 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHD-Prot: A Protein Language Model for Joint Sequence-Structure Modeling with Continuous Structure Tokens
Dec 17, 2025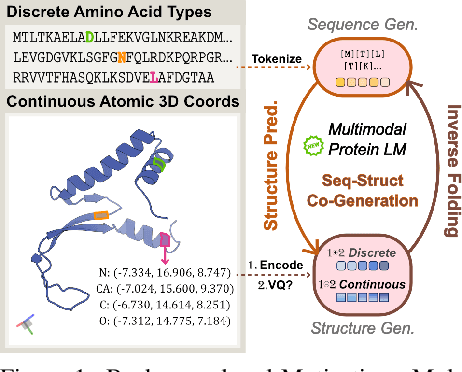
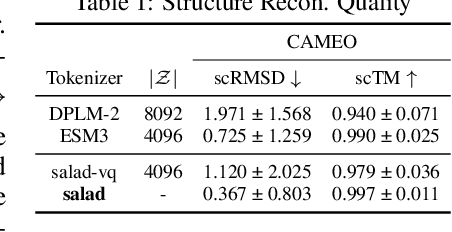
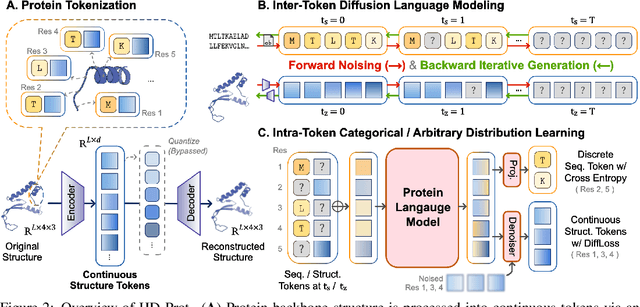
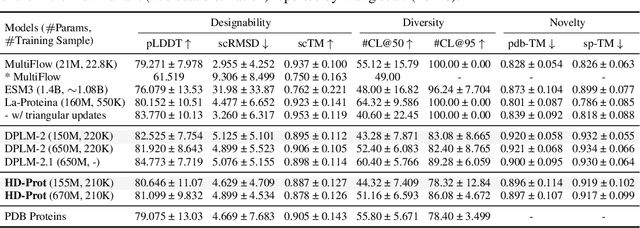
Proteins inherently possess a consistent sequence-structure duality. The abundance of protein sequence data, which can be readily represented as discrete tokens, has driven fruitful developments in protein language models (pLMs). A key remaining challenge, however, is how to effectively integrate continuous structural knowledge into pLMs. Current methods often discretize protein structures to accommodate the language modeling framework, which inevitably results in the loss of fine-grained information and limits the performance potential of multimodal pLMs. In this paper, we argue that such concerns can be circumvented: a sequence-based pLM can be extended to incorporate the structure modality through continuous tokens, i.e., high-fidelity protein structure latents that avoid vector quantization. Specifically, we propose a hybrid diffusion protein language model, HD-Prot, which embeds a continuous-valued diffusion head atop a discrete pLM, enabling seamless operation with both discrete and continuous tokens for joint sequence-structure modeling. It captures inter-token dependencies across modalities through a unified absorbing diffusion process, and estimates per-token distributions via categorical prediction for sequences and continuous diffusion for structures. Extensive empirical results show that HD-Prot achieves competitive performance in unconditional sequence-structure co-generation, motif-scaffolding, protein structure prediction, and inverse folding tasks, performing on par with state-of-the-art multimodal pLMs despite being developed under limited computational resources. It highlights the viability of simultaneously estimating categorical and continuous distributions within a unified language model architecture, offering a promising alternative direction for multimodal pLMs.
Generative Recommendation with Continuous-Token Diffusion
Apr 16, 2025In recent years, there has been a significant trend toward using large language model (LLM)-based recommender systems (RecSys). Current research primarily focuses on representing complex user-item interactions within a discrete space to align with the inherent discrete nature of language models. However, this approach faces limitations due to its discrete nature: (i) information is often compressed during discretization; (ii) the tokenization and generation for the vast number of users and items in real-world scenarios are constrained by a limited vocabulary. Embracing continuous data presents a promising alternative to enhance expressive capabilities, though this approach is still in its early stages. To address this gap, we propose a novel framework, DeftRec, which incorporates \textbf{de}noising di\textbf{f}fusion models to enable LLM-based RecSys to seamlessly support continuous \textbf{t}oken as input and target. First, we introduce a robust tokenizer with a masking operation and an additive K-way architecture to index users and items, capturing their complex collaborative relationships into continuous tokens. Crucially, we develop a denoising diffusion model to process user preferences within continuous domains by conditioning on reasoning content from pre-trained large language model. During the denoising process, we reformulate the objective to include negative interactions, building a comprehensive understanding of user preferences for effective and accurate recommendation generation. Finally, given a continuous token as output, recommendations can be easily generated through score-based retrieval. Extensive experiments demonstrate the effectiveness of the proposed methods, showing that DeftRec surpasses competitive benchmarks, including both traditional and emerging LLM-based RecSys.
A Survey of WebAgents: Towards Next-Generation AI Agents for Web Automation with Large Foundation Models
Mar 30, 2025With the advancement of web techniques, they have significantly revolutionized various aspects of people's lives. Despite the importance of the web, many tasks performed on it are repetitive and time-consuming, negatively impacting overall quality of life. To efficiently handle these tedious daily tasks, one of the most promising approaches is to advance autonomous agents based on Artificial Intelligence (AI) techniques, referred to as AI Agents, as they can operate continuously without fatigue or performance degradation. In the context of the web, leveraging AI Agents -- termed WebAgents -- to automatically assist people in handling tedious daily tasks can dramatically enhance productivity and efficiency. Recently, Large Foundation Models (LFMs) containing billions of parameters have exhibited human-like language understanding and reasoning capabilities, showing proficiency in performing various complex tasks. This naturally raises the question: `Can LFMs be utilized to develop powerful AI Agents that automatically handle web tasks, providing significant convenience to users?' To fully explore the potential of LFMs, extensive research has emerged on WebAgents designed to complete daily web tasks according to user instructions, significantly enhancing the convenience of daily human life. In this survey, we comprehensively review existing research studies on WebAgents across three key aspects: architectures, training, and trustworthiness. Additionally, several promising directions for future research are explored to provide deeper insights.
How Do Large Language Models Understand Graph Patterns? A Benchmark for Graph Pattern Comprehension
Oct 04, 2024



Benchmarking the capabilities and limitations of large language models (LLMs) in graph-related tasks is becoming an increasingly popular and crucial area of research. Recent studies have shown that LLMs exhibit a preliminary ability to understand graph structures and node features. However, the potential of LLMs in graph pattern mining remains largely unexplored. This is a key component in fields such as computational chemistry, biology, and social network analysis. To bridge this gap, this work introduces a comprehensive benchmark to assess LLMs' capabilities in graph pattern tasks. We have developed a benchmark that evaluates whether LLMs can understand graph patterns based on either terminological or topological descriptions. Additionally, our benchmark tests the LLMs' capacity to autonomously discover graph patterns from data. The benchmark encompasses both synthetic and real datasets, and a variety of models, with a total of 11 tasks and 7 models. Our experimental framework is designed for easy expansion to accommodate new models and datasets. Our findings reveal that: (1) LLMs have preliminary abilities to understand graph patterns, with O1-mini outperforming in the majority of tasks; (2) Formatting input data to align with the knowledge acquired during pretraining can enhance performance; (3) The strategies employed by LLMs may differ from those used in conventional algorithms.
SSD4Rec: A Structured State Space Duality Model for Efficient Sequential Recommendation
Sep 02, 2024



Sequential recommendation methods are crucial in modern recommender systems for their remarkable capability to understand a user's changing interests based on past interactions. However, a significant challenge faced by current methods (e.g., RNN- or Transformer-based models) is to effectively and efficiently capture users' preferences by modeling long behavior sequences, which impedes their various applications like short video platforms where user interactions are numerous. Recently, an emerging architecture named Mamba, built on state space models (SSM) with efficient hardware-aware designs, has showcased the tremendous potential for sequence modeling, presenting a compelling avenue for addressing the challenge effectively. Inspired by this, we propose a novel generic and efficient sequential recommendation backbone, SSD4Rec, which explores the seamless adaptation of Mamba for sequential recommendations. Specifically, SSD4Rec marks the variable- and long-length item sequences with sequence registers and processes the item representations with bidirectional Structured State Space Duality (SSD) blocks. This not only allows for hardware-aware matrix multiplication but also empowers outstanding capabilities in variable-length and long-range sequence modeling. Extensive evaluations on four benchmark datasets demonstrate that the proposed model achieves state-of-the-art performance while maintaining near-linear scalability with user sequence length. Our code is publicly available at https://github.com/ZhangYifeng1995/SSD4Rec.
A Survey of Mamba
Aug 02, 2024Deep learning, as a vital technique, has sparked a notable revolution in artificial intelligence. As the most representative architecture, Transformers have empowered numerous advanced models, especially the large language models that comprise billions of parameters, becoming a cornerstone in deep learning. Despite the impressive achievements, Transformers still face inherent limitations, particularly the time-consuming inference resulting from the quadratic computation complexity of attention calculation. Recently, a novel architecture named Mamba, drawing inspiration from classical state space models, has emerged as a promising alternative for building foundation models, delivering comparable modeling abilities to Transformers while preserving near-linear scalability concerning sequence length. This has sparked an increasing number of studies actively exploring Mamba's potential to achieve impressive performance across diverse domains. Given such rapid evolution, there is a critical need for a systematic review that consolidates existing Mamba-empowered models, offering a comprehensive understanding of this emerging model architecture. In this survey, we therefore conduct an in-depth investigation of recent Mamba-associated studies, covering from three main aspects: the advancements of Mamba-based models, the techniques of adapting Mamba to diverse data, and the applications where Mamba can excel. Specifically, we first recall the foundational knowledge of various representative deep learning models and the details of Mamba as preliminaries. Then, to showcase the significance of Mamba, we comprehensively review the related studies focusing on Mamba models' architecture design, data adaptability, and applications. Finally, we present an discussion of current limitations and explore various promising research directions to provide deeper insights for future investigations.
TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendation
Jun 15, 2024



There is a growing interest in utilizing large-scale language models (LLMs) to advance next-generation Recommender Systems (RecSys), driven by their outstanding language understanding and in-context learning capabilities. In this scenario, tokenizing (i.e., indexing) users and items becomes essential for ensuring a seamless alignment of LLMs with recommendations. While several studies have made progress in representing users and items through textual contents or latent representations, challenges remain in efficiently capturing high-order collaborative knowledge into discrete tokens that are compatible with LLMs. Additionally, the majority of existing tokenization approaches often face difficulties in generalizing effectively to new/unseen users or items that were not in the training corpus. To address these challenges, we propose a novel framework called TokenRec, which introduces not only an effective ID tokenization strategy but also an efficient retrieval paradigm for LLM-based recommendations. Specifically, our tokenization strategy, Masked Vector-Quantized (MQ) Tokenizer, involves quantizing the masked user/item representations learned from collaborative filtering into discrete tokens, thus achieving a smooth incorporation of high-order collaborative knowledge and a generalizable tokenization of users and items for LLM-based RecSys. Meanwhile, our generative retrieval paradigm is designed to efficiently recommend top-$K$ items for users to eliminate the need for the time-consuming auto-regressive decoding and beam search processes used by LLMs, thus significantly reducing inference time. Comprehensive experiments validate the effectiveness of the proposed methods, demonstrating that TokenRec outperforms competitive benchmarks, including both traditional recommender systems and emerging LLM-based recommender systems.
A physics-informed and attention-based graph learning approach for regional electric vehicle charging demand prediction
Sep 11, 2023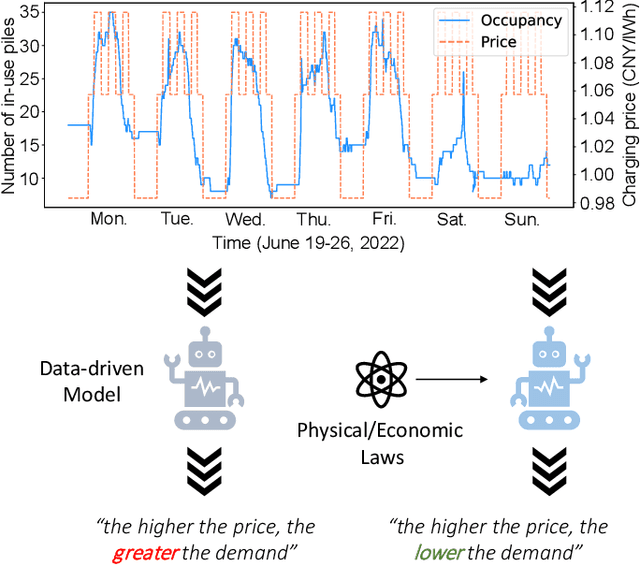
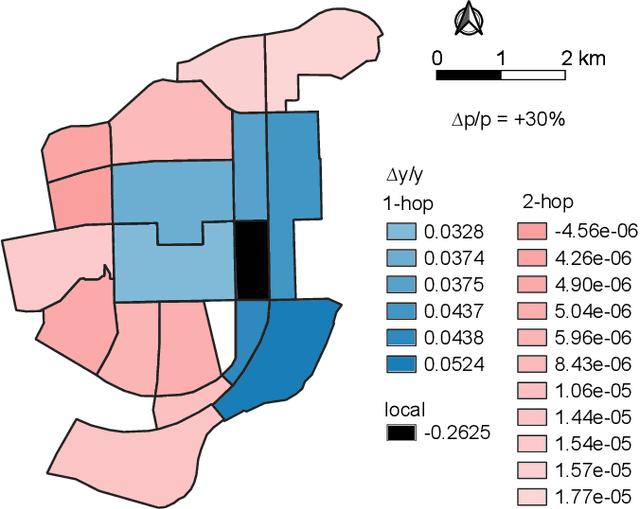
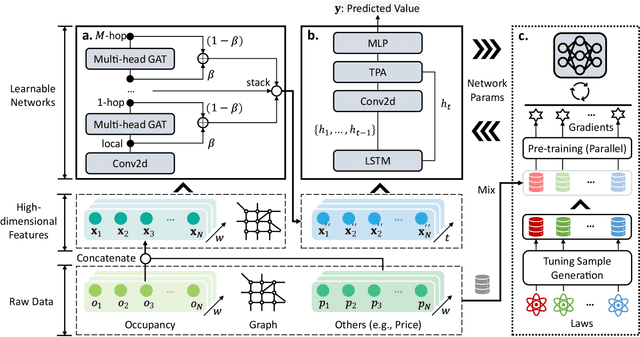
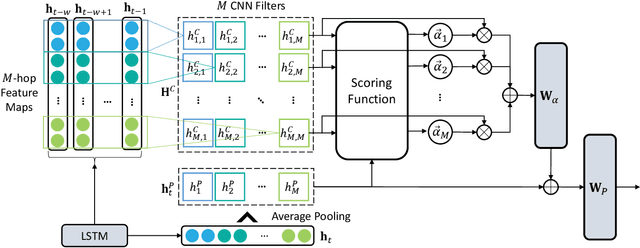
Along with the proliferation of electric vehicles (EVs), optimizing the use of EV charging space can significantly alleviate the growing load on intelligent transportation systems. As the foundation to achieve such an optimization, a spatiotemporal method for EV charging demand prediction in urban areas is required. Although several solutions have been proposed by using data-driven deep learning methods, it can be found that these performance-oriented methods may suffer from misinterpretations to correctly handle the reverse relationship between charging demands and prices. To tackle the emerging challenges of training an accurate and interpretable prediction model, this paper proposes a novel approach that enables the integration of graph and temporal attention mechanisms for feature extraction and the usage of physic-informed meta-learning in the model pre-training step for knowledge transfer. Evaluation results on a dataset of 18,013 EV charging piles in Shenzhen, China, show that the proposed approach, named PAG, can achieve state-of-the-art forecasting performance and the ability in understanding the adaptive changes in charging demands caused by price fluctuations.