 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Memory Wall: A Case for Memory-centric HPC System for Deep Learning
Paper and Code
Feb 18, 2019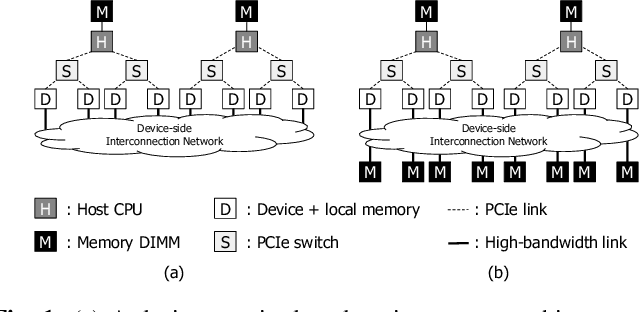

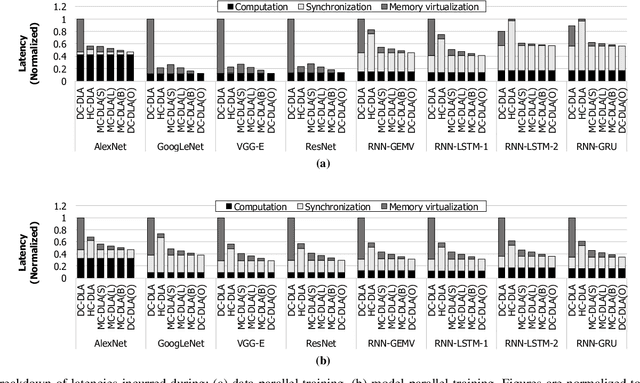
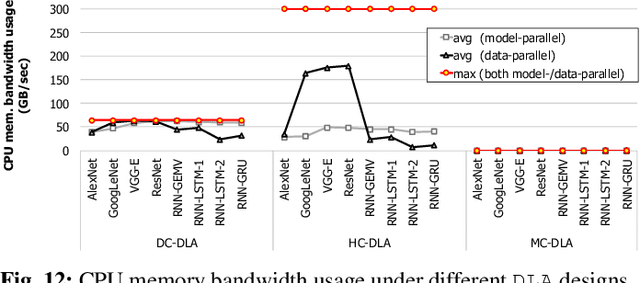
As the models and the datasets to train deep learning (DL) models scale, system architects are faced with new challenges, one of which is the memory capacity bottleneck, where the limited physical memory inside the accelerator device constrains the algorithm that can be studied. We propose a memory-centric deep learning system that can transparently expand the memory capacity available to the accelerators while also providing fast inter-device communication for parallel training. Our proposal aggregates a pool of memory modules locally within the device-side interconnect, which are decoupled from the host interface and function as a vehicle for transparent memory capacity expansion. Compared to conventional systems, our proposal achieves an average 2.8x speedup on eight DL applications and increases the system-wide memory capacity to tens of TBs.