 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorDIMM: A Practical Near-Memory Processing Architecture for Embeddings and Tensor Operations in Deep Learning
Paper and Code
Aug 25, 2019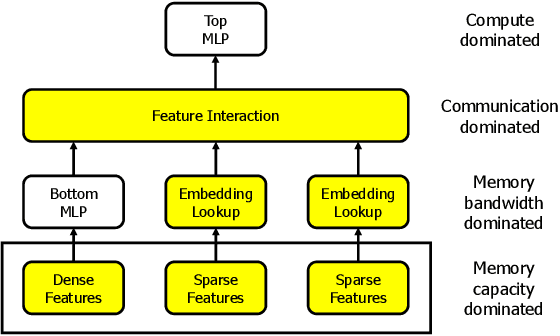

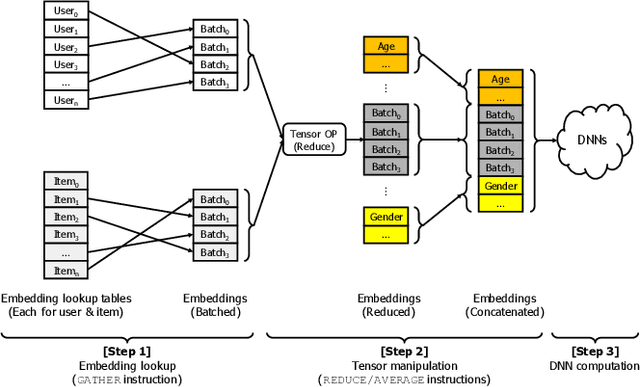
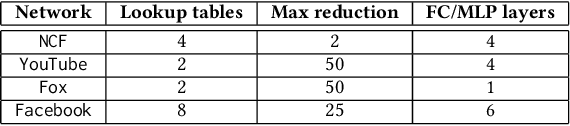
Recent studies from several hyperscalars pinpoint to embedding layers as the most memory-intensive deep learning (DL) algorithm being deployed in today's datacenters. This paper addresses the memory capacity and bandwidth challenges of embedding layers and the associated tensor operations. We present our vertically integrated hardware/software co-design, which includes a custom DIMM module enhanced with near-data processing cores tailored for DL tensor operations. These custom DIMMs are populated inside a GPU-centric system interconnect as a remote memory pool, allowing GPUs to utilize for scalable memory bandwidth and capacity expansion. A prototype implementation of our proposal on real DL systems shows an average 6.2-17.6x performance improvement on state-of-the-art recommender systems.