 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning
Paper and Code


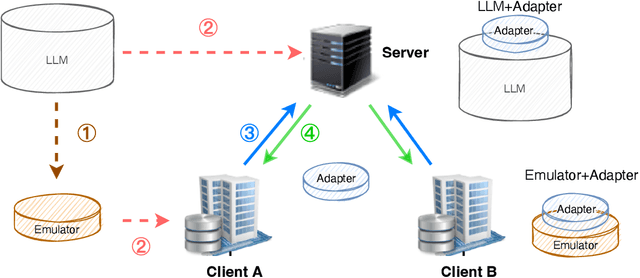
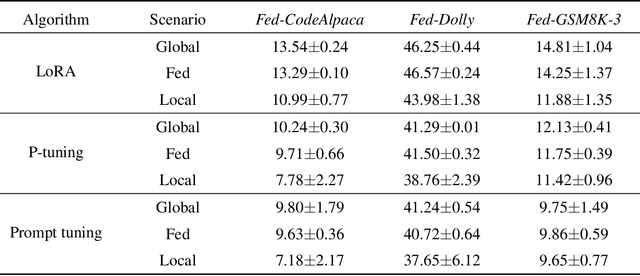
LLMs have demonstrated great capabilities in various NLP tasks. Different entities can further improve the performance of those LLMs on their specific downstream tasks by fine-tuning LLMs. When several entities have similar interested tasks, but their data cannot be shared because of privacy concerns regulations, federated learning (FL) is a mainstream solution to leverage the data of different entities. However, fine-tuning LLMs in federated learning settings still lacks adequate support from existing FL frameworks because it has to deal with optimizing the consumption of significant communication and computational resources, data preparation for different tasks, and distinct information protection demands. This paper first discusses these challenges of federated fine-tuning LLMs, and introduces our package FS-LLM as a main contribution, which consists of the following components: (1) we build an end-to-end benchmarking pipeline, automizing the processes of dataset preprocessing, federated fine-tuning execution, and performance evaluation on federated LLM fine-tuning; (2) we provide comprehensive federated parameter-efficient fine-tuning algorithm implementations and versatile programming interfaces for future extension in FL scenarios with low communication and computation costs, even without accessing the full model; (3) we adopt several accelerating and resource-efficient operators for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study. We conduct extensive experiments to validate the effectiveness of FS-LLM and benchmark advanced LLMs with state-of-the-art parameter-efficient fine-tuning algorithms in FL settings, which also yields valuable insights into federated fine-tuning LLMs for the research community. To facilitate further research and adoption, we release FS-LLM at https://github.com/alibaba/FederatedScope/tree/llm.