 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartSAGE: Training Large-scale Graph Neural Networks using In-Storage Processing Architectures
Paper and Code
May 10, 2022
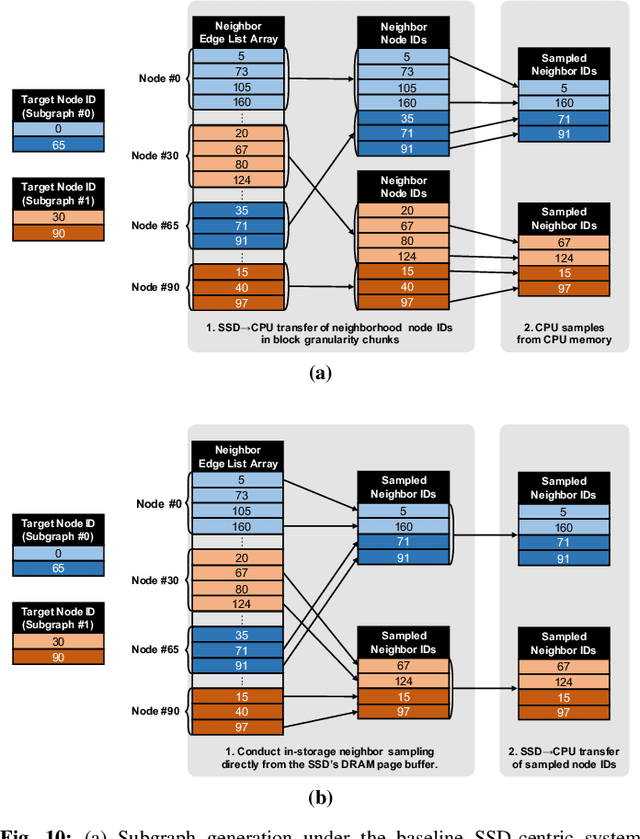
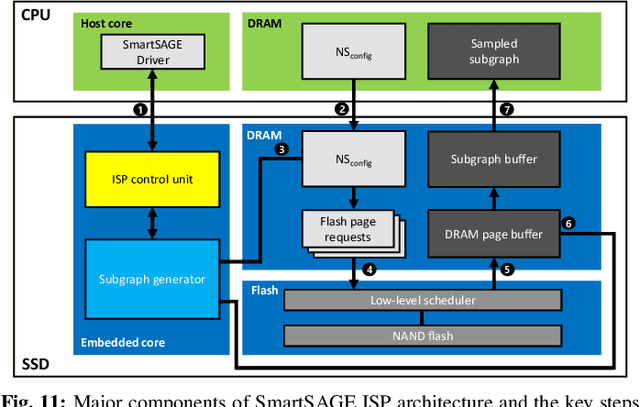
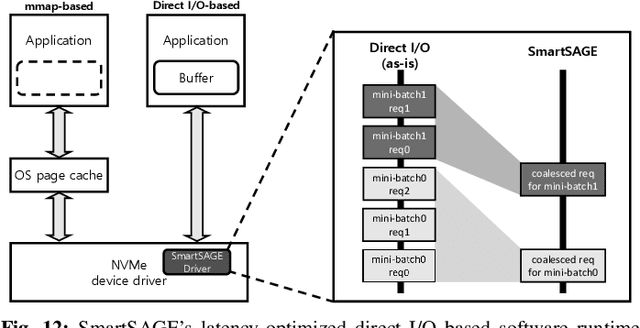
Graph neural networks (GNNs) can extract features by learning both the representation of each objects (i.e., graph nodes) and the relationship across different objects (i.e., the edges that connect nodes), achieving state-of-the-art performance in various graph-based tasks. Despite its strengths, utilizing these algorithms in a production environment faces several challenges as the number of graph nodes and edges amount to several billions to hundreds of billions scale, requiring substantial storage space for training. Unfortunately, state-of-the-art ML frameworks employ an in-memory processing model which significantly hampers the productivity of ML practitioners as it mandates the overall working set to fit within DRAM capacity. In this work, we first conduct a detailed characterization on a state-of-the-art, large-scale GNN training algorithm, GraphSAGE. Based on the characterization, we then explore the feasibility of utilizing capacity-optimized NVM SSDs for storing memory-hungry GNN data, which enables large-scale GNN training beyond the limits of main memory size. Given the large performance gap between DRAM and SSD, however, blindly utilizing SSDs as a direct substitute for DRAM leads to significant performance loss. We therefore develop SmartSAGE, our software/hardware co-design based on an in-storage processing (ISP) architecture. Our work demonstrates that an ISP based large-scale GNN training system can achieve both high capacity storage and high performance, opening up opportunities for ML practitioners to train large GNN datasets without being hampered by the physical limitations of main memory size.