter down the embedding layer traffic to CPU memory, but this paper observes several limitations with such cache design. In this work, we present a fundamentally different approach in designing embedding caches for RecSys. Our proposed ScratchPipe architecture utilizes unique properties of RecSys training to develop an embedding cache that not only sees the past but also the "future" cache accesses. ScratchPipe exploits such property to guarantee that the active working set of embedding layers can "always" be captured inside our proposed cache design, enabling embedding layer training to be conducted at GPU memory speed.
Tensor Casting: Co-Designing Algorithm-Architecture for Personalized Recommendation Training
Oct 25, 2020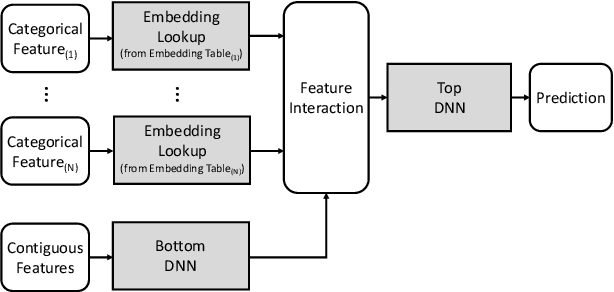
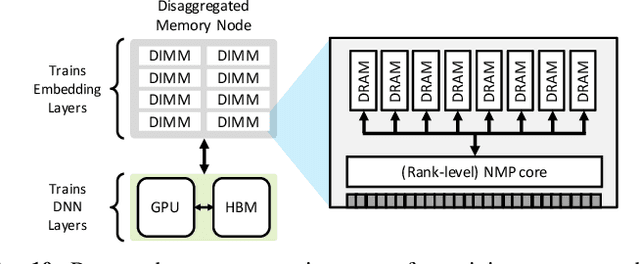
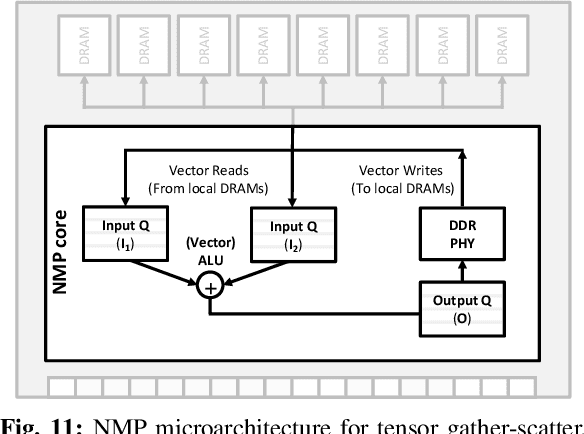
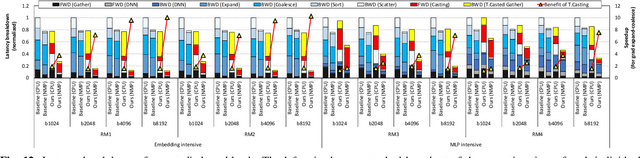
Personalized recommendations are one of the most widely deployed machine learning (ML) workload serviced from cloud datacenters. As such, architectural solutions for high-performance recommendation inference have recently been the target of several prior literatures. Unfortunately, little have been explored and understood regarding the training side of this emerging ML workload. In this paper, we first perform a detailed workload characterization study on training recommendations, root-causing sparse embedding layer training as one of the most significant performance bottlenecks. We then propose our algorithm-architecture co-design called Tensor Casting, which enables the development of a generic accelerator architecture for tensor gather-scatter that encompasses all the key primitives of training embedding layers. When prototyped on a real CPU-GPU system, Tensor Casting provides 1.9-21x improvements in training throughput compared to state-of-the-art approaches.
Centaur: A Chiplet-based, Hybrid Sparse-Dense Accelerator for Personalized Recommendations
May 12, 2020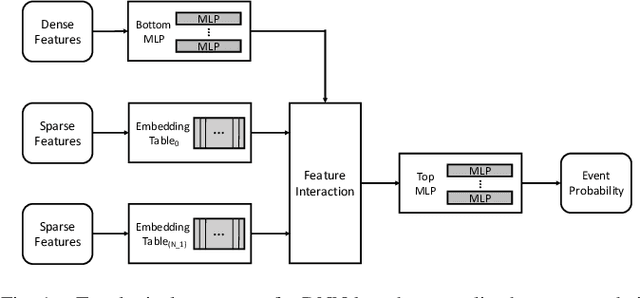
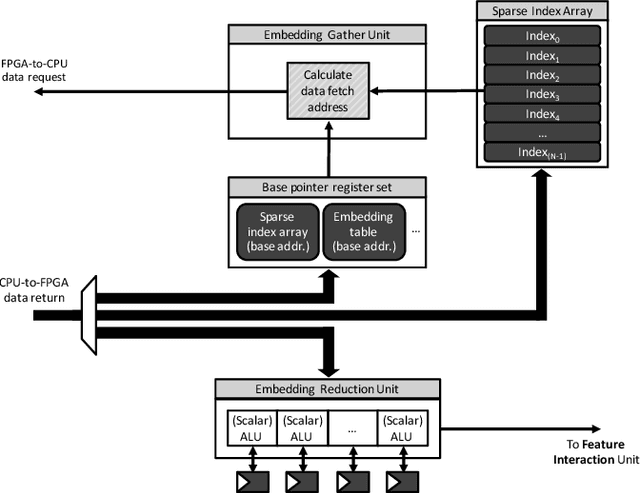
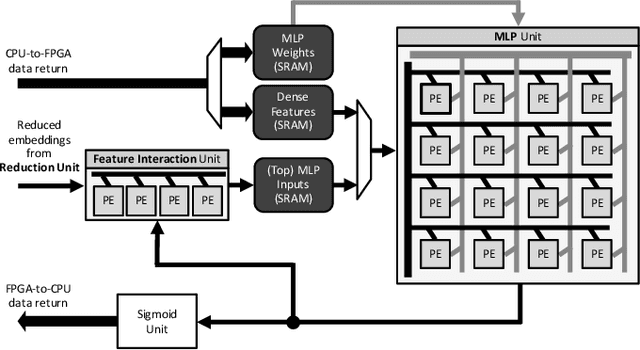
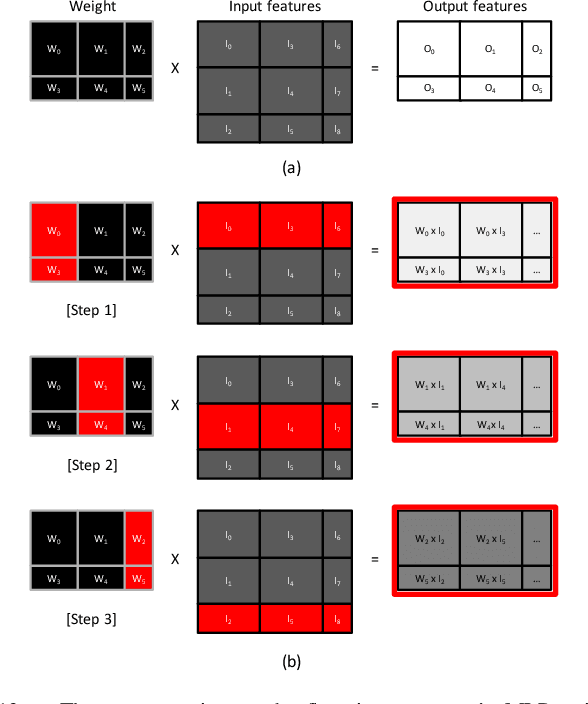
Personalized recommendations are the backbone machine learning (ML) algorithm that powers several important application domains (e.g., ads, e-commerce, etc) serviced from cloud datacenters. Sparse embedding layers are a crucial building block in designing recommendations yet little attention has been paid in properly accelerating this important ML algorithm. This paper first provides a detailed workload characterization on personalized recommendations and identifies two significant performance limiters: memory-intensive embedding layers and compute-intensive multi-layer perceptron (MLP) layers. We then present Centaur, a chiplet-based hybrid sparse-dense accelerator that addresses both the memory throughput challenges of embedding layers and the compute limitations of MLP layers. We implement and demonstrate our proposal on an Intel HARPv2, a package-integrated CPU+FPGA device, which shows a 1.7-17.2x performance speedup and 1.7-19.5x energy-efficiency improvement than conventional approaches.
NeuMMU: Architectural Support for Efficient Address Translations in Neural Processing Units
Nov 15, 2019
To satisfy the compute and memory demands of deep neural networks, neural processing units (NPUs) are widely being utilized for accelerating deep learning algorithms. Similar to how GPUs have evolved from a slave device into a mainstream processor architecture, it is likely that NPUs will become first class citizens in this fast-evolving heterogeneous architecture space. This paper makes a case for enabling address translation in NPUs to decouple the virtual and physical memory address space. Through a careful data-driven application characterization study, we root-cause several limitations of prior GPU-centric address translation schemes and propose a memory management unit (MMU) that is tailored for NPUs. Compared to an oracular MMU design point, our proposal incurs only an average 0.06% performance overhead.
TensorDIMM: A Practical Near-Memory Processing Architecture for Embeddings and Tensor Operations in Deep Learning
Aug 25, 2019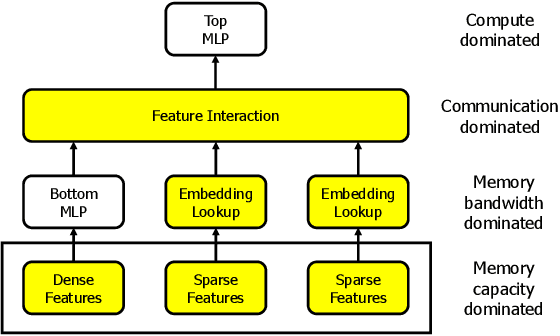

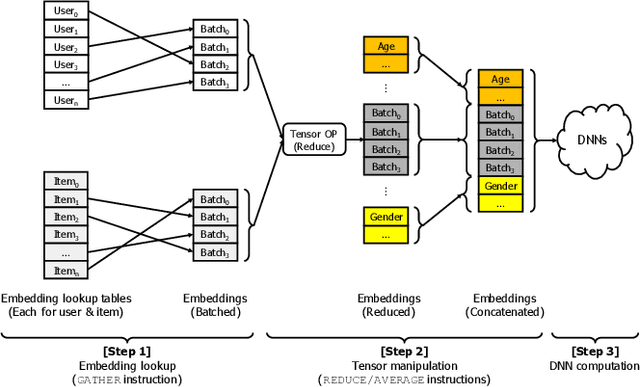
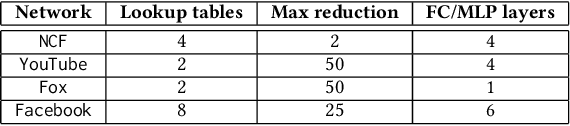
Recent studies from several hyperscalars pinpoint to embedding layers as the most memory-intensive deep learning (DL) algorithm being deployed in today's datacenters. This paper addresses the memory capacity and bandwidth challenges of embedding layers and the associated tensor operations. We present our vertically integrated hardware/software co-design, which includes a custom DIMM module enhanced with near-data processing cores tailored for DL tensor operations. These custom DIMMs are populated inside a GPU-centric system interconnect as a remote memory pool, allowing GPUs to utilize for scalable memory bandwidth and capacity expansion. A prototype implementation of our proposal on real DL systems shows an average 6.2-17.6x performance improvement on state-of-the-art recommender systems.
Beyond the Memory Wall: A Case for Memory-centric HPC System for Deep Learning
Feb 18, 2019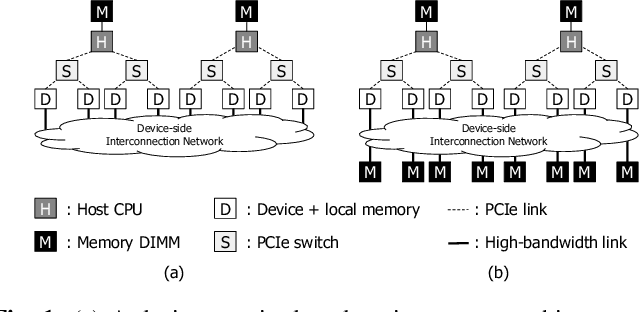

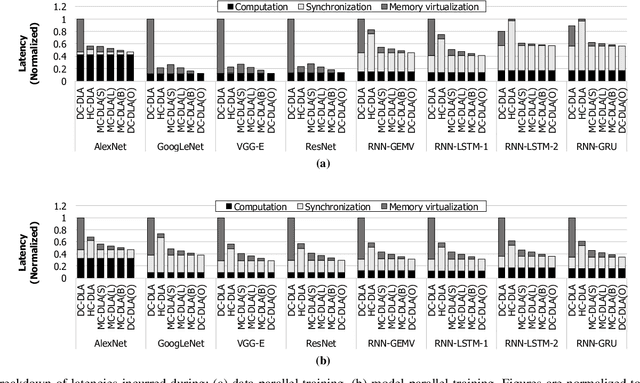
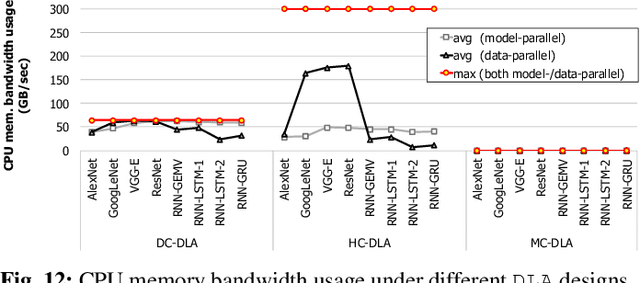
As the models and the datasets to train deep learning (DL) models scale, system architects are faced with new challenges, one of which is the memory capacity bottleneck, where the limited physical memory inside the accelerator device constrains the algorithm that can be studied. We propose a memory-centric deep learning system that can transparently expand the memory capacity available to the accelerators while also providing fast inter-device communication for parallel training. Our proposal aggregates a pool of memory modules locally within the device-side interconnect, which are decoupled from the host interface and function as a vehicle for transparent memory capacity expansion. Compared to conventional systems, our proposal achieves an average 2.8x speedup on eight DL applications and increases the system-wide memory capacity to tens of TBs.