 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLion: Approaching the Hadamard Ideal by Intersecting Spectral and $\ell_{\infty}$ Implicit Biases
Feb 01, 2026Many optimizers can be interpreted as steepest-descent methods under norm-induced geometries, and thus inherit corresponding implicit biases. We introduce \nameA{} (\fullname{}), which combines spectral control from orthogonalized update directions with $\ell_\infty$-style coordinate control from sign updates. \nameA{} forms a Lion-style momentum direction, approximately orthogonalizes it via a few Newton--Schulz iterations, and then applies an entrywise sign, providing an efficient approximation to taking a maximal step over the intersection of the spectral and $\ell_\infty$ constraint sets (a scaled Hadamard-like set for matrix parameters). Despite the strong nonlinearity of orthogonalization and sign, we prove convergence under a mild, empirically verified diagonal-isotropy assumption. Across large-scale language and vision training, including GPT-2 and Llama pretraining, SiT image pretraining, and supervised fine-tuning, \nameA{} matches or outperforms AdamW and Muon under comparable tuning while using only momentum-level optimizer state, and it mitigates optimizer mismatch when fine-tuning AdamW-pretrained checkpoints.
Patient-Similarity Cohort Reasoning in Clinical Text-to-SQL
Jan 14, 2026Real-world clinical text-to-SQL requires reasoning over heterogeneous EHR tables, temporal windows, and patient-similarity cohorts to produce executable queries. We introduce CLINSQL, a benchmark of 633 expert-annotated tasks on MIMIC-IV v3.1 that demands multi-table joins, clinically meaningful filters, and executable SQL. Solving CLINSQL entails navigating schema metadata and clinical coding systems, handling long contexts, and composing multi-step queries beyond traditional text-to-SQL. We evaluate 22 proprietary and open-source models under Chain-of-Thought self-refinement and use rubric-based SQL analysis with execution checks that prioritize critical clinical requirements. Despite recent advances, performance remains far from clinical reliability: on the test set, GPT-5-mini attains 74.7% execution score, DeepSeek-R1 leads open-source at 69.2% and Gemini-2.5-Pro drops from 85.5% on Easy to 67.2% on Hard. Progress on CLINSQL marks tangible advances toward clinically reliable text-to-SQL for real-world EHR analytics.
VidGuard-R1: AI-Generated Video Detection and Explanation via Reasoning MLLMs and RL
Oct 02, 2025With the rapid advancement of AI-generated videos, there is an urgent need for effective detection tools to mitigate societal risks such as misinformation and reputational harm. In addition to accurate classification, it is essential that detection models provide interpretable explanations to ensure transparency for regulators and end users. To address these challenges, we introduce VidGuard-R1, the first video authenticity detector that fine-tunes a multi-modal large language model (MLLM) using group relative policy optimization (GRPO). Our model delivers both highly accurate judgments and insightful reasoning. We curate a challenging dataset of 140k real and AI-generated videos produced by state-of-the-art generation models, carefully designing the generation process to maximize discrimination difficulty. We then fine-tune Qwen-VL using GRPO with two specialized reward models that target temporal artifacts and generation complexity. Extensive experiments demonstrate that VidGuard-R1 achieves state-of-the-art zero-shot performance on existing benchmarks, with additional training pushing accuracy above 95%. Case studies further show that VidGuard-R1 produces precise and interpretable rationales behind its predictions. The code is publicly available at https://VidGuard-R1.github.io.
Benefits and Pitfalls of Reinforcement Learning for Language Model Planning: A Theoretical Perspective
Sep 26, 2025Recent reinforcement learning (RL) methods have substantially enhanced the planning capabilities of Large Language Models (LLMs), yet the theoretical basis for their effectiveness remains elusive. In this work, we investigate RL's benefits and limitations through a tractable graph-based abstraction, focusing on policy gradient (PG) and Q-learning methods. Our theoretical analyses reveal that supervised fine-tuning (SFT) may introduce co-occurrence-based spurious solutions, whereas RL achieves correct planning primarily through exploration, underscoring exploration's role in enabling better generalization. However, we also show that PG suffers from diversity collapse, where output diversity decreases during training and persists even after perfect accuracy is attained. By contrast, Q-learning provides two key advantages: off-policy learning and diversity preservation at convergence. We further demonstrate that careful reward design is necessary to prevent reward hacking in Q-learning. Finally, applying our framework to the real-world planning benchmark Blocksworld, we confirm that these behaviors manifest in practice.
SciVer: Evaluating Foundation Models for Multimodal Scientific Claim Verification
Jun 18, 2025We introduce SciVer, the first benchmark specifically designed to evaluate the ability of foundation models to verify claims within a multimodal scientific context. SciVer consists of 3,000 expert-annotated examples over 1,113 scientific papers, covering four subsets, each representing a common reasoning type in multimodal scientific claim verification. To enable fine-grained evaluation, each example includes expert-annotated supporting evidence. We assess the performance of 21 state-of-the-art multimodal foundation models, including o4-mini, Gemini-2.5-Flash, Llama-3.2-Vision, and Qwen2.5-VL. Our experiment reveals a substantial performance gap between these models and human experts on SciVer. Through an in-depth analysis of retrieval-augmented generation (RAG), and human-conducted error evaluations, we identify critical limitations in current open-source models, offering key insights to advance models' comprehension and reasoning in multimodal scientific literature tasks.
TRAIL: Transferable Robust Adversarial Images via Latent diffusion
May 22, 2025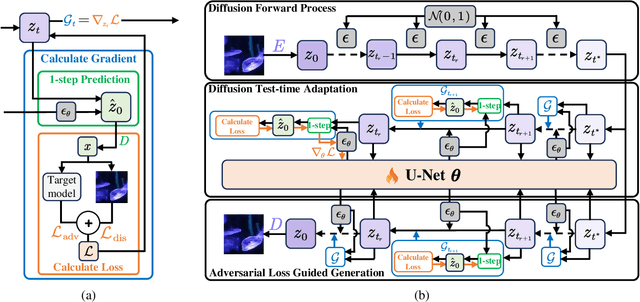
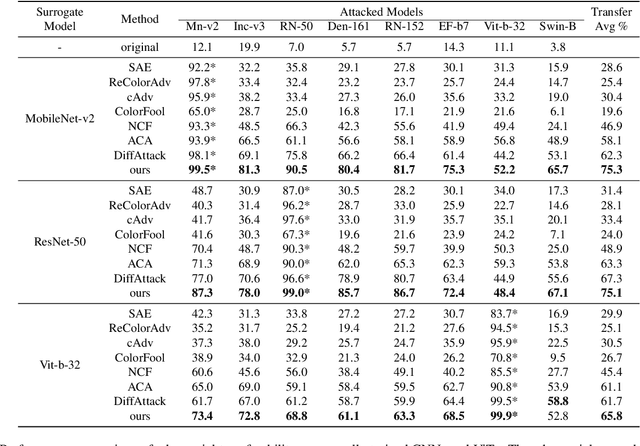
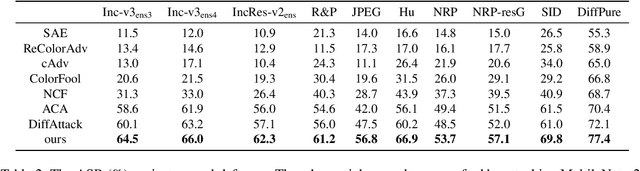

Adversarial attacks exploiting unrestricted natural perturbations present severe security risks to deep learning systems, yet their transferability across models remains limited due to distribution mismatches between generated adversarial features and real-world data. While recent works utilize pre-trained diffusion models as adversarial priors, they still encounter challenges due to the distribution shift between the distribution of ideal adversarial samples and the natural image distribution learned by the diffusion model. To address the challenge, we propose Transferable Robust Adversarial Images via Latent Diffusion (TRAIL), a test-time adaptation framework that enables the model to generate images from a distribution of images with adversarial features and closely resembles the target images. To mitigate the distribution shift, during attacks, TRAIL updates the diffusion U-Net's weights by combining adversarial objectives (to mislead victim models) and perceptual constraints (to preserve image realism). The adapted model then generates adversarial samples through iterative noise injection and denoising guided by these objectives. Experiments demonstrate that TRAIL significantly outperforms state-of-the-art methods in cross-model attack transferability, validating that distribution-aligned adversarial feature synthesis is critical for practical black-box attacks.
Habitizing Diffusion Planning for Efficient and Effective Decision Making
Feb 10, 2025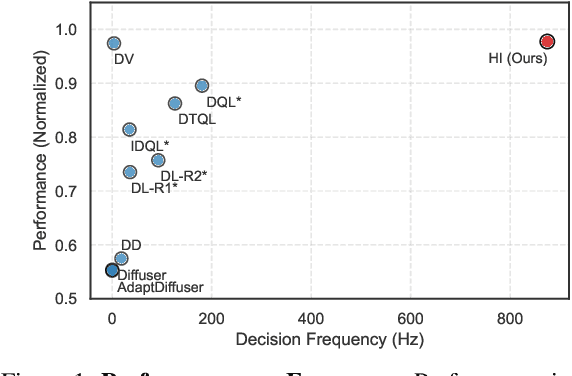
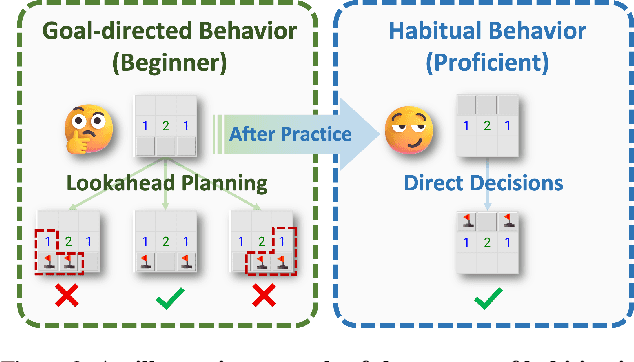
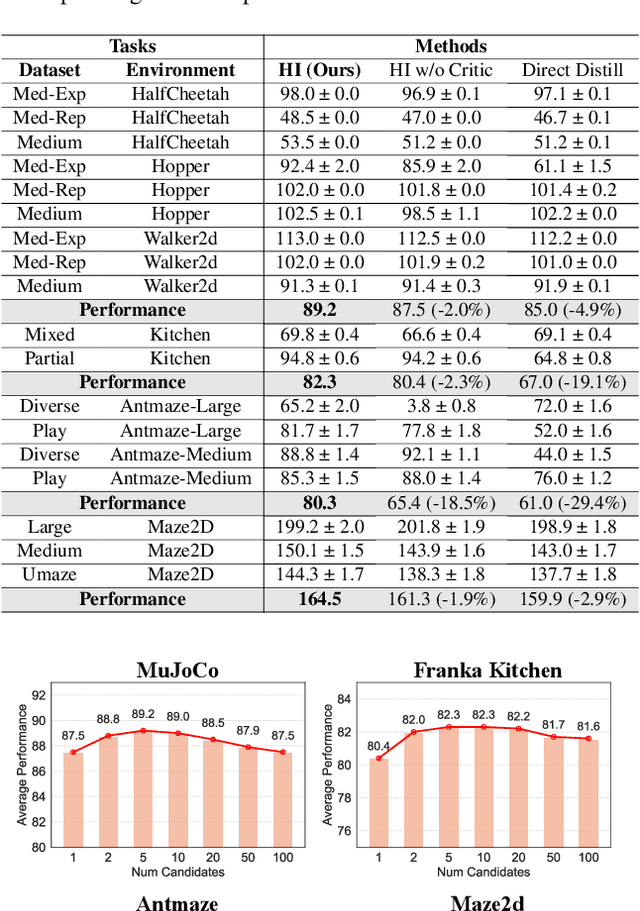
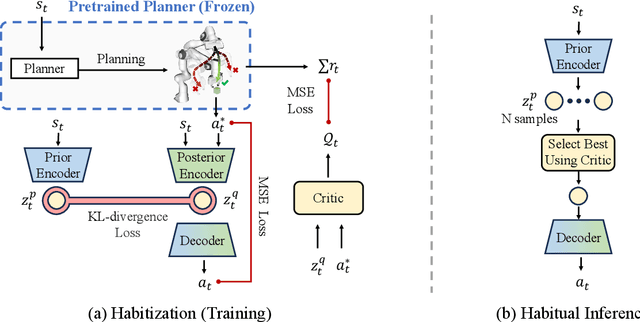
Diffusion models have shown great promise in decision-making, also known as diffusion planning. However, the slow inference speeds limit their potential for broader real-world applications. Here, we introduce Habi, a general framework that transforms powerful but slow diffusion planning models into fast decision-making models, which mimics the cognitive process in the brain that costly goal-directed behavior gradually transitions to efficient habitual behavior with repetitive practice. Even using a laptop CPU, the habitized model can achieve an average 800+ Hz decision-making frequency (faster than previous diffusion planners by orders of magnitude) on standard offline reinforcement learning benchmarks D4RL, while maintaining comparable or even higher performance compared to its corresponding diffusion planner. Our work proposes a fresh perspective of leveraging powerful diffusion models for real-world decision-making tasks. We also provide robust evaluations and analysis, offering insights from both biological and engineering perspectives for efficient and effective decision-making.
Omni-DNA: A Unified Genomic Foundation Model for Cross-Modal and Multi-Task Learning
Feb 05, 2025



Large Language Models (LLMs) demonstrate remarkable generalizability across diverse tasks, yet genomic foundation models (GFMs) still require separate finetuning for each downstream application, creating significant overhead as model sizes grow. Moreover, existing GFMs are constrained by rigid output formats, limiting their applicability to various genomic tasks. In this work, we revisit the transformer-based auto-regressive models and introduce Omni-DNA, a family of cross-modal multi-task models ranging from 20 million to 1 billion parameters. Our approach consists of two stages: (i) pretraining on DNA sequences with next token prediction objective, and (ii) expanding the multi-modal task-specific tokens and finetuning for multiple downstream tasks simultaneously. When evaluated on the Nucleotide Transformer and GB benchmarks, Omni-DNA achieves state-of-the-art performance on 18 out of 26 tasks. Through multi-task finetuning, Omni-DNA addresses 10 acetylation and methylation tasks at once, surpassing models trained on each task individually. Finally, we design two complex genomic tasks, DNA2Function and Needle-in-DNA, which map DNA sequences to textual functional descriptions and images, respectively, indicating Omni-DNA's cross-modal capabilities to broaden the scope of genomic applications. All the models are available through https://huggingface.co/collections/zehui127
A Comprehensive Analysis on LLM-based Node Classification Algorithms
Feb 02, 2025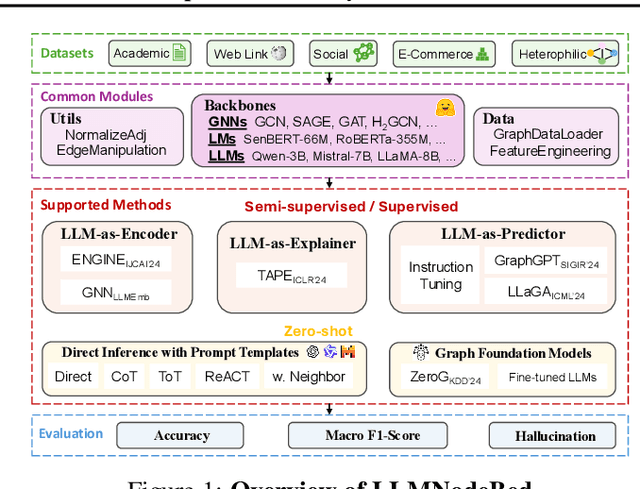
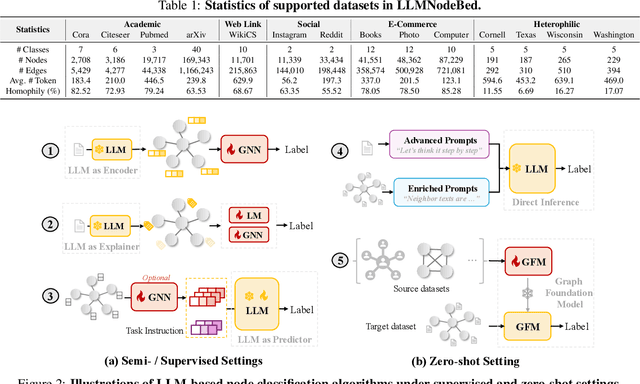
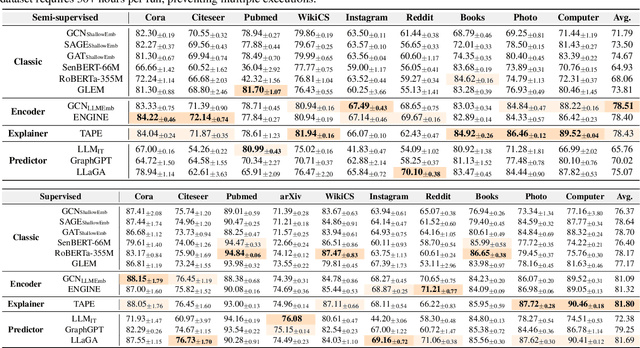
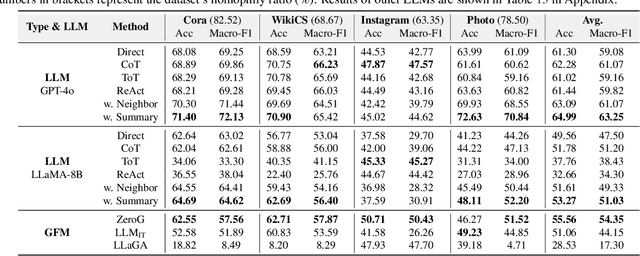
Node classification is a fundamental task in graph analysis, with broad applications across various fields. Recent breakthroughs in Large Language Models (LLMs) have enabled LLM-based approaches for this task. Although many studies demonstrate the impressive performance of LLM-based methods, the lack of clear design guidelines may hinder their practical application. In this work, we aim to establish such guidelines through a fair and systematic comparison of these algorithms. As a first step, we developed LLMNodeBed, a comprehensive codebase and testbed for node classification using LLMs. It includes ten datasets, eight LLM-based algorithms, and three learning paradigms, and is designed for easy extension with new methods and datasets. Subsequently, we conducted extensive experiments, training and evaluating over 2,200 models, to determine the key settings (e.g., learning paradigms and homophily) and components (e.g., model size) that affect performance. Our findings uncover eight insights, e.g., (1) LLM-based methods can significantly outperform traditional methods in a semi-supervised setting, while the advantage is marginal in a supervised setting; (2) Graph Foundation Models can beat open-source LLMs but still fall short of strong LLMs like GPT-4o in a zero-shot setting. We hope that the release of LLMNodeBed, along with our insights, will facilitate reproducible research and inspire future studies in this field. Codes and datasets are released at \href{https://llmnodebed.github.io/}{https://llmnodebed.github.io/}.
Toward Relative Positional Encoding in Spiking Transformers
Jan 28, 2025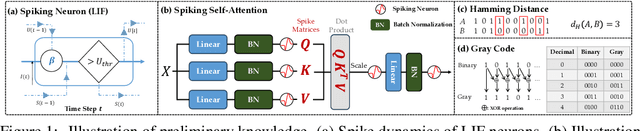

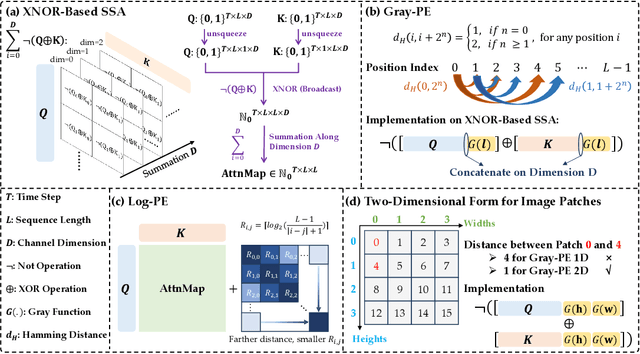

Spiking neural networks (SNNs) are bio-inspired networks that model how neurons in the brain communicate through discrete spikes, which have great potential in various tasks due to their energy efficiency and temporal processing capabilities. SNNs with self-attention mechanisms (Spiking Transformers) have recently shown great advancements in various tasks such as sequential modeling and image classifications. However, integrating positional information, which is essential for capturing sequential relationships in data, remains a challenge in Spiking Transformers. In this paper, we introduce an approximate method for relative positional encoding (RPE) in Spiking Transformers, leveraging Gray Code as the foundation for our approach. We provide comprehensive proof of the method's effectiveness in partially capturing relative positional information for sequential tasks. Additionally, we extend our RPE approach by adapting it to a two-dimensional form suitable for image patch processing. We evaluate the proposed RPE methods on several tasks, including time series forecasting, text classification, and patch-based image classification. Our experimental results demonstrate that the incorporation of RPE significantly enhances performance by effectively capturing relative positional information.