 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
May 23, 2025Trinity-RFT is a general-purpose, flexible and scalable framework designed for reinforcement fine-tuning (RFT) of large language models. It is built with a decoupled design, consisting of (1) an RFT-core that unifies and generalizes synchronous/asynchronous, on-policy/off-policy, and online/offline modes of RFT, (2) seamless integration for agent-environment interaction with high efficiency and robustness, and (3) systematic data pipelines optimized for RFT. Trinity-RFT can be easily adapted for diverse application scenarios, and serves as a unified platform for exploring advanced reinforcement learning paradigms. This technical report outlines the vision, features, design and implementations of Trinity-RFT, accompanied by extensive examples demonstrating the utility and user-friendliness of the proposed framework.
Do we Really Need Visual Instructions? Towards Visual Instruction-Free Fine-tuning for Large Vision-Language Models
Feb 17, 2025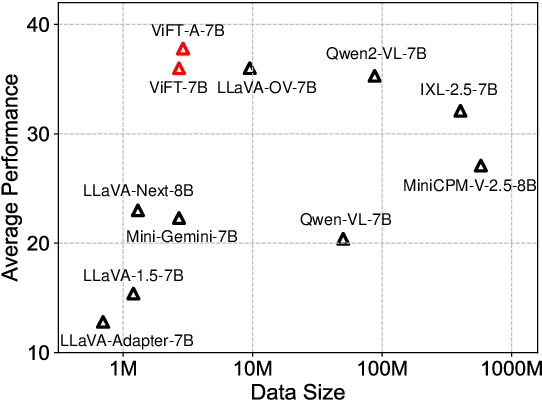
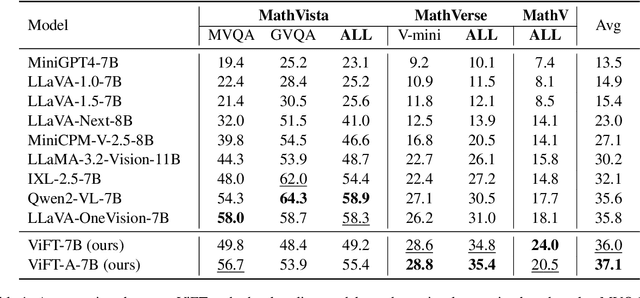
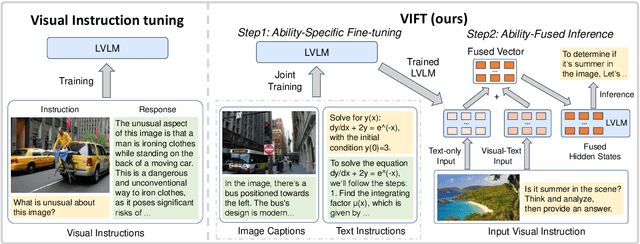
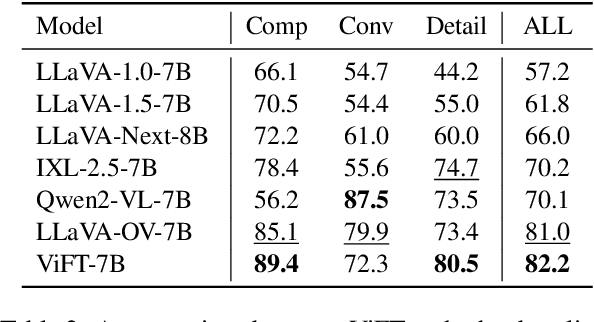
Visual instruction tuning has become the predominant technology in eliciting the multimodal task-solving capabilities of large vision-language models (LVLMs). Despite the success, as visual instructions require images as the input, it would leave the gap in inheriting the task-solving capabilities from the backbone LLMs, and make it costly to collect a large-scale dataset. To address it, we propose ViFT, a visual instruction-free fine-tuning framework for LVLMs. In ViFT, we only require the text-only instructions and image caption data during training, to separately learn the task-solving and visual perception abilities. During inference, we extract and combine the representations of the text and image inputs, for fusing the two abilities to fulfill multimodal tasks. Experimental results demonstrate that ViFT can achieve state-of-the-art performance on several visual reasoning and visual instruction following benchmarks, with rather less training data. Our code and data will be publicly released.
KIMAs: A Configurable Knowledge Integrated Multi-Agent System
Feb 13, 2025Knowledge-intensive conversations supported by large language models (LLMs) have become one of the most popular and helpful applications that can assist people in different aspects. Many current knowledge-intensive applications are centered on retrieval-augmented generation (RAG) techniques. While many open-source RAG frameworks facilitate the development of RAG-based applications, they often fall short in handling practical scenarios complicated by heterogeneous data in topics and formats, conversational context management, and the requirement of low-latency response times. This technical report presents a configurable knowledge integrated multi-agent system, KIMAs, to address these challenges. KIMAs features a flexible and configurable system for integrating diverse knowledge sources with 1) context management and query rewrite mechanisms to improve retrieval accuracy and multi-turn conversational coherency, 2) efficient knowledge routing and retrieval, 3) simple but effective filter and reference generation mechanisms, and 4) optimized parallelizable multi-agent pipeline execution. Our work provides a scalable framework for advancing the deployment of LLMs in real-world settings. To show how KIMAs can help developers build knowledge-intensive applications with different scales and emphases, we demonstrate how we configure the system to three applications already running in practice with reliable performance.
GenSim: A General Social Simulation Platform with Large Language Model based Agents
Oct 06, 2024

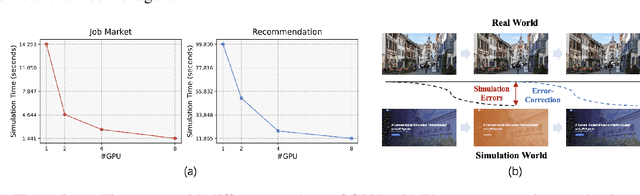

With the rapid advancement of large language models (LLMs), recent years have witnessed many promising studies on leveraging LLM-based agents to simulate human social behavior. While prior work has demonstrated significant potential across various domains, much of it has focused on specific scenarios involving a limited number of agents and has lacked the ability to adapt when errors occur during simulation. To overcome these limitations, we propose a novel LLM-agent-based simulation platform called \textit{GenSim}, which: (1) \textbf{Abstracts a set of general functions} to simplify the simulation of customized social scenarios; (2) \textbf{Supports one hundred thousand agents} to better simulate large-scale populations in real-world contexts; (3) \textbf{Incorporates error-correction mechanisms} to ensure more reliable and long-term simulations. To evaluate our platform, we assess both the efficiency of large-scale agent simulations and the effectiveness of the error-correction mechanisms. To our knowledge, GenSim represents an initial step toward a general, large-scale, and correctable social simulation platform based on LLM agents, promising to further advance the field of social science.
Neural Network-Assisted Hybrid Model Based Message Passing for Parametric Holographic MIMO Near Field Channel Estimation
Aug 29, 2024



Holographic multiple-input and multiple-output (HMIMO) is a promising technology with the potential to achieve high energy and spectral efficiencies, enhance system capacity and diversity, etc. In this work, we address the challenge of HMIMO near field (NF) channel estimation, which is complicated by the intricate model introduced by the dyadic Green's function. Despite its complexity, the channel model is governed by a limited set of parameters. This makes parametric channel estimation highly attractive, offering substantial performance enhancements and enabling the extraction of valuable sensing parameters, such as user locations, which are particularly beneficial in mobile networks. However, the relationship between these parameters and channel gains is nonlinear and compounded by integration, making the estimation a formidable task. To tackle this problem, we propose a novel neural network (NN) assisted hybrid method. With the assistance of NNs, we first develop a novel hybrid channel model with a significantly simplified expression compared to the original one, thereby enabling parametric channel estimation. Using the readily available training data derived from the original channel model, the NNs in the hybrid channel model can be effectively trained offline. Then, building upon this hybrid channel model, we formulate the parametric channel estimation problem with a probabilistic framework and design a factor graph representation for Bayesian estimation. Leveraging the factor graph representation and unitary approximate message passing (UAMP), we develop an effective message passing-based Bayesian channel estimation algorithm. Extensive simulations demonstrate the superior performance of the proposed method.
Very Large-Scale Multi-Agent Simulation in AgentScope
Jul 25, 2024Recent advances in large language models (LLMs) have opened new avenues for applying multi-agent systems in very large-scale simulations. However, there remain several challenges when conducting multi-agent simulations with existing platforms, such as limited scalability and low efficiency, unsatisfied agent diversity, and effort-intensive management processes. To address these challenges, we develop several new features and components for AgentScope, a user-friendly multi-agent platform, enhancing its convenience and flexibility for supporting very large-scale multi-agent simulations. Specifically, we propose an actor-based distributed mechanism as the underlying technological infrastructure towards great scalability and high efficiency, and provide flexible environment support for simulating various real-world scenarios, which enables parallel execution of multiple agents, centralized workflow orchestration, and both inter-agent and agent-environment interactions among agents. Moreover, we integrate an easy-to-use configurable tool and an automatic background generation pipeline in AgentScope, simplifying the process of creating agents with diverse yet detailed background settings. Last but not least, we provide a web-based interface for conveniently monitoring and managing a large number of agents that might deploy across multiple devices. We conduct a comprehensive simulation to demonstrate the effectiveness of the proposed enhancements in AgentScope, and provide detailed observations and discussions to highlight the great potential of applying multi-agent systems in large-scale simulations. The source code is released on GitHub at https://github.com/modelscope/agentscope to inspire further research and development in large-scale multi-agent simulations.
Less is More: Data Value Estimation for Visual Instruction Tuning
Mar 21, 2024Visual instruction tuning is the key to building multimodal large language models (MLLMs), which greatly improves the reasoning capabilities of large language models (LLMs) in vision scenario. However, existing MLLMs mostly rely on a mixture of multiple highly diverse visual instruction datasets for training (even more than a million instructions), which may introduce data redundancy. To investigate this issue, we conduct a series of empirical studies, which reveal a significant redundancy within the visual instruction datasets, and show that greatly reducing the amount of several instruction dataset even do not affect the performance. Based on the findings, we propose a new data selection approach TIVE, to eliminate redundancy within visual instruction data. TIVE first estimates the task-level and instance-level value of the visual instructions based on computed gradients. Then, according to the estimated values, TIVE determines the task proportion within the visual instructions, and selects representative instances to compose a smaller visual instruction subset for training. Experiments on LLaVA-1.5 show that our approach using only about 7.5% data can achieve comparable performance as the full-data fine-tuned model across seven benchmarks, even surpassing it on four of the benchmarks. Our code and data will be publicly released.
AgentScope: A Flexible yet Robust Multi-Agent Platform
Feb 21, 2024With the rapid advancement of Large Language Models (LLMs), significant progress has been made in multi-agent applications. However, the complexities in coordinating agents' cooperation and LLMs' erratic performance pose notable challenges in developing robust and efficient multi-agent applications. To tackle these challenges, we propose AgentScope, a developer-centric multi-agent platform with message exchange as its core communication mechanism. Together with abundant syntactic tools, built-in resources, and user-friendly interactions, our communication mechanism significantly reduces the barriers to both development and understanding. Towards robust and flexible multi-agent application, AgentScope provides both built-in and customizable fault tolerance mechanisms while it is also armed with system-level supports for multi-modal data generation, storage and transmission. Additionally, we design an actor-based distribution framework, enabling easy conversion between local and distributed deployments and automatic parallel optimization without extra effort. With these features, AgentScope empowers developers to build applications that fully realize the potential of intelligent agents. We have released AgentScope at https://github.com/modelscope/agentscope, and hope AgentScope invites wider participation and innovation in this fast-moving field.
Data-CUBE: Data Curriculum for Instruction-based Sentence Representation Learning
Jan 07, 2024



Recently, multi-task instruction tuning has been applied into sentence representation learning, which endows the capability of generating specific representations with the guidance of task instruction, exhibiting strong generalization ability on new tasks. However, these methods mostly neglect the potential interference problems across different tasks and instances, which may affect the training and convergence of the model. To address it, we propose a data curriculum method, namely Data-CUBE, that arranges the orders of all the multi-task data for training, to minimize the interference risks from the two views. In the task level, we aim to find the optimal task order to minimize the total cross-task interference risk, which is exactly the traveling salesman problem, hence we utilize a simulated annealing algorithm to find its solution. In the instance level, we measure the difficulty of all instances per task, then divide them into the easy-to-difficult mini-batches for training. Experiments on MTEB sentence representation evaluation tasks show that our approach can boost the performance of state-of-the-art methods. Our code and data are publicly available at the link: \url{https://github.com/RUCAIBox/Data-CUBE}.
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
Sep 08, 2023



Large language models (LLMs) have emerged as a new paradigm for Text-to-SQL task. However, the absence of a systematical benchmark inhibits the development of designing effective, efficient and economic LLM-based Text-to-SQL solutions. To address this challenge, in this paper, we first conduct a systematical and extensive comparison over existing prompt engineering methods, including question representation, example selection and example organization, and with these experimental results, we elaborate their pros and cons. Based on these findings, we propose a new integrated solution, named DAIL-SQL, which refreshes the Spider leaderboard with 86.6% execution accuracy and sets a new bar. To explore the potential of open-source LLM, we investigate them in various scenarios, and further enhance their performance with supervised fine-tuning. Our explorations highlight open-source LLMs' potential in Text-to-SQL, as well as the advantages and disadvantages of the supervised fine-tuning. Additionally, towards an efficient and economic LLM-based Text-to-SQL solution, we emphasize the token efficiency in prompt engineering and compare the prior studies under this metric. We hope that our work provides a deeper understanding of Text-to-SQL with LLMs, and inspires further investigations and broad applications.