 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Quantization in Federated Learning: A Rényi Differential Privacy Perspective
May 16, 2024



Federated Learning (FL) is an emerging paradigm that holds great promise for privacy-preserving machine learning using distributed data. To enhance privacy, FL can be combined with Differential Privacy (DP), which involves adding Gaussian noise to the model weights. However, FL faces a significant challenge in terms of large communication overhead when transmitting these model weights. To address this issue, quantization is commonly employed. Nevertheless, the presence of quantized Gaussian noise introduces complexities in understanding privacy protection. This research paper investigates the impact of quantization on privacy in FL systems. We examine the privacy guarantees of quantized Gaussian mechanisms using R\'enyi Differential Privacy (RDP). By deriving the privacy budget of quantized Gaussian mechanisms, we demonstrate that lower quantization bit levels provide improved privacy protection. To validate our theoretical findings, we employ Membership Inference Attacks (MIA), which gauge the accuracy of privacy leakage. The numerical results align with our theoretical analysis, confirming that quantization can indeed enhance privacy protection. This study not only enhances our understanding of the correlation between privacy and communication in FL but also underscores the advantages of quantization in preserving privacy.
Client Selection for Federated Policy Optimization with Environment Heterogeneity
May 24, 2023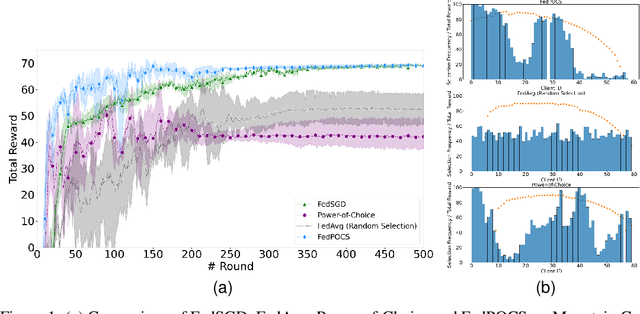
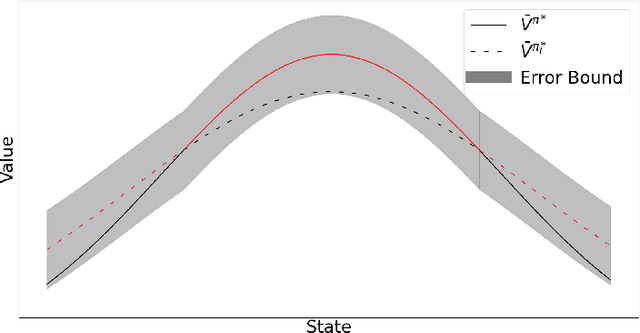
The development of Policy Iteration (PI) has inspired many recent algorithms for Reinforcement Learning (RL), including several policy gradient methods, that gained both theoretical soundness and empirical success on a variety of tasks. The theory of PI is rich in the context of centralized learning, but its study is still in the infant stage under the federated setting. This paper explores the federated version of Approximate PI (API) and derives its error bound, taking into account the approximation error introduced by environment heterogeneity. We theoretically prove that a proper client selection scheme can reduce this error bound. Based on the theoretical result, we propose a client selection algorithm to alleviate the additional approximation error caused by environment heterogeneity. Experiment results show that the proposed algorithm outperforms other biased and unbiased client selection methods on the federated mountain car problem by effectively selecting clients with a lower level of heterogeneity from the population distribution.
Augmented Deep Unfolding for Downlink Beamforming in Multi-cell Massive MIMO With Limited Feedback
Sep 03, 2022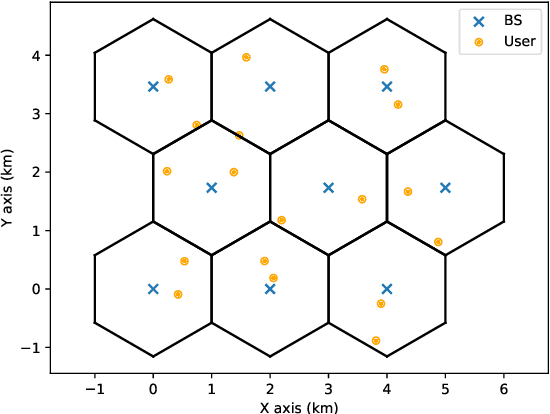
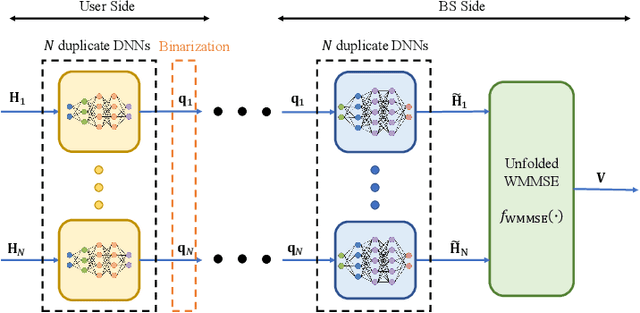
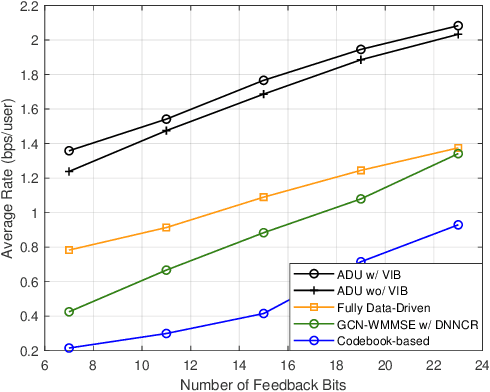
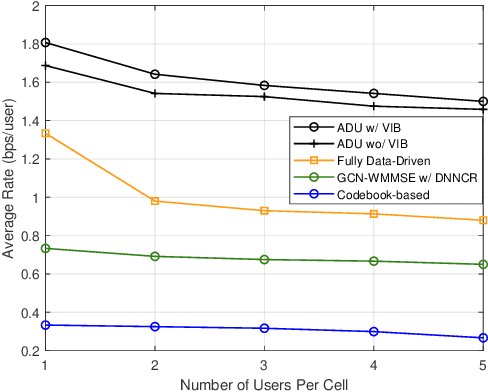
In limited feedback multi-user multiple-input multiple-output (MU-MIMO) cellular networks, users send quantized information about the channel conditions to the associated base station (BS) for downlink beamforming. However, channel quantization and beamforming have been treated as two separate tasks conventionally, which makes it difficult to achieve global system optimality. In this paper, we propose an augmented deep unfolding (ADU) approach that jointly optimizes the beamforming scheme at the BSs and the channel quantization scheme at the users. In particular, the classic WMMSE beamformer is unrolled and a deep neural network (DNN) is leveraged to pre-process its input to enhance the performance. The variational information bottleneck technique is adopted to further improve the performance when the feedback capacity is strictly restricted. Simulation results demonstrate that the proposed ADU method outperforms all the benchmark schemes in terms of the system average rate.
Intelligent Reflecting Surface-Aided Maneuvering Target Sensing: True Velocity Estimation
Jul 30, 2022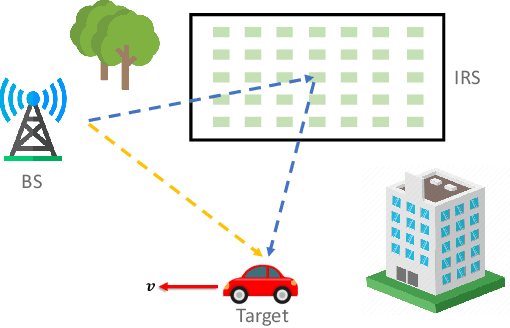
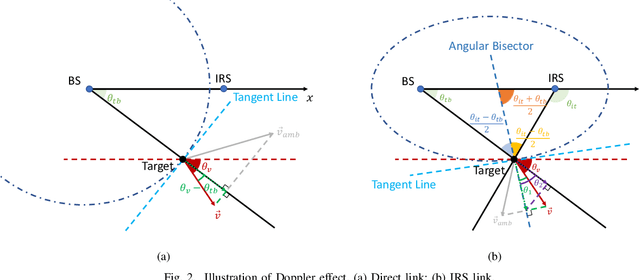
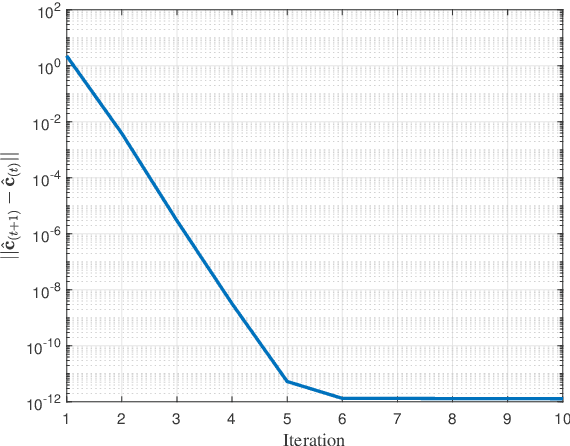
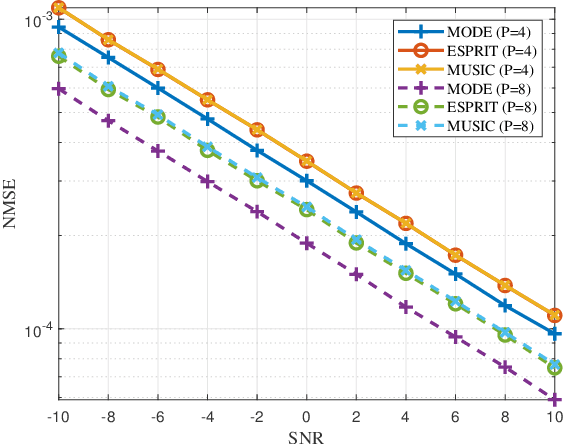
Maneuvering target sensing will be an important service of future vehicular networks, where precise velocity estimation is one of the core tasks. To this end, the recently proposed integrated sensing and communications (ISAC) provides a promising platform for achieving accurate velocity estimation. However, with one mono-static ISAC base station (BS), only the radial projection of the true velocity can be estimated, which causes serious estimation error. In this paper, we investigate the estimation of the true velocity of a maneuvering target with the assistance of intelligent reflecting surfaces (IRSs). In particular, we propose an efficient velocity estimation algorithm exploiting the two perspectives from the BS and IRS to the target. In particular, we propose a two-stage scheme where the true velocity can be recovered based on the Doppler frequency of the BS-target link and BS-IRS-target link. Experimental results validate that the true velocity can be precisely recovered with the help of IRSs and demonstrate the advantage of adding the IRS.
Collaborative Sensing in Perceptive Mobile Networks: Opportunities and Challenges
May 31, 2022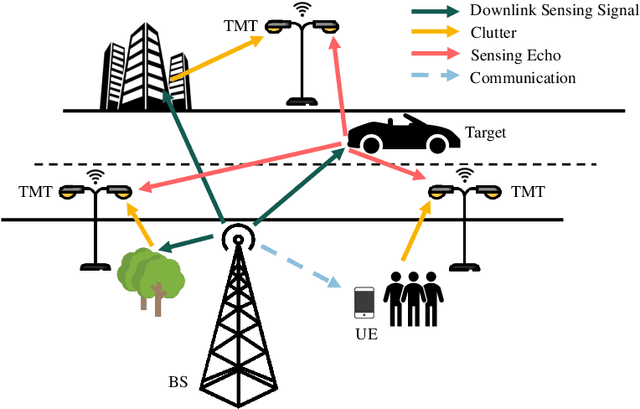


With the development of innovative applications that demand accurate environment information, e.g., autonomous driving, sensing becomes an important requirement for future wireless networks. To this end, integrated sensing and communication (ISAC) provides a promising platform to exploit the synergy between sensing and communication, where perceptive mobile networks (PMNs) were proposed to add accurate sensing capability to existing wireless networks. The well-developed cellular networks offer exciting opportunities for sensing, including large coverage, strong computation and communication power, and most importantly networked sensing, where the perspectives from multiple sensing nodes can be collaboratively utilized for sensing the same target. However, PMNs also face big challenges such as the inherent interference between sensing and communication, the complex sensing environment, and the tracking of high-speed targets by cellular networks. This paper provides a comprehensive review on the design of PMNs, covering the popular network architectures, sensing protocols, standing research problems, and available solutions. Several future research directions that are critical for the development of PMNs are also discussed.
Networked Sensing with AI-Empowered Environment Estimation: Exploiting Macro-Diversity and Array Gain in Perceptive Mobile Networks
May 23, 2022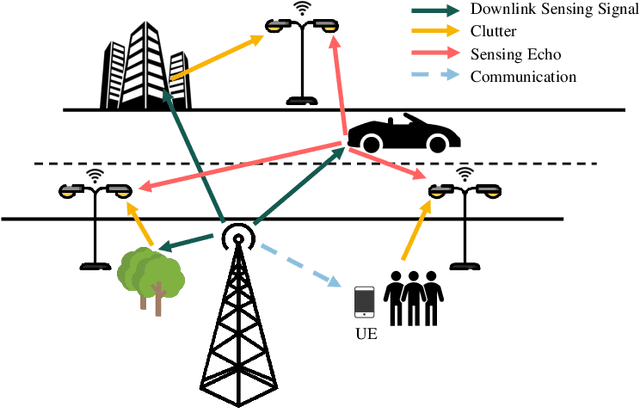
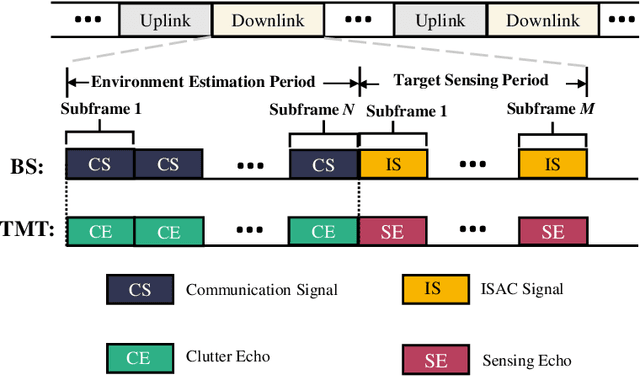
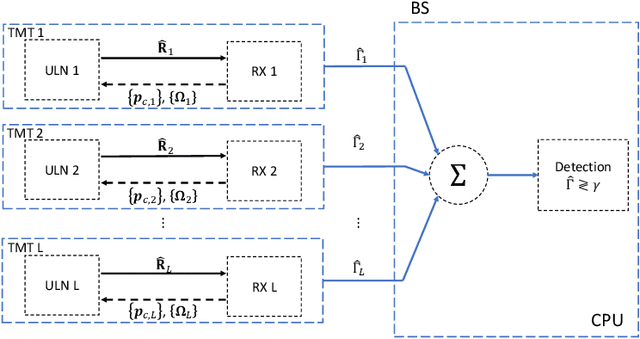
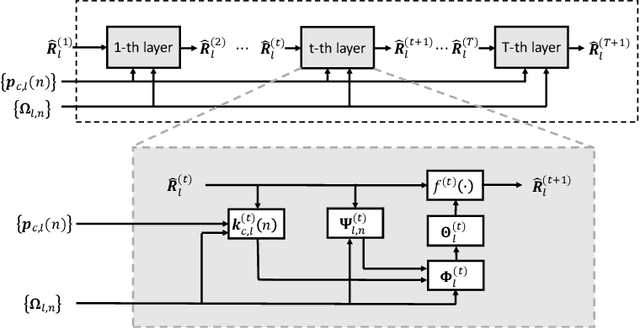
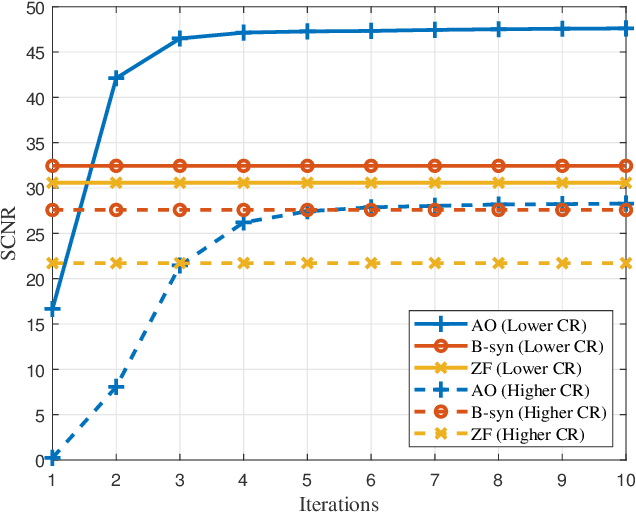
Sensing will be an important service for future wireless networks to assist innovative applications like autonomous driving and environment monitoring. This paper considers the design of perceptive mobile networks (PMNs) where target monitoring terminals (TMTs) are deployed over the traditional cellular networks for jointly sensing the targets in the presence of environment clutter. Different from traditional radar, the cellular structure of PMNs offers multiple perspectives for target sensing (TS), but the joint processing among distributed sensing nodes also causes heavy computation and communication workload over the network. In this paper, we first propose a two-stage protocol where communication signals are utilized for environment estimation (EE) and TS in two consecutive time periods, respectively. A \textit{networked} sensing detector is then derived to exploit the perspectives provided by multiple TMTs for sensing the same target. The macro-diversity from multiple TMTs and the array gain from multiple receive antennas at each TMT are analyzed to reveal the benefit of networked sensing. Furthermore, we derive the sufficient condition that one TMT's contribution to the networked sensing is positive, based on which a TMT selection algorithm is proposed. To reduce the computation burden and efficiently estimate the environment, we propose a model-driven deep-learning algorithm that utilizes partially-sampled data for EE. Simulation results confirm the benefits of networked sensing and validate the higher efficiency of the proposed EE algorithm than existing methods.
Graph Neural Network Enhanced Approximate Message Passing for MIMO Detection
May 21, 2022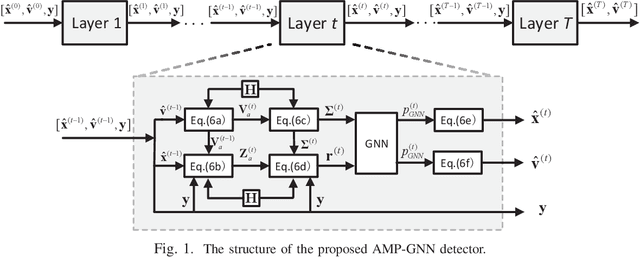
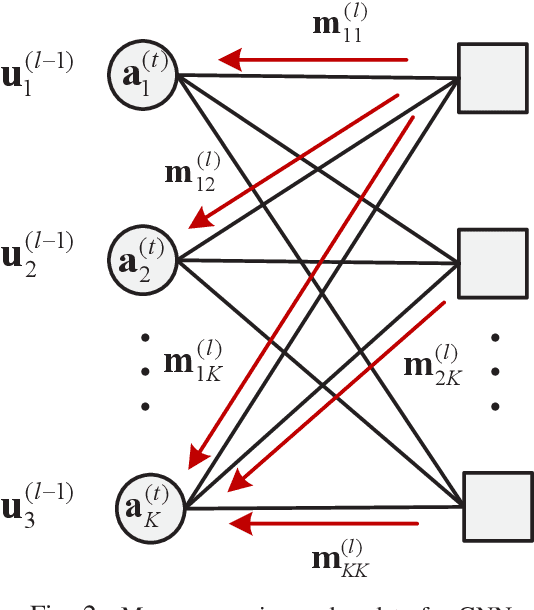
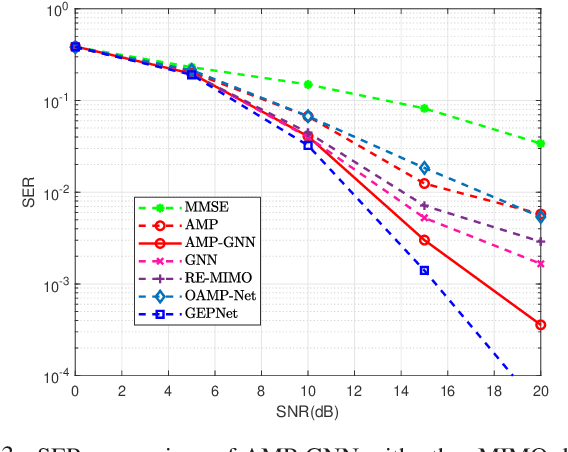
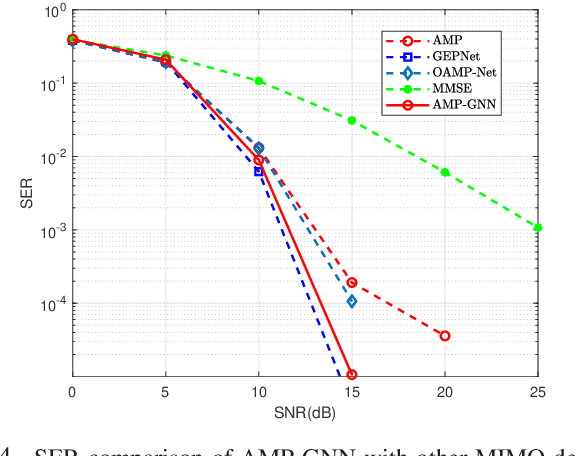
Efficient multiple-input multiple-output (MIMO) detection algorithms with satisfactory performance and low complexity are critical for future multi-antenna systems to meet the high throughput and ultra-low latency requirements in 5G and beyond communications. In this paper, we propose a low complexity graph neural network (GNN) enhanced approximate message passing (AMP) algorithm, AMP-GNN, for MIMO detection. The structure of the neural network is customized by unfolding the AMP algorithm and introducing the GNN module to address the inaccuracy of the Gaussian approximation for multiuser interference cancellation. Numerical results will show that the proposed AMP-GNN significantly improves the performance of the AMP detector and achieves comparable performance as the state-of-the-art deep learning-based MIMO detectors but with reduced computational complexity.
FedKL: Tackling Data Heterogeneity in Federated Reinforcement Learning by Penalizing KL Divergence
Apr 18, 2022

As a distributed learning paradigm, Federated Learning (FL) faces the communication bottleneck issue due to many rounds of model synchronization and aggregation. Heterogeneous data further deteriorates the situation by causing slow convergence. Although the impact of data heterogeneity on supervised FL has been widely studied, the related investigation for Federated Reinforcement Learning (FRL) is still in its infancy. In this paper, we first define the type and level of data heterogeneity for policy gradient based FRL systems. By inspecting the connection between the global and local objective functions, we prove that local training can benefit the global objective, if the local update is properly penalized by the total variation (TV) distance between the local and global policies. A necessary condition for the global policy to be learn-able from the local policy is also derived, which is directly related to the heterogeneity level. Based on the theoretical result, a Kullback-Leibler (KL) divergence based penalty is proposed, which, different from the conventional method that penalizes the model divergence in the parameter space, directly constrains the model outputs in the distribution space. By jointly penalizing the divergence of the local policy from the global policy with a global penalty and constraining each iteration of the local training with a local penalty, the proposed method achieves a better trade-off between training speed (step size) and convergence. Experiment results on two popular RL experiment platforms demonstrate the advantage of the proposed algorithm over existing methods in accelerating and stabilizing the training process with heterogeneous data.
Graph Neural Networks for Wireless Communications: From Theory to Practice
Mar 21, 2022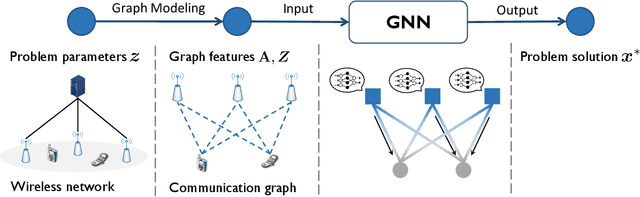
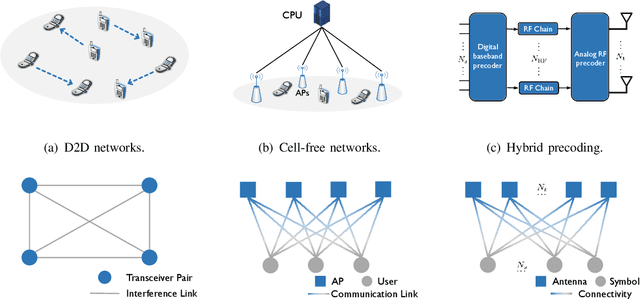
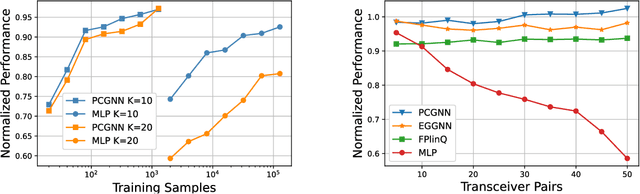
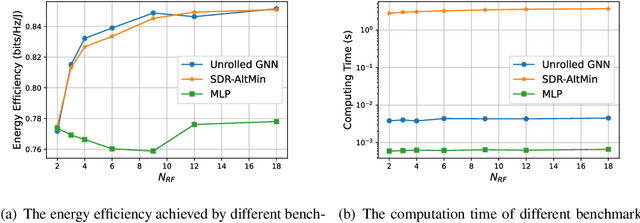
Deep learning-based approaches have been developed to solve challenging problems in wireless communications, leading to promising results. Early attempts adopted neural network architectures inherited from applications such as computer vision. They often require huge amounts of training samples (i.e., poor generalization), and yield poor performance in large-scale networks (i.e., poor scalability). To resolve these issues, graph neural networks (GNNs) have been recently adopted, as they can effectively exploit the domain knowledge, i.e., the graph topology in wireless communication problems. GNN-based methods can achieve near-optimal performance in large-scale networks and generalize well under different system settings, but the theoretical underpinnings and design guidelines remain elusive, which may hinder their practical implementations. This paper endeavors to fill both the theoretical and practical gaps. For theoretical guarantees, we prove that GNNs achieve near-optimal performance in wireless networks with much fewer training samples than traditional neural architectures. Specifically, to solve an optimization problem on an $n$-node graph (where the nodes may represent users, base stations, or antennas), GNNs' generalization error and required number of training samples are $\mathcal{O}(n)$ and $\mathcal{O}(n^2)$ times lower than the unstructured multi-layer perceptrons. For design guidelines, we propose a unified framework that is applicable to general design problems in wireless networks, which includes graph modeling, neural architecture design, and theory-guided performance enhancement. Extensive simulations, which cover a variety of important problems and network settings, verify our theory and effectiveness of the proposed design framework.
Communication-Efficient Federated Distillation with Active Data Sampling
Mar 14, 2022


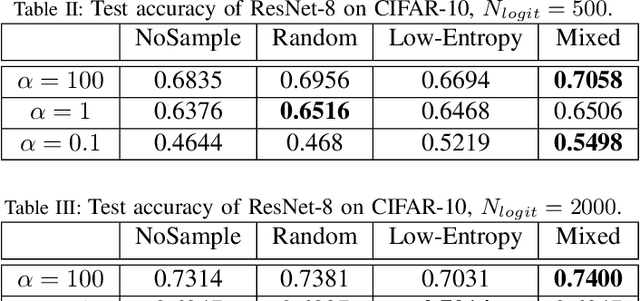
Federated learning (FL) is a promising paradigm to enable privacy-preserving deep learning from distributed data. Most previous works are based on federated average (FedAvg), which, however, faces several critical issues, including a high communication overhead and the difficulty in dealing with heterogeneous model architectures. Federated Distillation (FD) is a recently proposed alternative to enable communication-efficient and robust FL, which achieves orders of magnitude reduction of the communication overhead compared with FedAvg and is flexible to handle heterogeneous models at the clients. However, so far there is no unified algorithmic framework or theoretical analysis for FD-based methods. In this paper, we first present a generic meta-algorithm for FD and investigate the influence of key parameters through empirical experiments. Then, we verify the empirical observations theoretically. Based on the empirical results and theory, we propose a communication-efficient FD algorithm with active data sampling to improve the model performance and reduce the communication overhead. Empirical simulations on benchmark datasets will demonstrate that our proposed algorithm effectively and significantly reduces the communication overhead while achieving a satisfactory performance.