 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedKL: Tackling Data Heterogeneity in Federated Reinforcement Learning by Penalizing KL Divergence
Paper and Code
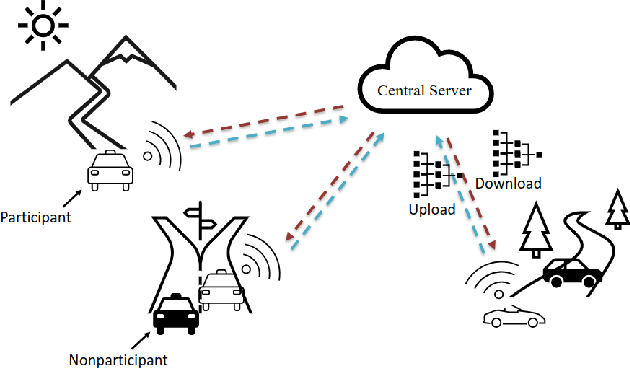

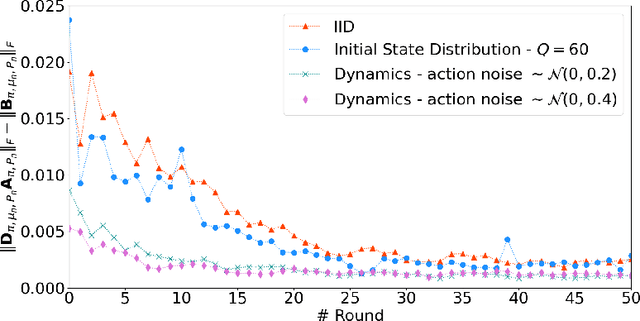
As a distributed learning paradigm, Federated Learning (FL) faces the communication bottleneck issue due to many rounds of model synchronization and aggregation. Heterogeneous data further deteriorates the situation by causing slow convergence. Although the impact of data heterogeneity on supervised FL has been widely studied, the related investigation for Federated Reinforcement Learning (FRL) is still in its infancy. In this paper, we first define the type and level of data heterogeneity for policy gradient based FRL systems. By inspecting the connection between the global and local objective functions, we prove that local training can benefit the global objective, if the local update is properly penalized by the total variation (TV) distance between the local and global policies. A necessary condition for the global policy to be learn-able from the local policy is also derived, which is directly related to the heterogeneity level. Based on the theoretical result, a Kullback-Leibler (KL) divergence based penalty is proposed, which, different from the conventional method that penalizes the model divergence in the parameter space, directly constrains the model outputs in the distribution space. By jointly penalizing the divergence of the local policy from the global policy with a global penalty and constraining each iteration of the local training with a local penalty, the proposed method achieves a better trade-off between training speed (step size) and convergence. Experiment results on two popular RL experiment platforms demonstrate the advantage of the proposed algorithm over existing methods in accelerating and stabilizing the training process with heterogeneous data.