 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models
Feb 03, 2026Entropy serves as a critical metric for measuring the diversity of outputs generated by large language models (LLMs), providing valuable insights into their exploration capabilities. While recent studies increasingly focus on monitoring and adjusting entropy to better balance exploration and exploitation in reinforcement fine-tuning (RFT), a principled understanding of entropy dynamics during this process is yet to be thoroughly investigated. In this paper, we establish a theoretical framework for analyzing the entropy dynamics during the RFT process, which begins with a discriminant expression that quantifies entropy change under a single logit update. This foundation enables the derivation of a first-order expression for entropy change, which can be further extended to the update formula of Group Relative Policy Optimization (GRPO). The corollaries and insights drawn from the theoretical analysis inspire the design of entropy control methods, and also offer a unified lens for interpreting various entropy-based methods in existing studies. We provide empirical evidence to support the main conclusions of our analysis and demonstrate the effectiveness of the derived entropy-discriminator clipping methods. This study yields novel insights into RFT training dynamics, providing theoretical support and practical strategies for optimizing the exploration-exploitation balance during LLM fine-tuning.
R$^3$L: Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification
Jan 07, 2026Reinforcement learning drives recent advances in LLM reasoning and agentic capabilities, yet current approaches struggle with both exploration and exploitation. Exploration suffers from low success rates on difficult tasks and high costs of repeated rollouts from scratch. Exploitation suffers from coarse credit assignment and training instability: Trajectory-level rewards penalize valid prefixes for later errors, and failure-dominated groups overwhelm the few positive signals, leaving optimization without constructive direction. To this end, we propose R$^3$L, Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification. To synthesize high-quality trajectories, R$^3$L shifts from stochastic sampling to active synthesis via reflect-then-retry, leveraging language feedback to diagnose errors, transform failed attempts into successful ones, and reduce rollout costs by restarting from identified failure points. With errors diagnosed and localized, Pivotal Credit Assignment updates only the diverging suffix where contrastive signals exist, excluding the shared prefix from gradient update. Since failures dominate on difficult tasks and reflect-then-retry produces off-policy data, risking training instability, Positive Amplification upweights successful trajectories to ensure positive signals guide the optimization process. Experiments on agentic and reasoning tasks demonstrate 5\% to 52\% relative improvements over baselines while maintaining training stability. Our code is released at https://github.com/shiweijiezero/R3L.
Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
May 23, 2025Trinity-RFT is a general-purpose, flexible and scalable framework designed for reinforcement fine-tuning (RFT) of large language models. It is built with a decoupled design, consisting of (1) an RFT-core that unifies and generalizes synchronous/asynchronous, on-policy/off-policy, and online/offline modes of RFT, (2) seamless integration for agent-environment interaction with high efficiency and robustness, and (3) systematic data pipelines optimized for RFT. Trinity-RFT can be easily adapted for diverse application scenarios, and serves as a unified platform for exploring advanced reinforcement learning paradigms. This technical report outlines the vision, features, design and implementations of Trinity-RFT, accompanied by extensive examples demonstrating the utility and user-friendliness of the proposed framework.
Enhancing Latent Computation in Transformers with Latent Tokens
May 19, 2025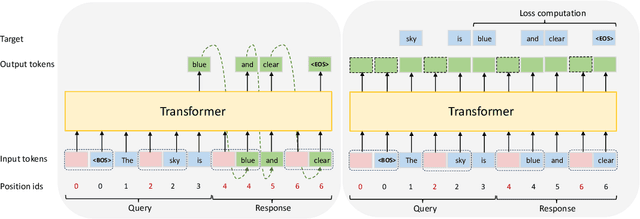

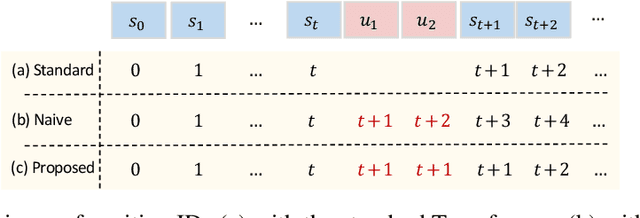
Augmenting large language models (LLMs) with auxiliary tokens has emerged as a promising strategy for enhancing model performance. In this work, we introduce a lightweight method termed latent tokens; these are dummy tokens that may be non-interpretable in natural language but steer the autoregressive decoding process of a Transformer-based LLM via the attention mechanism. The proposed latent tokens can be seamlessly integrated with a pre-trained Transformer, trained in a parameter-efficient manner, and applied flexibly at inference time, while adding minimal complexity overhead to the existing infrastructure of standard Transformers. We propose several hypotheses about the underlying mechanisms of latent tokens and design synthetic tasks accordingly to verify them. Numerical results confirm that the proposed method noticeably outperforms the baselines, particularly in the out-of-distribution generalization scenarios, highlighting its potential in improving the adaptability of LLMs.
Learn How to Query from Unlabeled Data Streams in Federated Learning
Dec 12, 2024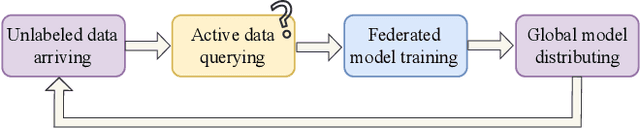
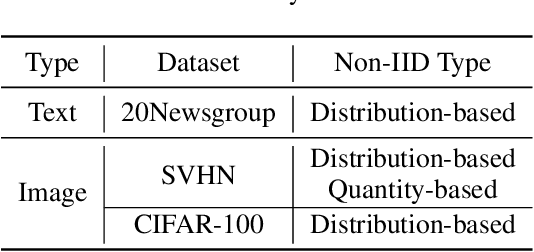
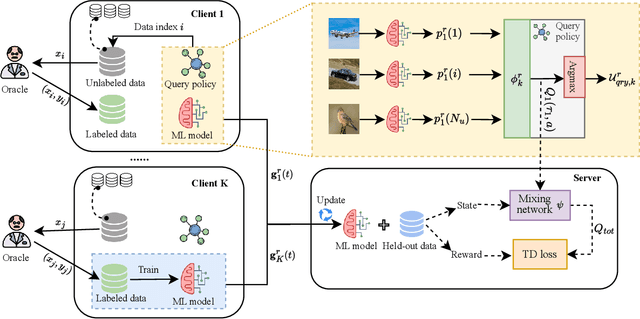
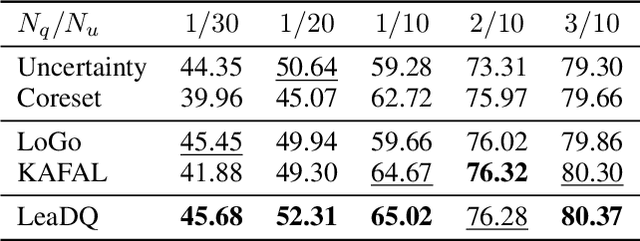
Federated learning (FL) enables collaborative learning among decentralized clients while safeguarding the privacy of their local data. Existing studies on FL typically assume offline labeled data available at each client when the training starts. Nevertheless, the training data in practice often arrive at clients in a streaming fashion without ground-truth labels. Given the expensive annotation cost, it is critical to identify a subset of informative samples for labeling on clients. However, selecting samples locally while accommodating the global training objective presents a challenge unique to FL. In this work, we tackle this conundrum by framing the data querying process in FL as a collaborative decentralized decision-making problem and proposing an effective solution named LeaDQ, which leverages multi-agent reinforcement learning algorithms. In particular, under the implicit guidance from global information, LeaDQ effectively learns the local policies for distributed clients and steers them towards selecting samples that can enhance the global model's accuracy. Extensive simulations on image and text tasks show that LeaDQ advances the model performance in various FL scenarios, outperforming the benchmarking algorithms.
Exploring Selective Layer Fine-Tuning in Federated Learning
Aug 28, 2024Federated learning (FL) has emerged as a promising paradigm for fine-tuning foundation models using distributed data in a privacy-preserving manner. Under limited computational resources, clients often find it more practical to fine-tune a selected subset of layers, rather than the entire model, based on their task-specific data. In this study, we provide a thorough theoretical exploration of selective layer fine-tuning in FL, emphasizing a flexible approach that allows the clients to adjust their selected layers according to their local data and resources. We theoretically demonstrate that the layer selection strategy has a significant impact on model convergence in two critical aspects: the importance of selected layers and the heterogeneous choices across clients. Drawing from these insights, we further propose a strategic layer selection method that utilizes local gradients and regulates layer selections across clients. The extensive experiments on both image and text datasets demonstrate the effectiveness of the proposed strategy compared with several baselines, highlighting its advances in identifying critical layers that adapt to the client heterogeneity and training dynamics in FL.
Dual-Delayed Asynchronous SGD for Arbitrarily Heterogeneous Data
May 27, 2024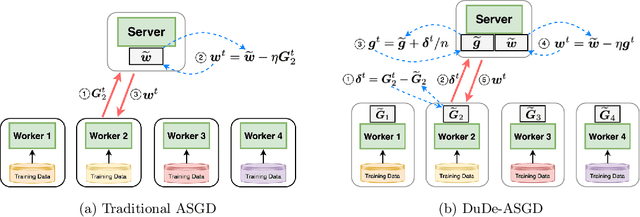

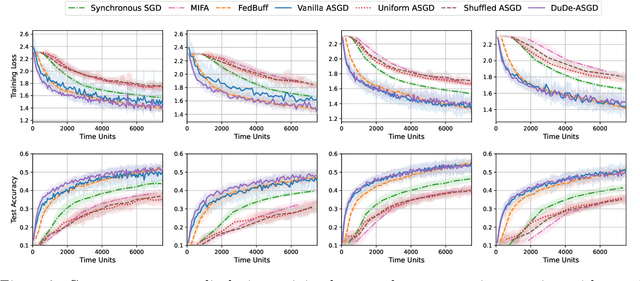
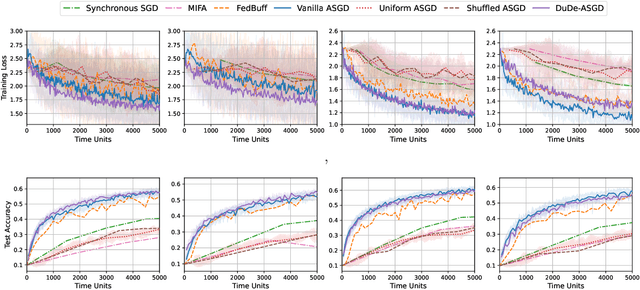
We consider the distributed learning problem with data dispersed across multiple workers under the orchestration of a central server. Asynchronous Stochastic Gradient Descent (SGD) has been widely explored in such a setting to reduce the synchronization overhead associated with parallelization. However, the performance of asynchronous SGD algorithms often depends on a bounded dissimilarity condition among the workers' local data, a condition that can drastically affect their efficiency when the workers' data are highly heterogeneous. To overcome this limitation, we introduce the \textit{dual-delayed asynchronous SGD (DuDe-ASGD)} algorithm designed to neutralize the adverse effects of data heterogeneity. DuDe-ASGD makes full use of stale stochastic gradients from all workers during asynchronous training, leading to two distinct time lags in the model parameters and data samples utilized in the server's iterations. Furthermore, by adopting an incremental aggregation strategy, DuDe-ASGD maintains a per-iteration computational cost that is on par with traditional asynchronous SGD algorithms. Our analysis demonstrates that DuDe-ASGD achieves a near-minimax-optimal convergence rate for smooth nonconvex problems, even when the data across workers are extremely heterogeneous. Numerical experiments indicate that DuDe-ASGD compares favorably with existing asynchronous and synchronous SGD-based algorithms.
How to Collaborate: Towards Maximizing the Generalization Performance in Cross-Silo Federated Learning
Jan 24, 2024Federated learning (FL) has attracted vivid attention as a privacy-preserving distributed learning framework. In this work, we focus on cross-silo FL, where clients become the model owners after training and are only concerned about the model's generalization performance on their local data. Due to the data heterogeneity issue, asking all the clients to join a single FL training process may result in model performance degradation. To investigate the effectiveness of collaboration, we first derive a generalization bound for each client when collaborating with others or when training independently. We show that the generalization performance of a client can be improved only by collaborating with other clients that have more training data and similar data distribution. Our analysis allows us to formulate a client utility maximization problem by partitioning clients into multiple collaborating groups. A hierarchical clustering-based collaborative training (HCCT) scheme is then proposed, which does not need to fix in advance the number of groups. We further analyze the convergence of HCCT for general non-convex loss functions which unveils the effect of data similarity among clients. Extensive simulations show that HCCT achieves better generalization performance than baseline schemes, whereas it degenerates to independent training and conventional FL in specific scenarios.
Feature Matching Data Synthesis for Non-IID Federated Learning
Aug 09, 2023Federated learning (FL) has emerged as a privacy-preserving paradigm that trains neural networks on edge devices without collecting data at a central server. However, FL encounters an inherent challenge in dealing with non-independent and identically distributed (non-IID) data among devices. To address this challenge, this paper proposes a hard feature matching data synthesis (HFMDS) method to share auxiliary data besides local models. Specifically, synthetic data are generated by learning the essential class-relevant features of real samples and discarding the redundant features, which helps to effectively tackle the non-IID issue. For better privacy preservation, we propose a hard feature augmentation method to transfer real features towards the decision boundary, with which the synthetic data not only improve the model generalization but also erase the information of real features. By integrating the proposed HFMDS method with FL, we present a novel FL framework with data augmentation to relieve data heterogeneity. The theoretical analysis highlights the effectiveness of our proposed data synthesis method in solving the non-IID challenge. Simulation results further demonstrate that our proposed HFMDS-FL algorithm outperforms the baselines in terms of accuracy, privacy preservation, and computational cost on various benchmark datasets.
A Survey of What to Share in Federated Learning: Perspectives on Model Utility, Privacy Leakage, and Communication Efficiency
Jul 20, 2023



Federated learning (FL) has emerged as a highly effective paradigm for privacy-preserving collaborative training among different parties. Unlike traditional centralized learning, which requires collecting data from each party, FL allows clients to share privacy-preserving information without exposing private datasets. This approach not only guarantees enhanced privacy protection but also facilitates more efficient and secure collaboration among multiple participants. Therefore, FL has gained considerable attention from researchers, promoting numerous surveys to summarize the related works. However, the majority of these surveys concentrate on methods sharing model parameters during the training process, while overlooking the potential of sharing other forms of local information. In this paper, we present a systematic survey from a new perspective, i.e., what to share in FL, with an emphasis on the model utility, privacy leakage, and communication efficiency. This survey differs from previous ones due to four distinct contributions. First, we present a new taxonomy of FL methods in terms of the sharing methods, which includes three categories of shared information: model sharing, synthetic data sharing, and knowledge sharing. Second, we analyze the vulnerability of different sharing methods to privacy attacks and review the defense mechanisms that provide certain privacy guarantees. Third, we conduct extensive experiments to compare the performance and communication overhead of various sharing methods in FL. Besides, we assess the potential privacy leakage through model inversion and membership inference attacks, while comparing the effectiveness of various defense approaches. Finally, we discuss potential deficiencies in current methods and outline future directions for improvement.