 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebunking the CUDA Myth Towards GPU-based AI Systems
Dec 31, 2024



With the rise of AI, NVIDIA GPUs have become the de facto standard for AI system design. This paper presents a comprehensive evaluation of Intel Gaudi NPUs as an alternative to NVIDIA GPUs for AI model serving. First, we create a suite of microbenchmarks to compare Intel Gaudi-2 with NVIDIA A100, showing that Gaudi-2 achieves competitive performance not only in primitive AI compute, memory, and communication operations but also in executing several important AI workloads end-to-end. We then assess Gaudi NPU's programmability by discussing several software-level optimization strategies to employ for implementing critical FBGEMM operators and vLLM, evaluating their efficiency against GPU-optimized counterparts. Results indicate that Gaudi-2 achieves energy efficiency comparable to A100, though there are notable areas for improvement in terms of software maturity. Overall, we conclude that, with effective integration into high-level AI frameworks, Gaudi NPUs could challenge NVIDIA GPU's dominance in the AI server market, though further improvements are necessary to fully compete with NVIDIA's robust software ecosystem.
PreSto: An In-Storage Data Preprocessing System for Training Recommendation Models
Jun 11, 2024Training recommendation systems (RecSys) faces several challenges as it requires the "data preprocessing" stage to preprocess an ample amount of raw data and feed them to the GPU for training in a seamless manner. To sustain high training throughput, state-of-the-art solutions reserve a large fleet of CPU servers for preprocessing which incurs substantial deployment cost and power consumption. Our characterization reveals that prior CPU-centric preprocessing is bottlenecked on feature generation and feature normalization operations as it fails to reap out the abundant inter-/intra-feature parallelism in RecSys preprocessing. PreSto is a storage-centric preprocessing system leveraging In-Storage Processing (ISP), which offloads the bottlenecked preprocessing operations to our ISP units. We show that PreSto outperforms the baseline CPU-centric system with a $9.6\times$ speedup in end-to-end preprocessing time, $4.3\times$ enhancement in cost-efficiency, and $11.3\times$ improvement in energyefficiency on average for production-scale RecSys preprocessing.
SmartSAGE: Training Large-scale Graph Neural Networks using In-Storage Processing Architectures
May 10, 2022
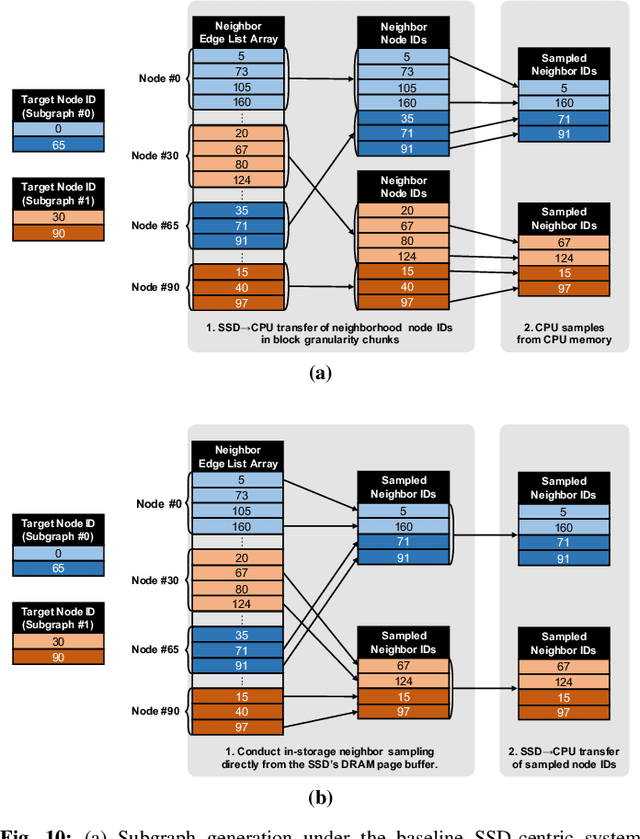
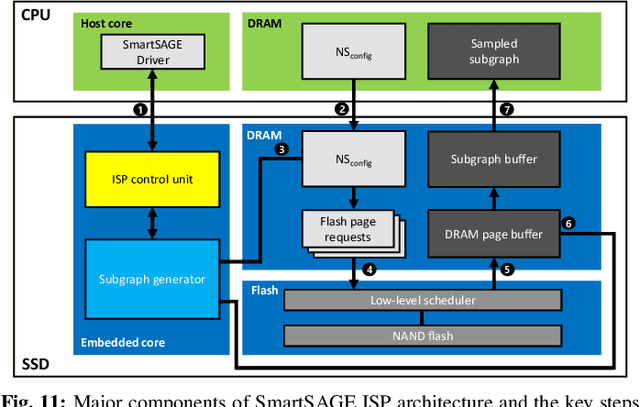
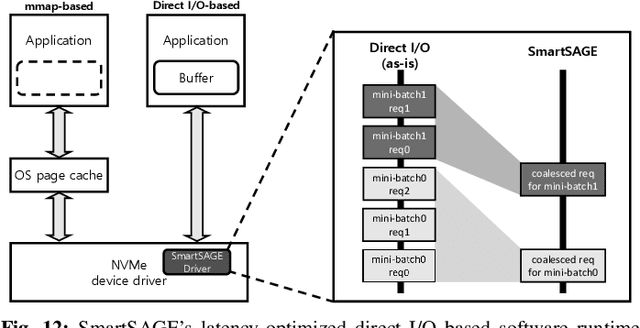
Graph neural networks (GNNs) can extract features by learning both the representation of each objects (i.e., graph nodes) and the relationship across different objects (i.e., the edges that connect nodes), achieving state-of-the-art performance in various graph-based tasks. Despite its strengths, utilizing these algorithms in a production environment faces several challenges as the number of graph nodes and edges amount to several billions to hundreds of billions scale, requiring substantial storage space for training. Unfortunately, state-of-the-art ML frameworks employ an in-memory processing model which significantly hampers the productivity of ML practitioners as it mandates the overall working set to fit within DRAM capacity. In this work, we first conduct a detailed characterization on a state-of-the-art, large-scale GNN training algorithm, GraphSAGE. Based on the characterization, we then explore the feasibility of utilizing capacity-optimized NVM SSDs for storing memory-hungry GNN data, which enables large-scale GNN training beyond the limits of main memory size. Given the large performance gap between DRAM and SSD, however, blindly utilizing SSDs as a direct substitute for DRAM leads to significant performance loss. We therefore develop SmartSAGE, our software/hardware co-design based on an in-storage processing (ISP) architecture. Our work demonstrates that an ISP based large-scale GNN training system can achieve both high capacity storage and high performance, opening up opportunities for ML practitioners to train large GNN datasets without being hampered by the physical limitations of main memory size.
Tensor Casting: Co-Designing Algorithm-Architecture for Personalized Recommendation Training
Oct 25, 2020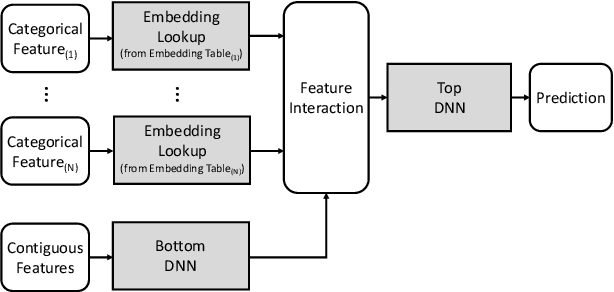
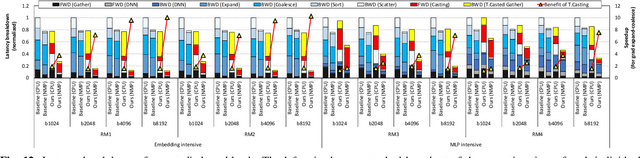
Personalized recommendations are one of the most widely deployed machine learning (ML) workload serviced from cloud datacenters. As such, architectural solutions for high-performance recommendation inference have recently been the target of several prior literatures. Unfortunately, little have been explored and understood regarding the training side of this emerging ML workload. In this paper, we first perform a detailed workload characterization study on training recommendations, root-causing sparse embedding layer training as one of the most significant performance bottlenecks. We then propose our algorithm-architecture co-design called Tensor Casting, which enables the development of a generic accelerator architecture for tensor gather-scatter that encompasses all the key primitives of training embedding layers. When prototyped on a real CPU-GPU system, Tensor Casting provides 1.9-21x improvements in training throughput compared to state-of-the-art approaches.
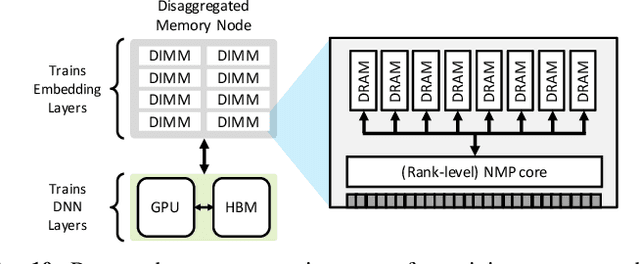
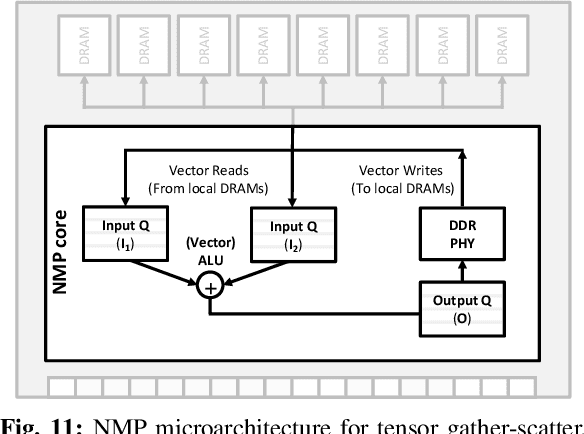
TensorDIMM: A Practical Near-Memory Processing Architecture for Embeddings and Tensor Operations in Deep Learning
Aug 25, 2019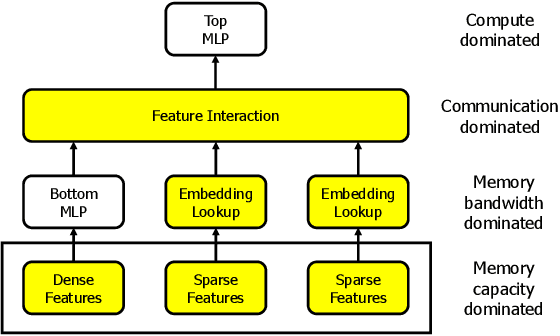

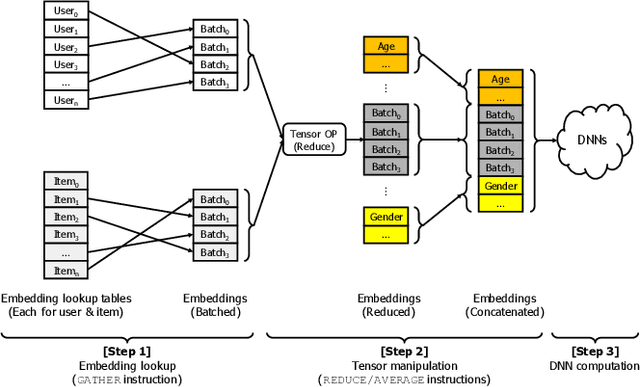
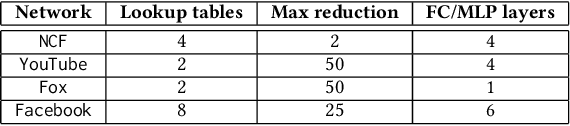
Recent studies from several hyperscalars pinpoint to embedding layers as the most memory-intensive deep learning (DL) algorithm being deployed in today's datacenters. This paper addresses the memory capacity and bandwidth challenges of embedding layers and the associated tensor operations. We present our vertically integrated hardware/software co-design, which includes a custom DIMM module enhanced with near-data processing cores tailored for DL tensor operations. These custom DIMMs are populated inside a GPU-centric system interconnect as a remote memory pool, allowing GPUs to utilize for scalable memory bandwidth and capacity expansion. A prototype implementation of our proposal on real DL systems shows an average 6.2-17.6x performance improvement on state-of-the-art recommender systems.