 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Preference Alignment: Diffusion Models at Nash Equilibrium
May 06, 2026Reinforcement learning from human feedback (RLHF) has been popular for aligning text-to-image (T2I) diffusion models with human preferences. As a mainstream branch of RLHF, Direct Preference Optimization (DPO) offers a computationally efficient alternative that avoids explicit reward modeling and has been widely adopted in diffusion alignment. However, existing preference-based methods for diffusion alignment still rely on reward-induced preference signals and typically assume that human preferences can be adequately modeled by the Bradley--Terry (BT) model, which may fail to capture the full complexity of human preferences. In this paper, we formulate diffusion alignment from a game-theoretic perspective. We propose Diffusion Nash Preference Optimization (Diff.-NPO), an intuitive general preference framework for diffusion alignment. Diff.-NPO encourages the current policy to play against itself to achieve self improvement and lead to a better alignment. Empirically, we demonstrate the effectiveness of Diff.-NPO on the text-to-image generation task via various metrics. Diff.-NPO consistently outperforms existing preference-based diffusion alignment methods.
Accurate and Scalable Matrix Mechanisms via Divide and Conquer
Apr 01, 2026Matrix mechanisms are often used to provide unbiased differentially private query answers when publishing statistics or creating synthetic data. Recent work has developed matrix mechanisms, such as ResidualPlanner and Weighted Fourier Factorizations, that scale to high dimensional datasets while providing optimality guarantees for workloads such as marginals and circular product queries. They operate by adding noise to a linearly independent set of queries that can compactly represent the desired workloads. In this paper, we present QuerySmasher, an alternative scalable approach based on a divide-and-conquer strategy. Given a workload that can be answered from various data marginals, QuerySmasher splits each query into sub-queries and re-assembles the pieces into mutually orthogonal sub-workloads. These sub-workloads represent small, low-dimensional problems that can be independently and optimally answered by existing low-dimensional matrix mechanisms. QuerySmasher then stitches these solutions together to answer queries in the original workload. We show that QuerySmasher subsumes prior work, like ResidualPlanner (RP), ResidualPlanner+ (RP+), and Weighted Fourier Factorizations (WFF). We prove that it can dominate those approaches, under sum squared error, for all workloads. We also experimentally demonstrate the scalability and accuracy of QuerySmasher.
Towards Better Optimization For Listwise Preference in Diffusion Models
Oct 02, 2025



Reinforcement learning from human feedback (RLHF) has proven effectiveness for aligning text-to-image (T2I) diffusion models with human preferences. Although Direct Preference Optimization (DPO) is widely adopted for its computational efficiency and avoidance of explicit reward modeling, its applications to diffusion models have primarily relied on pairwise preferences. The precise optimization of listwise preferences remains largely unaddressed. In practice, human feedback on image preferences often contains implicit ranked information, which conveys more precise human preferences than pairwise comparisons. In this work, we propose Diffusion-LPO, a simple and effective framework for Listwise Preference Optimization in diffusion models with listwise data. Given a caption, we aggregate user feedback into a ranked list of images and derive a listwise extension of the DPO objective under the Plackett-Luce model. Diffusion-LPO enforces consistency across the entire ranking by encouraging each sample to be preferred over all of its lower-ranked alternatives. We empirically demonstrate the effectiveness of Diffusion-LPO across various tasks, including text-to-image generation, image editing, and personalized preference alignment. Diffusion-LPO consistently outperforms pairwise DPO baselines on visual quality and preference alignment.
Federated Fine-tuning of Large Language Models under Heterogeneous Language Tasks and Client Resources
Feb 18, 2024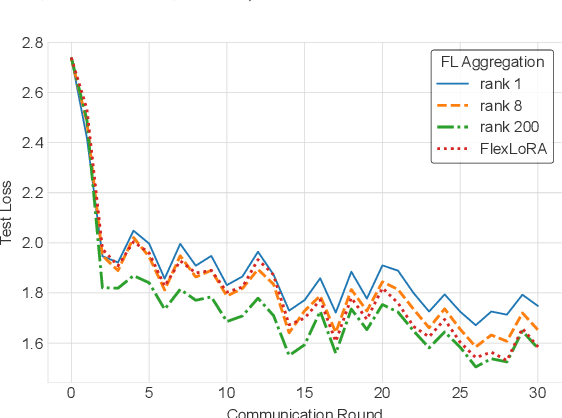

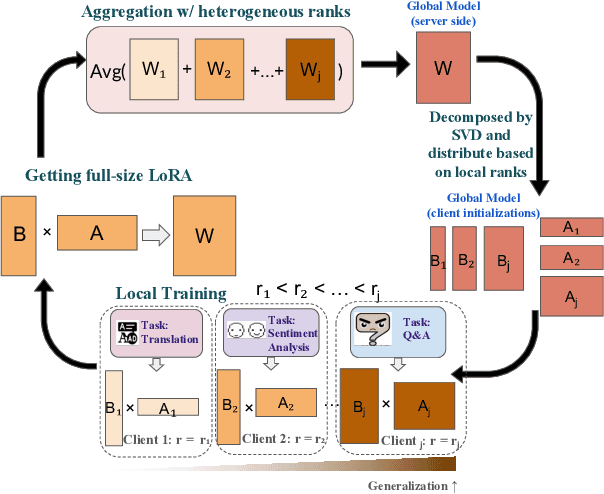
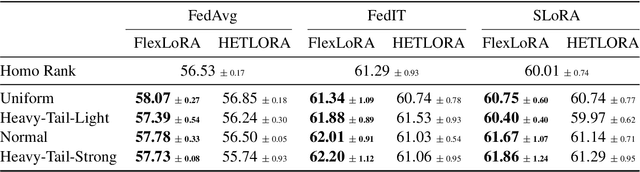
Federated Learning (FL) has recently been applied to the parameter-efficient fine-tuning of Large Language Models (LLMs). While promising, it raises significant challenges due to the heterogeneous resources and data distributions of clients.This study introduces FlexLoRA, a simple yet effective aggregation scheme for LLM fine-tuning, which mitigates the "buckets effect" in traditional FL that restricts the potential of clients with ample resources by tying them to the capabilities of the least-resourced participants. FlexLoRA allows for dynamic adjustment of local LoRA ranks, fostering the development of a global model imbued with broader, less task-specific knowledge. By synthesizing a full-size LoRA weight from individual client contributions and employing Singular Value Decomposition (SVD) for weight redistribution, FlexLoRA fully leverages heterogeneous client resources. Involving over 1,600 clients performing diverse NLP tasks, our experiments validate the efficacy of FlexLoRA, with the federated global model achieving up to a 3.1% average improvement in downstream NLP task performance. FlexLoRA's practicality is further underscored by its seamless integration with existing LoRA-based FL methods and theoretical analysis, offering a path toward scalable, privacy-preserving federated tuning for LLMs.
Among Us: Adversarially Robust Collaborative Perception by Consensus
Mar 27, 2023
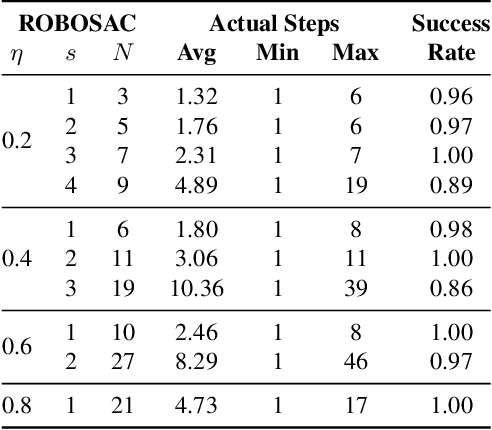
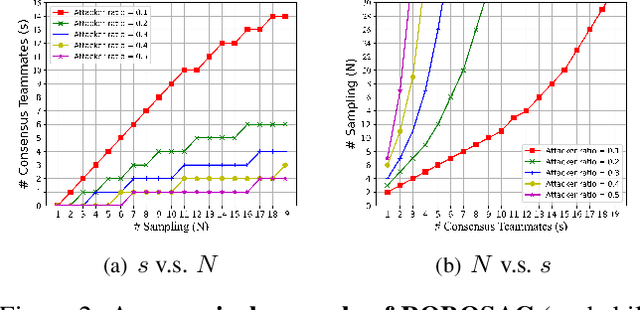

Multiple robots could perceive a scene (e.g., detect objects) collaboratively better than individuals, although easily suffer from adversarial attacks when using deep learning. This could be addressed by the adversarial defense, but its training requires the often-unknown attacking mechanism. Differently, we propose ROBOSAC, a novel sampling-based defense strategy generalizable to unseen attackers. Our key idea is that collaborative perception should lead to consensus rather than dissensus in results compared to individual perception. This leads to our hypothesize-and-verify framework: perception results with and without collaboration from a random subset of teammates are compared until reaching a consensus. In such a framework, more teammates in the sampled subset often entail better perception performance but require longer sampling time to reject potential attackers. Thus, we derive how many sampling trials are needed to ensure the desired size of an attacker-free subset, or equivalently, the maximum size of such a subset that we can successfully sample within a given number of trials. We validate our method on the task of collaborative 3D object detection in autonomous driving scenarios.