 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Quantized Federated Learning: Convergence Analysis and System Design
Paper and Code
Mar 26, 2021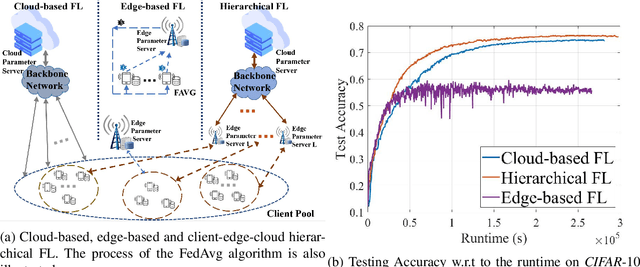
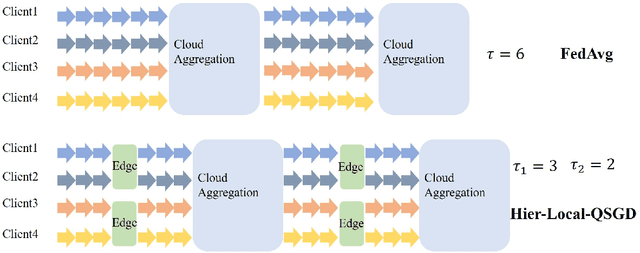
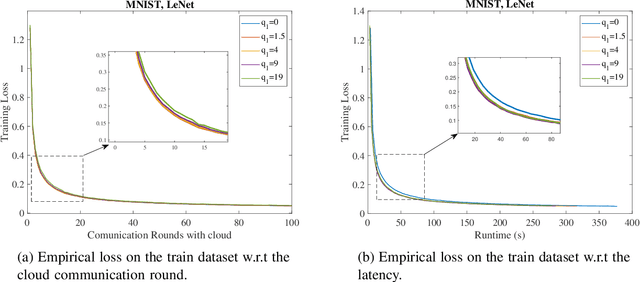
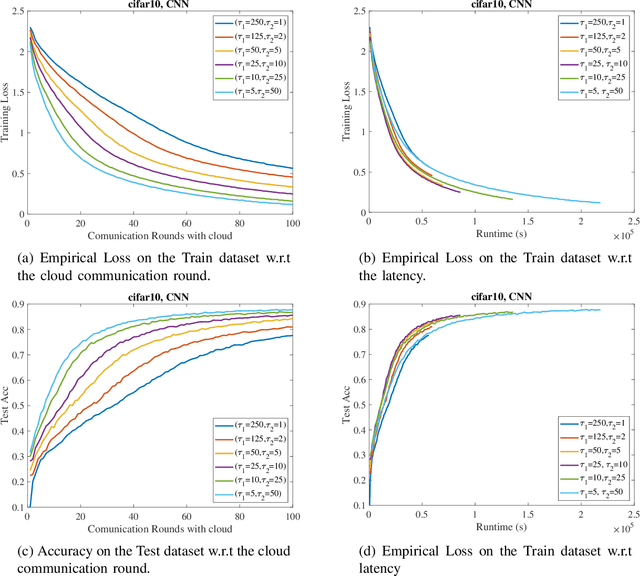
Federated learning is a collaborative machine learning framework to train deep neural networks without accessing clients' private data. Previous works assume one central parameter server either at the cloud or at the edge. A cloud server can aggregate knowledge from all participating clients but suffers high communication overhead and latency, while an edge server enjoys more efficient communications during model update but can only reach a limited number of clients. This paper exploits the advantages of both cloud and edge servers and considers a Hierarchical Quantized Federated Learning (HQFL) system with one cloud server, several edge servers and many clients, adopting a communication-efficient training algorithm, Hier-Local-QSGD. The high communication efficiency comes from frequent local aggregations at the edge servers and fewer aggregations at the cloud server, as well as weight quantization during model uploading. A tight convergence bound for non-convex objective loss functions is derived, which is then applied to investigate two design problems, namely, the accuracy-latency trade-off and edge-client association. It will be shown that given a latency budget for the whole training process, there is an optimal parameter choice with respect to the two aggregation intervals and two quantization levels. For the edge-client association problem, it is found that the edge-client association strategy has no impact on the convergence speed. Empirical simulations shall verify the findings from the convergence analysis and demonstrate the accuracy-latency trade-off in the hierarchical federated learning system.