 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Quantization in Federated Learning: A Rényi Differential Privacy Perspective
May 16, 2024



Federated Learning (FL) is an emerging paradigm that holds great promise for privacy-preserving machine learning using distributed data. To enhance privacy, FL can be combined with Differential Privacy (DP), which involves adding Gaussian noise to the model weights. However, FL faces a significant challenge in terms of large communication overhead when transmitting these model weights. To address this issue, quantization is commonly employed. Nevertheless, the presence of quantized Gaussian noise introduces complexities in understanding privacy protection. This research paper investigates the impact of quantization on privacy in FL systems. We examine the privacy guarantees of quantized Gaussian mechanisms using R\'enyi Differential Privacy (RDP). By deriving the privacy budget of quantized Gaussian mechanisms, we demonstrate that lower quantization bit levels provide improved privacy protection. To validate our theoretical findings, we employ Membership Inference Attacks (MIA), which gauge the accuracy of privacy leakage. The numerical results align with our theoretical analysis, confirming that quantization can indeed enhance privacy protection. This study not only enhances our understanding of the correlation between privacy and communication in FL but also underscores the advantages of quantization in preserving privacy.
Binary Federated Learning with Client-Level Differential Privacy
Aug 07, 2023
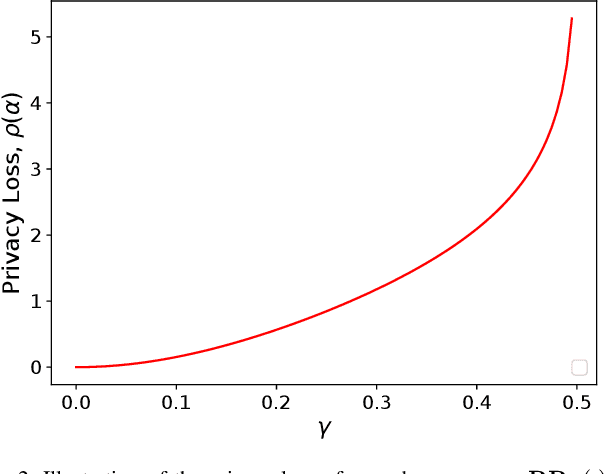
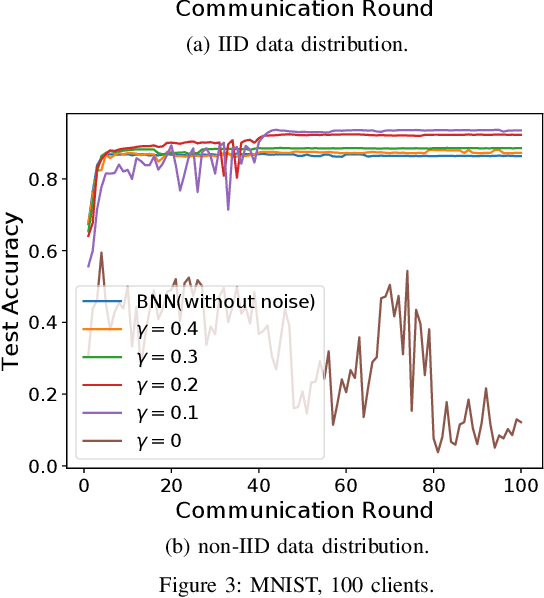

Federated learning (FL) is a privacy-preserving collaborative learning framework, and differential privacy can be applied to further enhance its privacy protection. Existing FL systems typically adopt Federated Average (FedAvg) as the training algorithm and implement differential privacy with a Gaussian mechanism. However, the inherent privacy-utility trade-off in these systems severely degrades the training performance if a tight privacy budget is enforced. Besides, the Gaussian mechanism requires model weights to be of high-precision. To improve communication efficiency and achieve a better privacy-utility trade-off, we propose a communication-efficient FL training algorithm with differential privacy guarantee. Specifically, we propose to adopt binary neural networks (BNNs) and introduce discrete noise in the FL setting. Binary model parameters are uploaded for higher communication efficiency and discrete noise is added to achieve the client-level differential privacy protection. The achieved performance guarantee is rigorously proved, and it is shown to depend on the level of discrete noise. Experimental results based on MNIST and Fashion-MNIST datasets will demonstrate that the proposed training algorithm achieves client-level privacy protection with performance gain while enjoying the benefits of low communication overhead from binary model updates.
A Survey of What to Share in Federated Learning: Perspectives on Model Utility, Privacy Leakage, and Communication Efficiency
Jul 20, 2023



Federated learning (FL) has emerged as a highly effective paradigm for privacy-preserving collaborative training among different parties. Unlike traditional centralized learning, which requires collecting data from each party, FL allows clients to share privacy-preserving information without exposing private datasets. This approach not only guarantees enhanced privacy protection but also facilitates more efficient and secure collaboration among multiple participants. Therefore, FL has gained considerable attention from researchers, promoting numerous surveys to summarize the related works. However, the majority of these surveys concentrate on methods sharing model parameters during the training process, while overlooking the potential of sharing other forms of local information. In this paper, we present a systematic survey from a new perspective, i.e., what to share in FL, with an emphasis on the model utility, privacy leakage, and communication efficiency. This survey differs from previous ones due to four distinct contributions. First, we present a new taxonomy of FL methods in terms of the sharing methods, which includes three categories of shared information: model sharing, synthetic data sharing, and knowledge sharing. Second, we analyze the vulnerability of different sharing methods to privacy attacks and review the defense mechanisms that provide certain privacy guarantees. Third, we conduct extensive experiments to compare the performance and communication overhead of various sharing methods in FL. Besides, we assess the potential privacy leakage through model inversion and membership inference attacks, while comparing the effectiveness of various defense approaches. Finally, we discuss potential deficiencies in current methods and outline future directions for improvement.
Communication-Efficient Federated Distillation with Active Data Sampling
Mar 14, 2022


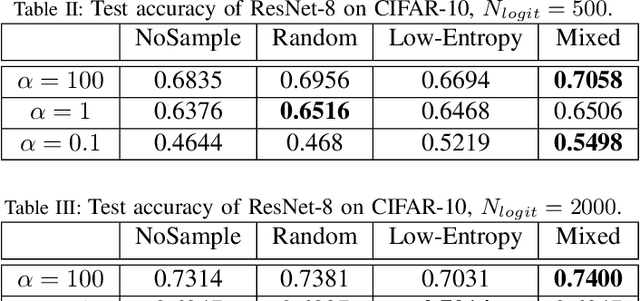
Federated learning (FL) is a promising paradigm to enable privacy-preserving deep learning from distributed data. Most previous works are based on federated average (FedAvg), which, however, faces several critical issues, including a high communication overhead and the difficulty in dealing with heterogeneous model architectures. Federated Distillation (FD) is a recently proposed alternative to enable communication-efficient and robust FL, which achieves orders of magnitude reduction of the communication overhead compared with FedAvg and is flexible to handle heterogeneous models at the clients. However, so far there is no unified algorithmic framework or theoretical analysis for FD-based methods. In this paper, we first present a generic meta-algorithm for FD and investigate the influence of key parameters through empirical experiments. Then, we verify the empirical observations theoretically. Based on the empirical results and theory, we propose a communication-efficient FD algorithm with active data sampling to improve the model performance and reduce the communication overhead. Empirical simulations on benchmark datasets will demonstrate that our proposed algorithm effectively and significantly reduces the communication overhead while achieving a satisfactory performance.
Hierarchical Quantized Federated Learning: Convergence Analysis and System Design
Mar 26, 2021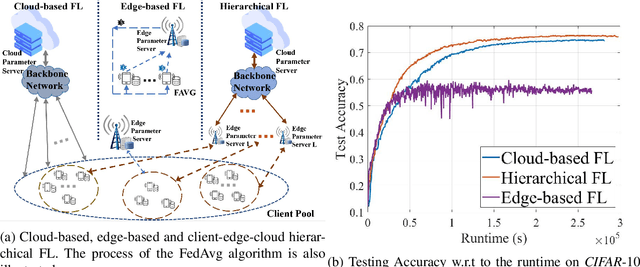
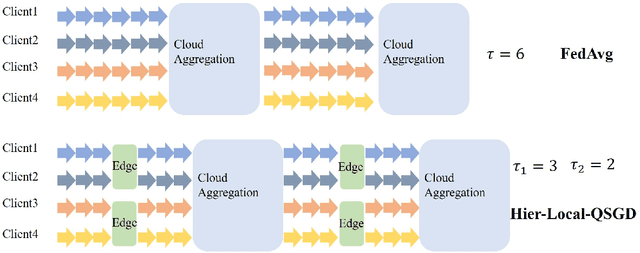
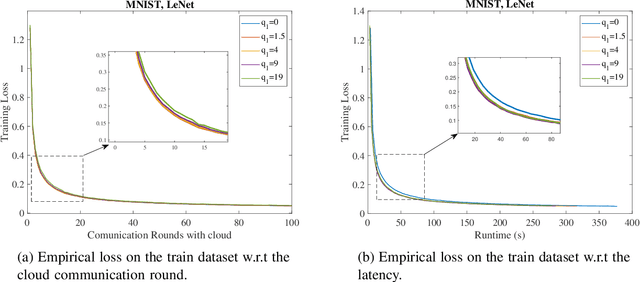
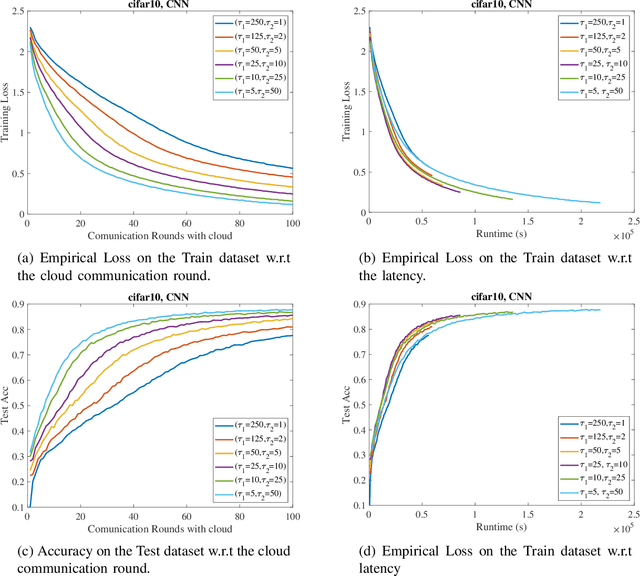
Federated learning is a collaborative machine learning framework to train deep neural networks without accessing clients' private data. Previous works assume one central parameter server either at the cloud or at the edge. A cloud server can aggregate knowledge from all participating clients but suffers high communication overhead and latency, while an edge server enjoys more efficient communications during model update but can only reach a limited number of clients. This paper exploits the advantages of both cloud and edge servers and considers a Hierarchical Quantized Federated Learning (HQFL) system with one cloud server, several edge servers and many clients, adopting a communication-efficient training algorithm, Hier-Local-QSGD. The high communication efficiency comes from frequent local aggregations at the edge servers and fewer aggregations at the cloud server, as well as weight quantization during model uploading. A tight convergence bound for non-convex objective loss functions is derived, which is then applied to investigate two design problems, namely, the accuracy-latency trade-off and edge-client association. It will be shown that given a latency budget for the whole training process, there is an optimal parameter choice with respect to the two aggregation intervals and two quantization levels. For the edge-client association problem, it is found that the edge-client association strategy has no impact on the convergence speed. Empirical simulations shall verify the findings from the convergence analysis and demonstrate the accuracy-latency trade-off in the hierarchical federated learning system.
Edge-Assisted Hierarchical Federated Learning with Non-IID Data
May 16, 2019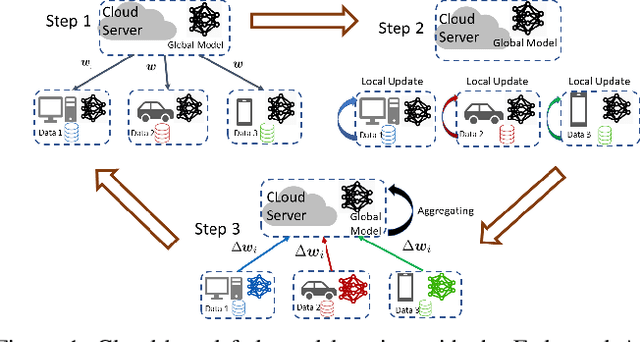
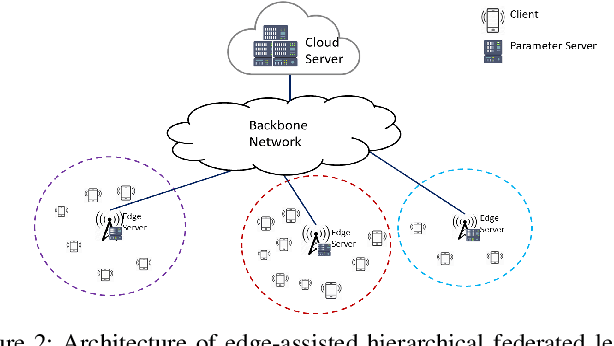
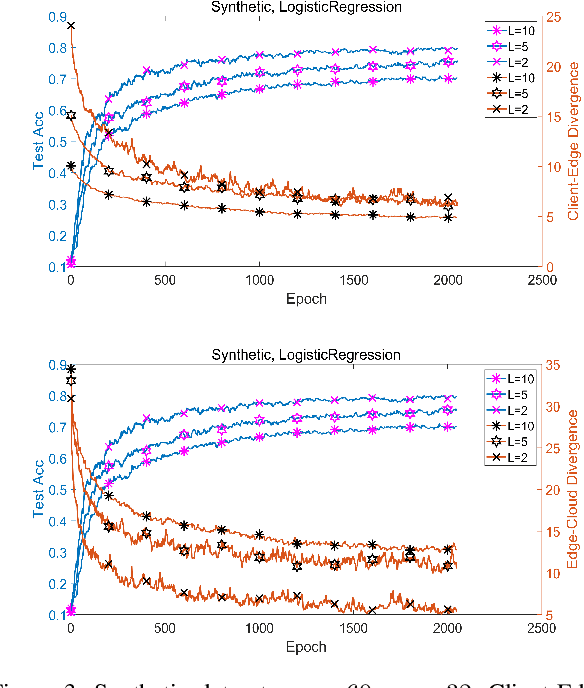
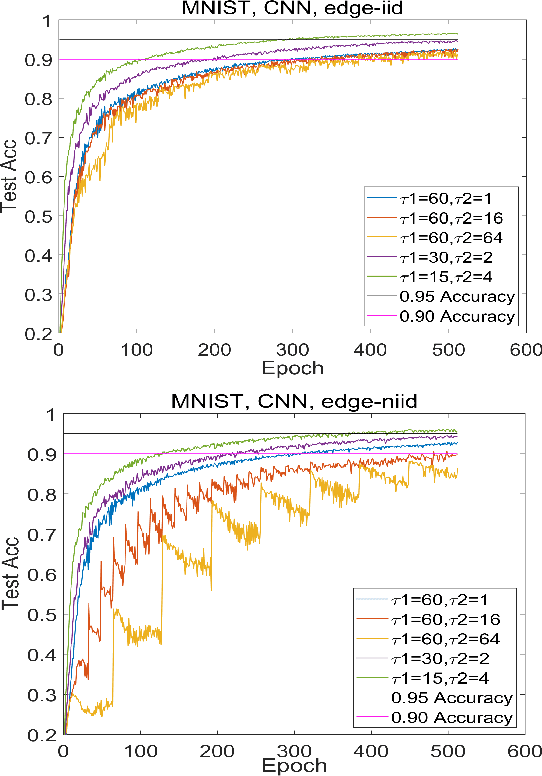
Federated Learning (FL) is capable of leveraging massively distributed private data, e.g., on mobile phones and IoT devices, to collaboratively train a shared machine learning model with the help of a cloud server. However, its iterative training process results in intolerable communication latency, and causes huge burdens on the backbone network. Thus, reducing the communication overhead is critical to implement FL in practice. Meanwhile, the model performance degradation due to the unique non-IID data distribution at different devices is another big issue for FL. In this paper, by introducing the mobile edge computing platform as an intermediary structure, we propose a hierarchical FL architecture to reduce the communication rounds between users and the cloud. In particular, a Hierarchical Federated Averaging (HierFAVG) algorithm is proposed, which allows multiple local aggregations at each edge server before one global aggregation at the cloud. We establish the convergence of HierFAVG for both convex and non-convex objective functions with non-IID user data. It is demonstrated that HierFAVG can reach a desired model performance with less communication, and outperform the traditional Federated Averaging algorithm.