 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Fine-tuning of Large Language Models under Heterogeneous Language Tasks and Client Resources
Paper and Code
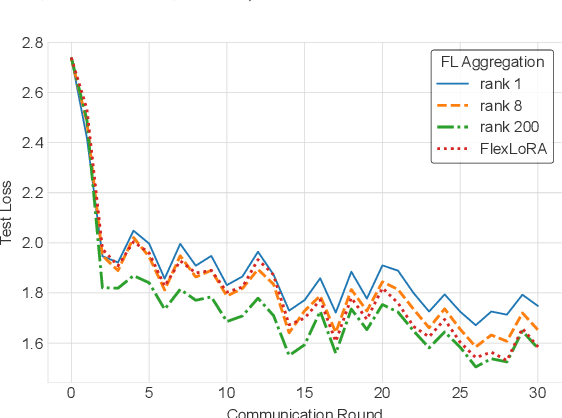

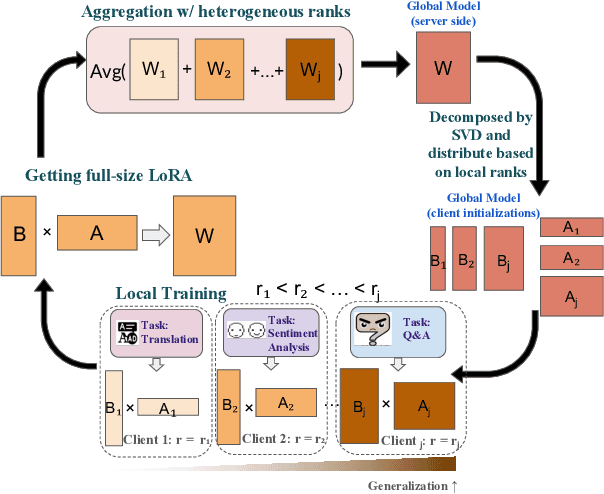
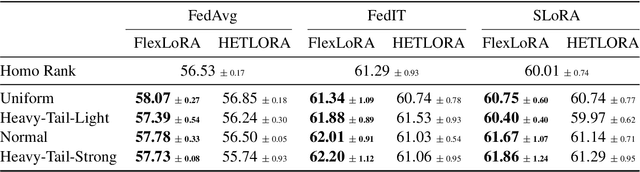
Federated Learning (FL) has recently been applied to the parameter-efficient fine-tuning of Large Language Models (LLMs). While promising, it raises significant challenges due to the heterogeneous resources and data distributions of clients.This study introduces FlexLoRA, a simple yet effective aggregation scheme for LLM fine-tuning, which mitigates the "buckets effect" in traditional FL that restricts the potential of clients with ample resources by tying them to the capabilities of the least-resourced participants. FlexLoRA allows for dynamic adjustment of local LoRA ranks, fostering the development of a global model imbued with broader, less task-specific knowledge. By synthesizing a full-size LoRA weight from individual client contributions and employing Singular Value Decomposition (SVD) for weight redistribution, FlexLoRA fully leverages heterogeneous client resources. Involving over 1,600 clients performing diverse NLP tasks, our experiments validate the efficacy of FlexLoRA, with the federated global model achieving up to a 3.1% average improvement in downstream NLP task performance. FlexLoRA's practicality is further underscored by its seamless integration with existing LoRA-based FL methods and theoretical analysis, offering a path toward scalable, privacy-preserving federated tuning for LLMs.