 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemKG-RAG: Multimodal Knowledge Graph-Enhanced RAG for Visual Question Answering
Aug 07, 2025Recently, Retrieval-Augmented Generation (RAG) has been proposed to expand internal knowledge of Multimodal Large Language Models (MLLMs) by incorporating external knowledge databases into the generation process, which is widely used for knowledge-based Visual Question Answering (VQA) tasks. Despite impressive advancements, vanilla RAG-based VQA methods that rely on unstructured documents and overlook the structural relationships among knowledge elements frequently introduce irrelevant or misleading content, reducing answer accuracy and reliability. To overcome these challenges, a promising solution is to integrate multimodal knowledge graphs (KGs) into RAG-based VQA frameworks to enhance the generation by introducing structured multimodal knowledge. Therefore, in this paper, we propose a novel multimodal knowledge-augmented generation framework (mKG-RAG) based on multimodal KGs for knowledge-intensive VQA tasks. Specifically, our approach leverages MLLM-powered keyword extraction and vision-text matching to distill semantically consistent and modality-aligned entities/relationships from multimodal documents, constructing high-quality multimodal KGs as structured knowledge representations. In addition, a dual-stage retrieval strategy equipped with a question-aware multimodal retriever is introduced to improve retrieval efficiency while refining precision. Comprehensive experiments demonstrate that our approach significantly outperforms existing methods, setting a new state-of-the-art for knowledge-based VQA.
Exploring Backdoor Attack and Defense for LLM-empowered Recommendations
Apr 15, 2025The fusion of Large Language Models (LLMs) with recommender systems (RecSys) has dramatically advanced personalized recommendations and drawn extensive attention. Despite the impressive progress, the safety of LLM-based RecSys against backdoor attacks remains largely under-explored. In this paper, we raise a new problem: Can a backdoor with a specific trigger be injected into LLM-based Recsys, leading to the manipulation of the recommendation responses when the backdoor trigger is appended to an item's title? To investigate the vulnerabilities of LLM-based RecSys under backdoor attacks, we propose a new attack framework termed Backdoor Injection Poisoning for RecSys (BadRec). BadRec perturbs the items' titles with triggers and employs several fake users to interact with these items, effectively poisoning the training set and injecting backdoors into LLM-based RecSys. Comprehensive experiments reveal that poisoning just 1% of the training data with adversarial examples is sufficient to successfully implant backdoors, enabling manipulation of recommendations. To further mitigate such a security threat, we propose a universal defense strategy called Poison Scanner (P-Scanner). Specifically, we introduce an LLM-based poison scanner to detect the poisoned items by leveraging the powerful language understanding and rich knowledge of LLMs. A trigger augmentation agent is employed to generate diverse synthetic triggers to guide the poison scanner in learning domain-specific knowledge of the poisoned item detection task. Extensive experiments on three real-world datasets validate the effectiveness of the proposed P-Scanner.
Retrieval-Augmented Purifier for Robust LLM-Empowered Recommendation
Apr 03, 2025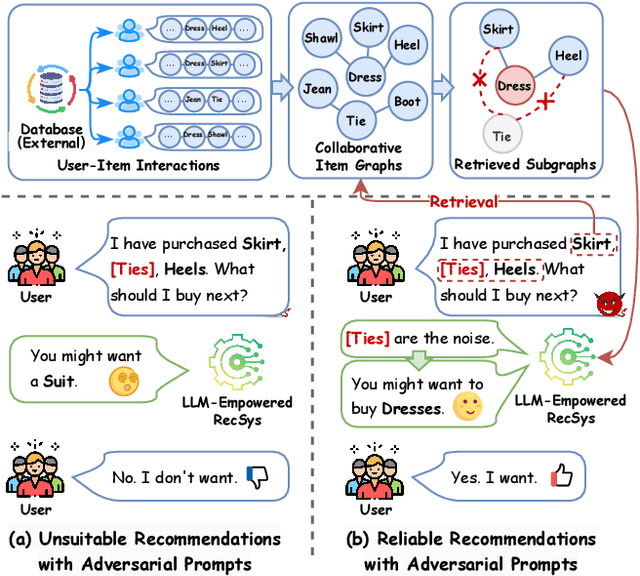
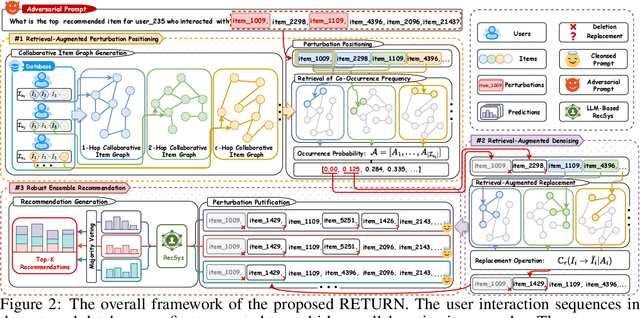
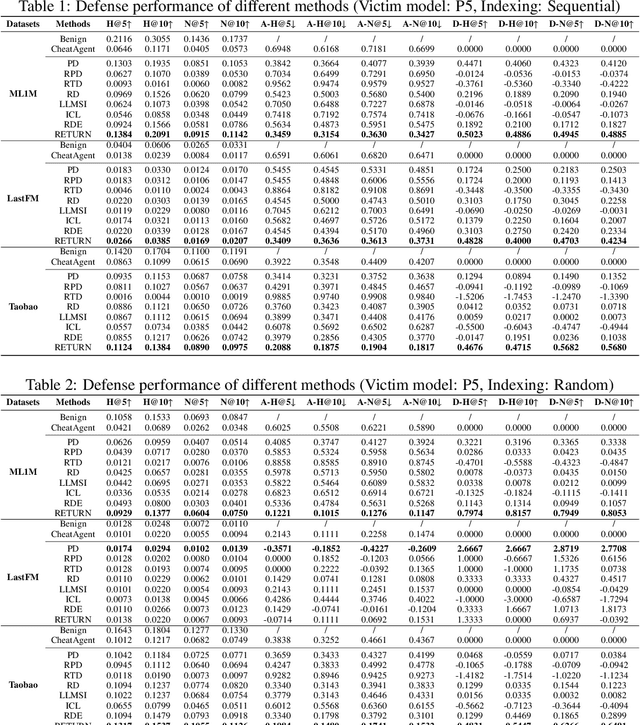
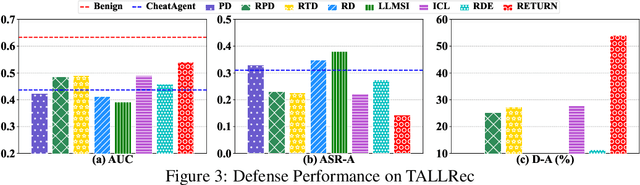
Recently, Large Language Model (LLM)-empowered recommender systems have revolutionized personalized recommendation frameworks and attracted extensive attention. Despite the remarkable success, existing LLM-empowered RecSys have been demonstrated to be highly vulnerable to minor perturbations. To mitigate the negative impact of such vulnerabilities, one potential solution is to employ collaborative signals based on item-item co-occurrence to purify the malicious collaborative knowledge from the user's historical interactions inserted by attackers. On the other hand, due to the capabilities to expand insufficient internal knowledge of LLMs, Retrieval-Augmented Generation (RAG) techniques provide unprecedented opportunities to enhance the robustness of LLM-empowered recommender systems by introducing external collaborative knowledge. Therefore, in this paper, we propose a novel framework (RETURN) by retrieving external collaborative signals to purify the poisoned user profiles and enhance the robustness of LLM-empowered RecSys in a plug-and-play manner. Specifically, retrieval-augmented perturbation positioning is proposed to identify potential perturbations within the users' historical sequences by retrieving external knowledge from collaborative item graphs. After that, we further retrieve the collaborative knowledge to cleanse the perturbations by using either deletion or replacement strategies and introduce a robust ensemble recommendation strategy to generate final robust predictions. Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed RETURN.
A Survey of WebAgents: Towards Next-Generation AI Agents for Web Automation with Large Foundation Models
Mar 30, 2025With the advancement of web techniques, they have significantly revolutionized various aspects of people's lives. Despite the importance of the web, many tasks performed on it are repetitive and time-consuming, negatively impacting overall quality of life. To efficiently handle these tedious daily tasks, one of the most promising approaches is to advance autonomous agents based on Artificial Intelligence (AI) techniques, referred to as AI Agents, as they can operate continuously without fatigue or performance degradation. In the context of the web, leveraging AI Agents -- termed WebAgents -- to automatically assist people in handling tedious daily tasks can dramatically enhance productivity and efficiency. Recently, Large Foundation Models (LFMs) containing billions of parameters have exhibited human-like language understanding and reasoning capabilities, showing proficiency in performing various complex tasks. This naturally raises the question: `Can LFMs be utilized to develop powerful AI Agents that automatically handle web tasks, providing significant convenience to users?' To fully explore the potential of LFMs, extensive research has emerged on WebAgents designed to complete daily web tasks according to user instructions, significantly enhancing the convenience of daily human life. In this survey, we comprehensively review existing research studies on WebAgents across three key aspects: architectures, training, and trustworthiness. Additionally, several promising directions for future research are explored to provide deeper insights.
SSD4Rec: A Structured State Space Duality Model for Efficient Sequential Recommendation
Sep 02, 2024



Sequential recommendation methods are crucial in modern recommender systems for their remarkable capability to understand a user's changing interests based on past interactions. However, a significant challenge faced by current methods (e.g., RNN- or Transformer-based models) is to effectively and efficiently capture users' preferences by modeling long behavior sequences, which impedes their various applications like short video platforms where user interactions are numerous. Recently, an emerging architecture named Mamba, built on state space models (SSM) with efficient hardware-aware designs, has showcased the tremendous potential for sequence modeling, presenting a compelling avenue for addressing the challenge effectively. Inspired by this, we propose a novel generic and efficient sequential recommendation backbone, SSD4Rec, which explores the seamless adaptation of Mamba for sequential recommendations. Specifically, SSD4Rec marks the variable- and long-length item sequences with sequence registers and processes the item representations with bidirectional Structured State Space Duality (SSD) blocks. This not only allows for hardware-aware matrix multiplication but also empowers outstanding capabilities in variable-length and long-range sequence modeling. Extensive evaluations on four benchmark datasets demonstrate that the proposed model achieves state-of-the-art performance while maintaining near-linear scalability with user sequence length. Our code is publicly available at https://github.com/ZhangYifeng1995/SSD4Rec.
A Survey of Mamba
Aug 02, 2024Deep learning, as a vital technique, has sparked a notable revolution in artificial intelligence. As the most representative architecture, Transformers have empowered numerous advanced models, especially the large language models that comprise billions of parameters, becoming a cornerstone in deep learning. Despite the impressive achievements, Transformers still face inherent limitations, particularly the time-consuming inference resulting from the quadratic computation complexity of attention calculation. Recently, a novel architecture named Mamba, drawing inspiration from classical state space models, has emerged as a promising alternative for building foundation models, delivering comparable modeling abilities to Transformers while preserving near-linear scalability concerning sequence length. This has sparked an increasing number of studies actively exploring Mamba's potential to achieve impressive performance across diverse domains. Given such rapid evolution, there is a critical need for a systematic review that consolidates existing Mamba-empowered models, offering a comprehensive understanding of this emerging model architecture. In this survey, we therefore conduct an in-depth investigation of recent Mamba-associated studies, covering from three main aspects: the advancements of Mamba-based models, the techniques of adapting Mamba to diverse data, and the applications where Mamba can excel. Specifically, we first recall the foundational knowledge of various representative deep learning models and the details of Mamba as preliminaries. Then, to showcase the significance of Mamba, we comprehensively review the related studies focusing on Mamba models' architecture design, data adaptability, and applications. Finally, we present an discussion of current limitations and explore various promising research directions to provide deeper insights for future investigations.
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
May 10, 2024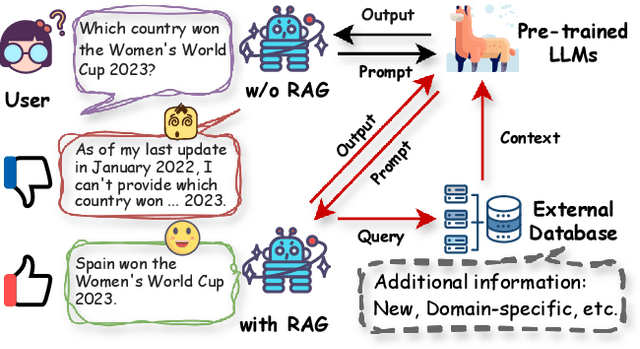
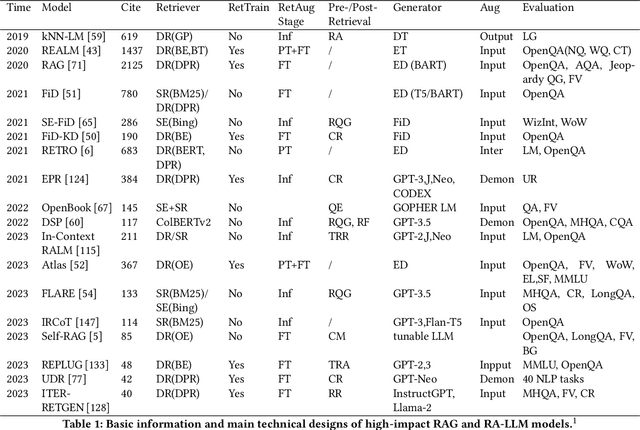
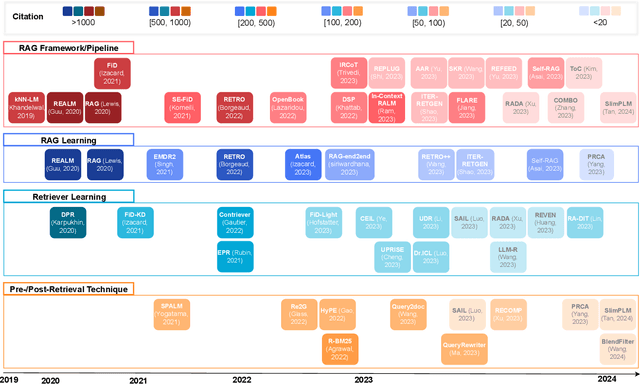
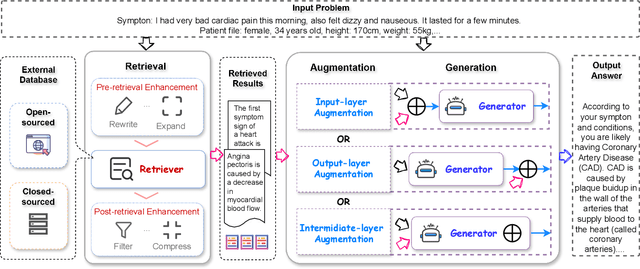
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) techniques can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-generated content (AIGC), the powerful capacity of retrieval in RAG in providing additional knowledge enables retrieval-augmented generation to assist existing generative AI in producing high-quality outputs. Recently, large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, retrieval-augmented large language models have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in retrieval-augmented large language models (RA-LLMs), covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we categorize mainstream relevant work by application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research.