 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning, Large-Scale 3D Molecular Pretraining, Molecular Property
Mar 13, 2025Molecular pretrained representations (MPR) has emerged as a powerful approach for addressing the challenge of limited supervised data in applications such as drug discovery and material design. While early MPR methods relied on 1D sequences and 2D graphs, recent advancements have incorporated 3D conformational information to capture rich atomic interactions. However, these prior models treat molecules merely as discrete atom sets, overlooking the space surrounding them. We argue from a physical perspective that only modeling these discrete points is insufficient. We first present a simple yet insightful observation: naively adding randomly sampled virtual points beyond atoms can surprisingly enhance MPR performance. In light of this, we propose a principled framework that incorporates the entire 3D space spanned by molecules. We implement the framework via a novel Transformer-based architecture, dubbed SpaceFormer, with three key components: (1) grid-based space discretization; (2) grid sampling/merging; and (3) efficient 3D positional encoding. Extensive experiments show that SpaceFormer significantly outperforms previous 3D MPR models across various downstream tasks with limited data, validating the benefit of leveraging the additional 3D space beyond atoms in MPR models.
How Do Large Language Models Understand Graph Patterns? A Benchmark for Graph Pattern Comprehension
Oct 04, 2024



Benchmarking the capabilities and limitations of large language models (LLMs) in graph-related tasks is becoming an increasingly popular and crucial area of research. Recent studies have shown that LLMs exhibit a preliminary ability to understand graph structures and node features. However, the potential of LLMs in graph pattern mining remains largely unexplored. This is a key component in fields such as computational chemistry, biology, and social network analysis. To bridge this gap, this work introduces a comprehensive benchmark to assess LLMs' capabilities in graph pattern tasks. We have developed a benchmark that evaluates whether LLMs can understand graph patterns based on either terminological or topological descriptions. Additionally, our benchmark tests the LLMs' capacity to autonomously discover graph patterns from data. The benchmark encompasses both synthetic and real datasets, and a variety of models, with a total of 11 tasks and 7 models. Our experimental framework is designed for easy expansion to accommodate new models and datasets. Our findings reveal that: (1) LLMs have preliminary abilities to understand graph patterns, with O1-mini outperforming in the majority of tasks; (2) Formatting input data to align with the knowledge acquired during pretraining can enhance performance; (3) The strategies employed by LLMs may differ from those used in conventional algorithms.
On the Expressive Power of Spectral Invariant Graph Neural Networks
Jun 06, 2024Incorporating spectral information to enhance Graph Neural Networks (GNNs) has shown promising results but raises a fundamental challenge due to the inherent ambiguity of eigenvectors. Various architectures have been proposed to address this ambiguity, referred to as spectral invariant architectures. Notable examples include GNNs and Graph Transformers that use spectral distances, spectral projection matrices, or other invariant spectral features. However, the potential expressive power of these spectral invariant architectures remains largely unclear. The goal of this work is to gain a deep theoretical understanding of the expressive power obtainable when using spectral features. We first introduce a unified message-passing framework for designing spectral invariant GNNs, called Eigenspace Projection GNN (EPNN). A comprehensive analysis shows that EPNN essentially unifies all prior spectral invariant architectures, in that they are either strictly less expressive or equivalent to EPNN. A fine-grained expressiveness hierarchy among different architectures is also established. On the other hand, we prove that EPNN itself is bounded by a recently proposed class of Subgraph GNNs, implying that all these spectral invariant architectures are strictly less expressive than 3-WL. Finally, we discuss whether using spectral features can gain additional expressiveness when combined with more expressive GNNs.
Can Graph Learning Improve Task Planning?
May 29, 2024Task planning is emerging as an important research topic alongside the development of large language models (LLMs). It aims to break down complex user requests into solvable sub-tasks, thereby fulfilling the original requests. In this context, the sub-tasks can be naturally viewed as a graph, where the nodes represent the sub-tasks, and the edges denote the dependencies among them. Consequently, task planning is a decision-making problem that involves selecting a connected path or subgraph within the corresponding graph and invoking it. In this paper, we explore graph learning-based methods for task planning, a direction that is orthogonal to the prevalent focus on prompt design. Our interest in graph learning stems from a theoretical discovery: the biases of attention and auto-regressive loss impede LLMs' ability to effectively navigate decision-making on graphs, which is adeptly addressed by graph neural networks (GNNs). This theoretical insight led us to integrate GNNs with LLMs to enhance overall performance. Extensive experiments demonstrate that GNN-based methods surpass existing solutions even without training, and minimal training can further enhance their performance. Additionally, our approach complements prompt engineering and fine-tuning techniques, with performance further enhanced by improved prompts or a fine-tuned model.
Do Efficient Transformers Really Save Computation?
Feb 21, 2024As transformer-based language models are trained on increasingly large datasets and with vast numbers of parameters, finding more efficient alternatives to the standard Transformer has become very valuable. While many efficient Transformers and Transformer alternatives have been proposed, none provide theoretical guarantees that they are a suitable replacement for the standard Transformer. This makes it challenging to identify when to use a specific model and what directions to prioritize for further investigation. In this paper, we aim to understand the capabilities and limitations of efficient Transformers, specifically the Sparse Transformer and the Linear Transformer. We focus on their reasoning capability as exhibited by Chain-of-Thought (CoT) prompts and follow previous works to model them as Dynamic Programming (DP) problems. Our results show that while these models are expressive enough to solve general DP tasks, contrary to expectations, they require a model size that scales with the problem size. Nonetheless, we identify a class of DP problems for which these models can be more efficient than the standard Transformer. We confirm our theoretical results through experiments on representative DP tasks, adding to the understanding of efficient Transformers' practical strengths and weaknesses.
Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness
Jan 16, 2024



Designing expressive Graph Neural Networks (GNNs) is a fundamental topic in the graph learning community. So far, GNN expressiveness has been primarily assessed via the Weisfeiler-Lehman (WL) hierarchy. However, such an expressivity measure has notable limitations: it is inherently coarse, qualitative, and may not well reflect practical requirements (e.g., the ability to encode substructures). In this paper, we introduce a unified framework for quantitatively studying the expressiveness of GNN architectures, addressing all the above limitations. Specifically, we identify a fundamental expressivity measure termed homomorphism expressivity, which quantifies the ability of GNN models to count graphs under homomorphism. Homomorphism expressivity offers a complete and practical assessment tool: the completeness enables direct expressivity comparisons between GNN models, while the practicality allows for understanding concrete GNN abilities such as subgraph counting. By examining four classes of prominent GNNs as case studies, we derive simple, unified, and elegant descriptions of their homomorphism expressivity for both invariant and equivariant settings. Our results provide novel insights into a series of previous work, unify the landscape of different subareas in the community, and settle several open questions. Empirically, extensive experiments on both synthetic and real-world tasks verify our theory, showing that the practical performance of GNN models aligns well with the proposed metric.
Towards Revealing the Mystery behind Chain of Thought: a Theoretical Perspective
May 24, 2023
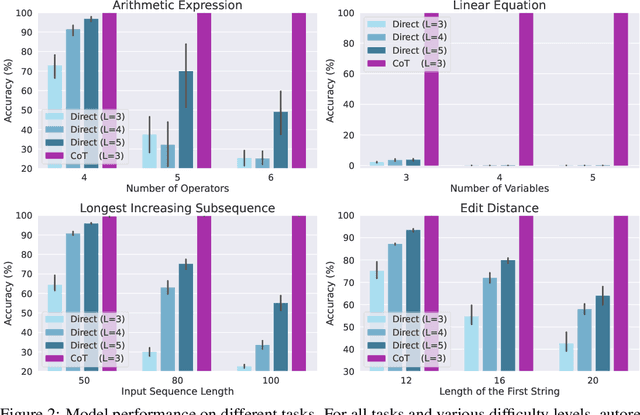
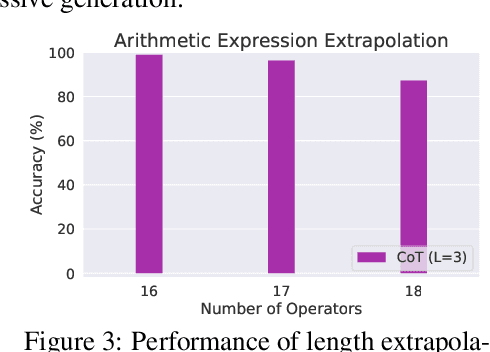
Recent studies have discovered that Chain-of-Thought prompting (CoT) can dramatically improve the performance of Large Language Models (LLMs), particularly when dealing with complex tasks involving mathematics or reasoning. Despite the enormous empirical success, the underlying mechanisms behind CoT and how it unlocks the potential of LLMs remain elusive. In this paper, we take a first step towards theoretically answering these questions. Specifically, we examine the capacity of LLMs with CoT in solving fundamental mathematical and decision-making problems. We start by giving an impossibility result showing that any bounded-depth Transformer cannot directly output correct answers for basic arithmetic/equation tasks unless the model size grows super-polynomially with respect to the input length. In contrast, we then prove by construction that autoregressive Transformers of a constant size suffice to solve both tasks by generating CoT derivations using a commonly-used math language format. Moreover, we show LLMs with CoT are capable of solving a general class of decision-making problems known as Dynamic Programming, thus justifying its power in tackling complex real-world tasks. Finally, extensive experiments on four tasks show that, while Transformers always fail to predict the answers directly, they can consistently learn to generate correct solutions step-by-step given sufficient CoT demonstrations.
Enhanced Sliding Window Superposition Coding for Industrial Automation
Mar 08, 2023The introduction of 5G has changed the wireless communication industry. Whereas previous generations of cellular technology are mainly based on communication for people, the wireless industry is discovering that 5G may be an era of communications that is mainly focused on machine-to-machine communication. The application of Ultra Reliable Low Latency Communication in factory automation is an area of great interest as it unlocks potential applications that traditional wired communications did not allow. In particular, the decrease in the inter-device distance has led to the discussion of coding schemes for these interference-filled channels. To meet the latency and accuracy requirements of URLLC, Non-orthogonal multiple access has been proposed but it comes with associated challenges. In order to combat the issue of interference, an enhanced version of Sliding window superposition coding has been proposed as a method of coding that yields performance gains in scenarios with high interference. This paper examines the abilities of this coding scheme in a broadcast network in 5G to evaluate its robustness in situations where interference is treated as noise in a factory automation setting. This work shows improvements of enhanced sliding window superposition coding over benchmark protocols in the high-reliability requirement regions of block error rates $\approx 10^{-6}$.
A Complete Expressiveness Hierarchy for Subgraph GNNs via Subgraph Weisfeiler-Lehman Tests
Feb 14, 2023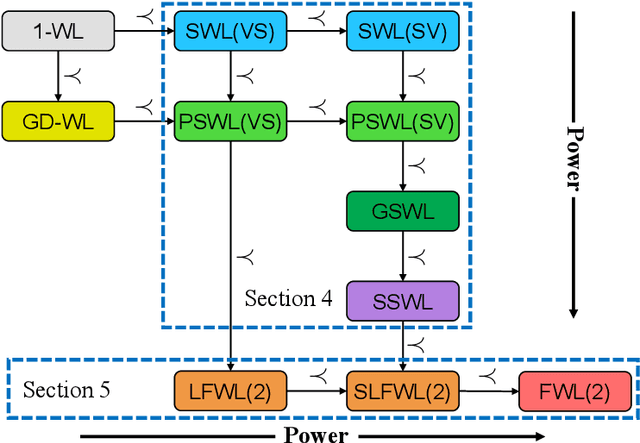
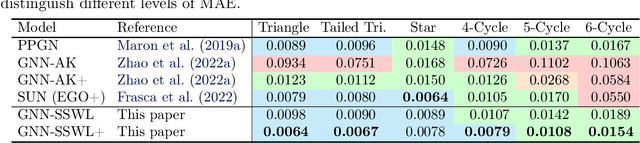
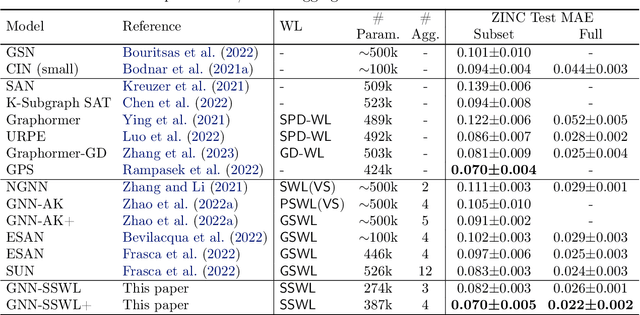
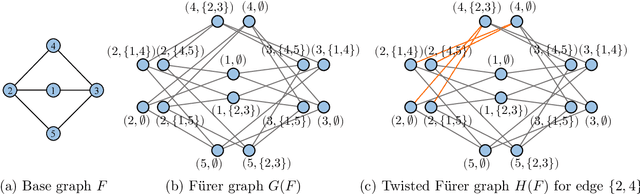
Recently, subgraph GNNs have emerged as an important direction for developing expressive graph neural networks (GNNs). While numerous architectures have been proposed, so far there is still a limited understanding of how various design paradigms differ in terms of expressive power, nor is it clear what design principle achieves maximal expressiveness with minimal architectural complexity. Targeting these fundamental questions, this paper conducts a systematic study of general node-based subgraph GNNs through the lens of Subgraph Weisfeiler-Lehman Tests (SWL). Our central result is to build a complete hierarchy of SWL with strictly growing expressivity. Concretely, we prove that any node-based subgraph GNN falls into one of the six SWL equivalence classes, among which $\mathsf{SSWL}$ achieves the maximal expressive power. We also study how these equivalence classes differ in terms of their practical expressiveness such as encoding graph distance and biconnectivity. In addition, we give a tight expressivity upper bound of all SWL algorithms by establishing a close relation with localized versions of Folklore WL tests (FWL). Overall, our results provide insights into the power of existing subgraph GNNs, guide the design of new architectures, and point out their limitations by revealing an inherent gap with the 2-FWL test. Finally, experiments on the ZINC benchmark demonstrate that $\mathsf{SSWL}$-inspired subgraph GNNs can significantly outperform prior architectures despite great simplicity.
Rethinking the Expressive Power of GNNs via Graph Biconnectivity
Jan 23, 2023Designing expressive Graph Neural Networks (GNNs) is a central topic in learning graph-structured data. While numerous approaches have been proposed to improve GNNs in terms of the Weisfeiler-Lehman (WL) test, generally there is still a lack of deep understanding of what additional power they can systematically and provably gain. In this paper, we take a fundamentally different perspective to study the expressive power of GNNs beyond the WL test. Specifically, we introduce a novel class of expressivity metrics via graph biconnectivity and highlight their importance in both theory and practice. As biconnectivity can be easily calculated using simple algorithms that have linear computational costs, it is natural to expect that popular GNNs can learn it easily as well. However, after a thorough review of prior GNN architectures, we surprisingly find that most of them are not expressive for any of these metrics. The only exception is the ESAN framework (Bevilacqua et al., 2022), for which we give a theoretical justification of its power. We proceed to introduce a principled and more efficient approach, called the Generalized Distance Weisfeiler-Lehman (GD-WL), which is provably expressive for all biconnectivity metrics. Practically, we show GD-WL can be implemented by a Transformer-like architecture that preserves expressiveness and enjoys full parallelizability. A set of experiments on both synthetic and real datasets demonstrates that our approach can consistently outperform prior GNN architectures.