 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Design-Score Manifold to Guide Diffusion Models for Offline Optimization
Jun 06, 2025Optimizing complex systems, from discovering therapeutic drugs to designing high-performance materials, remains a fundamental challenge across science and engineering, as the underlying rules are often unknown and costly to evaluate. Offline optimization aims to optimize designs for target scores using pre-collected datasets without system interaction. However, conventional approaches may fail beyond training data, predicting inaccurate scores and generating inferior designs. This paper introduces ManGO, a diffusion-based framework that learns the design-score manifold, capturing the design-score interdependencies holistically. Unlike existing methods that treat design and score spaces in isolation, ManGO unifies forward prediction and backward generation, attaining generalization beyond training data. Key to this is its derivative-free guidance for conditional generation, coupled with adaptive inference-time scaling that dynamically optimizes denoising paths. Extensive evaluations demonstrate that ManGO outperforms 24 single- and 10 multi-objective optimization methods across diverse domains, including synthetic tasks, robot control, material design, DNA sequence, and real-world engineering optimization.
Federated Prompt-based Decision Transformer for Customized VR Services in Mobile Edge Computing System
Feb 15, 2024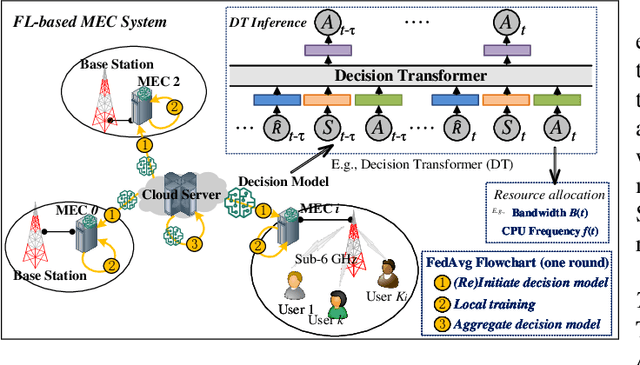
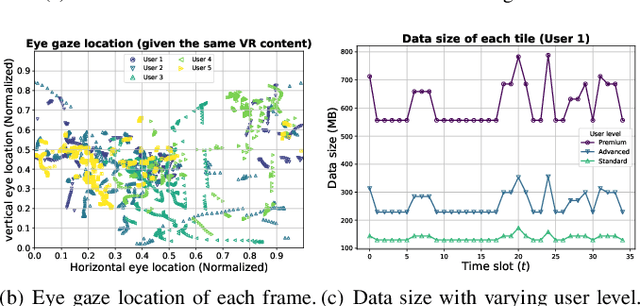
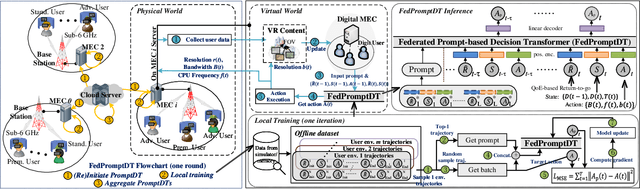
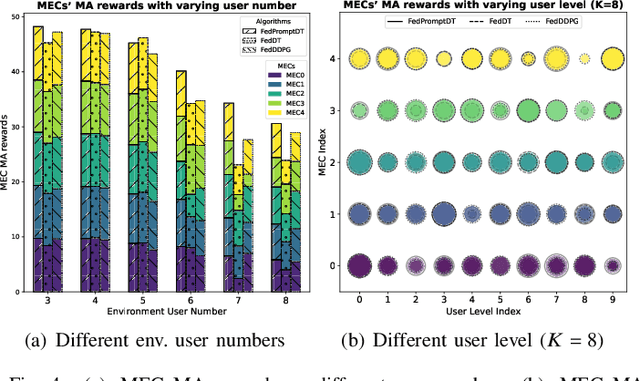
This paper investigates resource allocation to provide heterogeneous users with customized virtual reality (VR) services in a mobile edge computing (MEC) system. We first introduce a quality of experience (QoE) metric to measure user experience, which considers the MEC system's latency, user attention levels, and preferred resolutions. Then, a QoE maximization problem is formulated for resource allocation to ensure the highest possible user experience,which is cast as a reinforcement learning problem, aiming to learn a generalized policy applicable across diverse user environments for all MEC servers. To learn the generalized policy, we propose a framework that employs federated learning (FL) and prompt-based sequence modeling to pre-train a common decision model across MEC servers, which is named FedPromptDT. Using FL solves the problem of insufficient local MEC data while protecting user privacy during offline training. The design of prompts integrating user-environment cues and user-preferred allocation improves the model's adaptability to various user environments during online execution.
Mode Connectivity and Data Heterogeneity of Federated Learning
Sep 29, 2023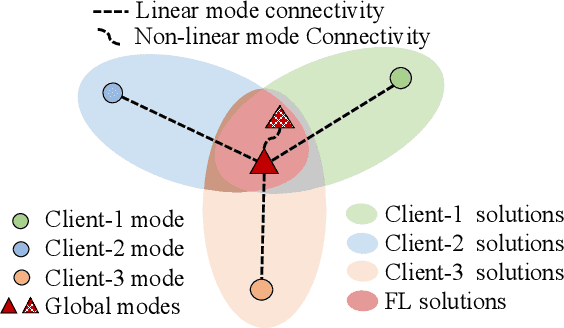
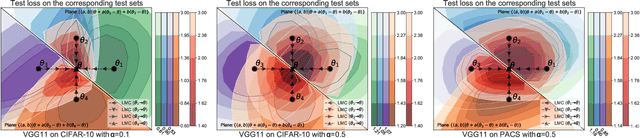
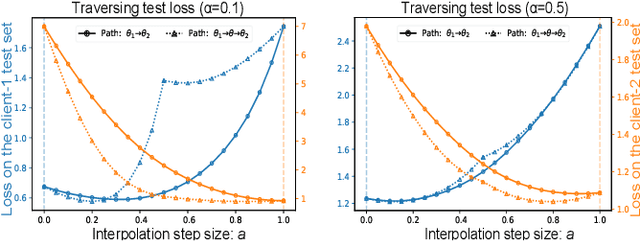
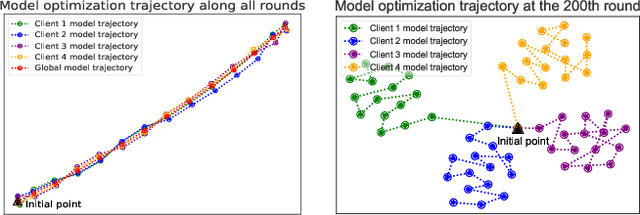
Federated learning (FL) enables multiple clients to train a model while keeping their data private collaboratively. Previous studies have shown that data heterogeneity between clients leads to drifts across client updates. However, there are few studies on the relationship between client and global modes, making it unclear where these updates end up drifting. We perform empirical and theoretical studies on this relationship by utilizing mode connectivity, which measures performance change (i.e., connectivity) along parametric paths between different modes. Empirically, reducing data heterogeneity makes the connectivity on different paths more similar, forming more low-error overlaps between client and global modes. We also find that a barrier to connectivity occurs when linearly connecting two global modes, while it disappears with considering non-linear mode connectivity. Theoretically, we establish a quantitative bound on the global-mode connectivity using mean-field theory or dropout stability. The bound demonstrates that the connectivity improves when reducing data heterogeneity and widening trained models. Numerical results further corroborate our analytical findings.
A Survey of What to Share in Federated Learning: Perspectives on Model Utility, Privacy Leakage, and Communication Efficiency
Jul 20, 2023



Federated learning (FL) has emerged as a highly effective paradigm for privacy-preserving collaborative training among different parties. Unlike traditional centralized learning, which requires collecting data from each party, FL allows clients to share privacy-preserving information without exposing private datasets. This approach not only guarantees enhanced privacy protection but also facilitates more efficient and secure collaboration among multiple participants. Therefore, FL has gained considerable attention from researchers, promoting numerous surveys to summarize the related works. However, the majority of these surveys concentrate on methods sharing model parameters during the training process, while overlooking the potential of sharing other forms of local information. In this paper, we present a systematic survey from a new perspective, i.e., what to share in FL, with an emphasis on the model utility, privacy leakage, and communication efficiency. This survey differs from previous ones due to four distinct contributions. First, we present a new taxonomy of FL methods in terms of the sharing methods, which includes three categories of shared information: model sharing, synthetic data sharing, and knowledge sharing. Second, we analyze the vulnerability of different sharing methods to privacy attacks and review the defense mechanisms that provide certain privacy guarantees. Third, we conduct extensive experiments to compare the performance and communication overhead of various sharing methods in FL. Besides, we assess the potential privacy leakage through model inversion and membership inference attacks, while comparing the effectiveness of various defense approaches. Finally, we discuss potential deficiencies in current methods and outline future directions for improvement.
Understanding Model Averaging in Federated Learning on Heterogeneous Data
May 20, 2023Model averaging, a widely adopted technique in federated learning (FL), aggregates multiple client models trained on heterogeneous data to obtain a well-performed global model. However, the rationale behind its success is not well understood. To shed light on this issue, we investigate the geometric properties of model averaging by visualizing the loss/error landscape. The geometrical visualization shows that the client models surround the global model within a common basin, and the global model may deviate from the bottom of the basin even though it performs better than the client models. To further understand this phenomenon, we decompose the expected prediction error of the global model into five factors related to client models. Specifically, we find that the global-model error after early training mainly comes from i) the client-model error on non-overlapping data between client datasets and the global dataset and ii) the maximal distance between the global and client models. Inspired by these findings, we propose adopting iterative moving averaging (IMA) on global models to reduce the prediction error and limiting client exploration to control the maximal distance at the late training. Our experiments demonstrate that IMA significantly improves the accuracy and training speed of existing FL methods on benchmark datasets with various data heterogeneity.
FedFA: Federated Learning with Feature Anchors to Align Feature and Classifier for Heterogeneous Data
Nov 17, 2022
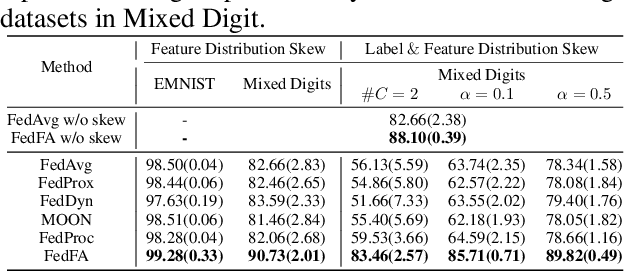

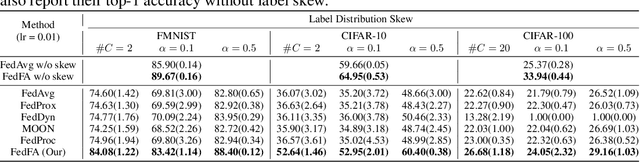
Federated learning allows multiple clients to collaboratively train a model without exchanging their data, thus preserving data privacy. Unfortunately, it suffers significant performance degradation under heterogeneous data at clients. Common solutions in local training involve designing a specific auxiliary loss to regularize weight divergence or feature inconsistency. However, we discover that these approaches fall short of the expected performance because they ignore the existence of a vicious cycle between classifier divergence and feature mapping inconsistency across clients, such that client models are updated in inconsistent feature space with diverged classifiers. We then propose a simple yet effective framework named Federated learning with Feature Anchors (FedFA) to align the feature mappings and calibrate classifier across clients during local training, which allows client models updating in a shared feature space with consistent classifiers. We demonstrate that this modification brings similar classifiers and a virtuous cycle between feature consistency and classifier similarity across clients. Extensive experiments show that FedFA significantly outperforms the state-of-the-art federated learning algorithms on various image classification datasets under label and feature distribution skews.