 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-based Models for Vertical Federated Learning: A Survey
Apr 03, 2025Tree-based models have achieved great success in a wide range of real-world applications due to their effectiveness, robustness, and interpretability, which inspired people to apply them in vertical federated learning (VFL) scenarios in recent years. In this paper, we conduct a comprehensive study to give an overall picture of applying tree-based models in VFL, from the perspective of their communication and computation protocols. We categorize tree-based models in VFL into two types, i.e., feature-gathering models and label-scattering models, and provide a detailed discussion regarding their characteristics, advantages, privacy protection mechanisms, and applications. This study also focuses on the implementation of tree-based models in VFL, summarizing several design principles for better satisfying various requirements from both academic research and industrial deployment. We conduct a series of experiments to provide empirical observations on the differences and advances of different types of tree-based models.
KIMAs: A Configurable Knowledge Integrated Multi-Agent System
Feb 13, 2025Knowledge-intensive conversations supported by large language models (LLMs) have become one of the most popular and helpful applications that can assist people in different aspects. Many current knowledge-intensive applications are centered on retrieval-augmented generation (RAG) techniques. While many open-source RAG frameworks facilitate the development of RAG-based applications, they often fall short in handling practical scenarios complicated by heterogeneous data in topics and formats, conversational context management, and the requirement of low-latency response times. This technical report presents a configurable knowledge integrated multi-agent system, KIMAs, to address these challenges. KIMAs features a flexible and configurable system for integrating diverse knowledge sources with 1) context management and query rewrite mechanisms to improve retrieval accuracy and multi-turn conversational coherency, 2) efficient knowledge routing and retrieval, 3) simple but effective filter and reference generation mechanisms, and 4) optimized parallelizable multi-agent pipeline execution. Our work provides a scalable framework for advancing the deployment of LLMs in real-world settings. To show how KIMAs can help developers build knowledge-intensive applications with different scales and emphases, we demonstrate how we configure the system to three applications already running in practice with reliable performance.
AgentScope: A Flexible yet Robust Multi-Agent Platform
Feb 21, 2024With the rapid advancement of Large Language Models (LLMs), significant progress has been made in multi-agent applications. However, the complexities in coordinating agents' cooperation and LLMs' erratic performance pose notable challenges in developing robust and efficient multi-agent applications. To tackle these challenges, we propose AgentScope, a developer-centric multi-agent platform with message exchange as its core communication mechanism. Together with abundant syntactic tools, built-in resources, and user-friendly interactions, our communication mechanism significantly reduces the barriers to both development and understanding. Towards robust and flexible multi-agent application, AgentScope provides both built-in and customizable fault tolerance mechanisms while it is also armed with system-level supports for multi-modal data generation, storage and transmission. Additionally, we design an actor-based distribution framework, enabling easy conversion between local and distributed deployments and automatic parallel optimization without extra effort. With these features, AgentScope empowers developers to build applications that fully realize the potential of intelligent agents. We have released AgentScope at https://github.com/modelscope/agentscope, and hope AgentScope invites wider participation and innovation in this fast-moving field.
Federated Fine-tuning of Large Language Models under Heterogeneous Language Tasks and Client Resources
Feb 18, 2024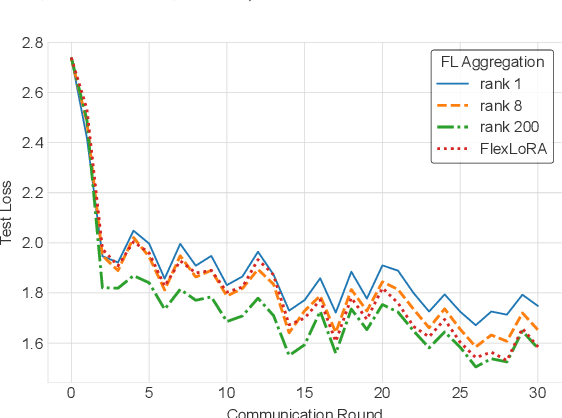

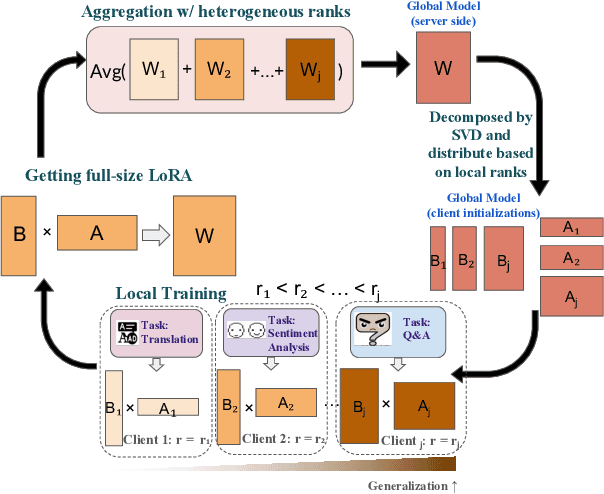
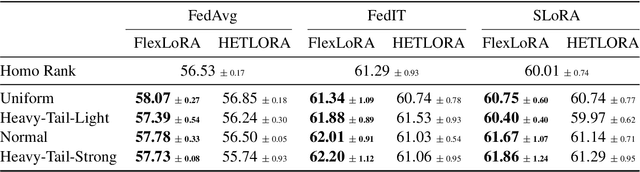
Federated Learning (FL) has recently been applied to the parameter-efficient fine-tuning of Large Language Models (LLMs). While promising, it raises significant challenges due to the heterogeneous resources and data distributions of clients.This study introduces FlexLoRA, a simple yet effective aggregation scheme for LLM fine-tuning, which mitigates the "buckets effect" in traditional FL that restricts the potential of clients with ample resources by tying them to the capabilities of the least-resourced participants. FlexLoRA allows for dynamic adjustment of local LoRA ranks, fostering the development of a global model imbued with broader, less task-specific knowledge. By synthesizing a full-size LoRA weight from individual client contributions and employing Singular Value Decomposition (SVD) for weight redistribution, FlexLoRA fully leverages heterogeneous client resources. Involving over 1,600 clients performing diverse NLP tasks, our experiments validate the efficacy of FlexLoRA, with the federated global model achieving up to a 3.1% average improvement in downstream NLP task performance. FlexLoRA's practicality is further underscored by its seamless integration with existing LoRA-based FL methods and theoretical analysis, offering a path toward scalable, privacy-preserving federated tuning for LLMs.
Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Dec 26, 2023

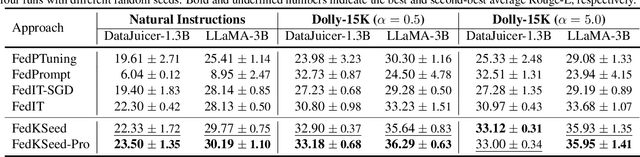

Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.
FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning
Sep 01, 2023

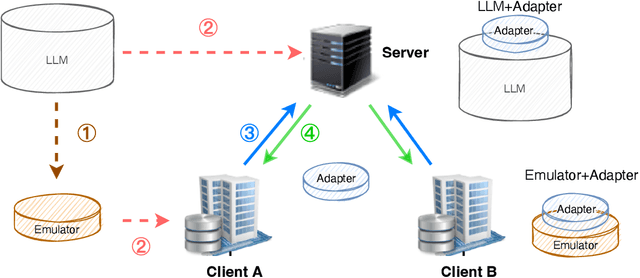
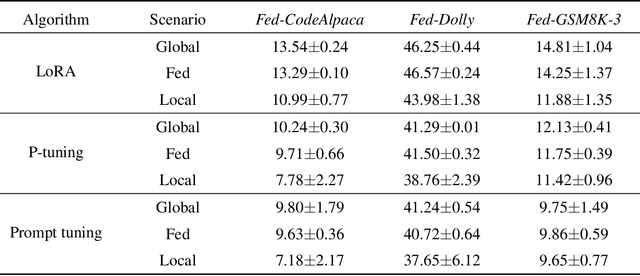
LLMs have demonstrated great capabilities in various NLP tasks. Different entities can further improve the performance of those LLMs on their specific downstream tasks by fine-tuning LLMs. When several entities have similar interested tasks, but their data cannot be shared because of privacy concerns regulations, federated learning (FL) is a mainstream solution to leverage the data of different entities. However, fine-tuning LLMs in federated learning settings still lacks adequate support from existing FL frameworks because it has to deal with optimizing the consumption of significant communication and computational resources, data preparation for different tasks, and distinct information protection demands. This paper first discusses these challenges of federated fine-tuning LLMs, and introduces our package FS-LLM as a main contribution, which consists of the following components: (1) we build an end-to-end benchmarking pipeline, automizing the processes of dataset preprocessing, federated fine-tuning execution, and performance evaluation on federated LLM fine-tuning; (2) we provide comprehensive federated parameter-efficient fine-tuning algorithm implementations and versatile programming interfaces for future extension in FL scenarios with low communication and computation costs, even without accessing the full model; (3) we adopt several accelerating and resource-efficient operators for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study. We conduct extensive experiments to validate the effectiveness of FS-LLM and benchmark advanced LLMs with state-of-the-art parameter-efficient fine-tuning algorithms in FL settings, which also yields valuable insights into federated fine-tuning LLMs for the research community. To facilitate further research and adoption, we release FS-LLM at https://github.com/alibaba/FederatedScope/tree/llm.