 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Perturbation may Better Reflect the Uncertainty in LLM Reasoning
Feb 02, 2026Large language Models (LLMs) have achieved significant breakthroughs across diverse domains; however, they can still produce unreliable or misleading outputs. For responsible LLM application, Uncertainty Quantification (UQ) techniques are used to estimate a model's uncertainty about its outputs, indicating the likelihood that those outputs may be problematic. For LLM reasoning tasks, it is essential to estimate the uncertainty not only for the final answer, but also for the intermediate steps of the reasoning, as this can enable more fine-grained and targeted interventions. In this study, we explore what UQ metrics better reflect the LLM's ``intermediate uncertainty''during reasoning. Our study reveals that an LLMs' incorrect reasoning steps tend to contain tokens which are highly sensitive to the perturbations on the preceding token embeddings. In this way, incorrect (uncertain) intermediate steps can be readily identified using this sensitivity score as guidance in practice. In our experiments, we show such perturbation-based metric achieves stronger uncertainty quantification performance compared with baseline methods such as token (generation) probability and token entropy. Besides, different from approaches that rely on multiple sampling, the perturbation-based metrics offer better simplicity and efficiency.
Interpretable Probability Estimation with LLMs via Shapley Reconstruction
Jan 14, 2026Large Language Models (LLMs) demonstrate potential to estimate the probability of uncertain events, by leveraging their extensive knowledge and reasoning capabilities. This ability can be applied to support intelligent decision-making across diverse fields, such as financial forecasting and preventive healthcare. However, directly prompting LLMs for probability estimation faces significant challenges: their outputs are often noisy, and the underlying predicting process is opaque. In this paper, we propose PRISM: Probability Reconstruction via Shapley Measures, a framework that brings transparency and precision to LLM-based probability estimation. PRISM decomposes an LLM's prediction by quantifying the marginal contribution of each input factor using Shapley values. These factor-level contributions are then aggregated to reconstruct a calibrated final estimate. In our experiments, we demonstrate PRISM improves predictive accuracy over direct prompting and other baselines, across multiple domains including finance, healthcare, and agriculture. Beyond performance, PRISM provides a transparent prediction pipeline: our case studies visualize how individual factors shape the final estimate, helping build trust in LLM-based decision support systems.
How Do Large Language Models Understand Graph Patterns? A Benchmark for Graph Pattern Comprehension
Oct 04, 2024



Benchmarking the capabilities and limitations of large language models (LLMs) in graph-related tasks is becoming an increasingly popular and crucial area of research. Recent studies have shown that LLMs exhibit a preliminary ability to understand graph structures and node features. However, the potential of LLMs in graph pattern mining remains largely unexplored. This is a key component in fields such as computational chemistry, biology, and social network analysis. To bridge this gap, this work introduces a comprehensive benchmark to assess LLMs' capabilities in graph pattern tasks. We have developed a benchmark that evaluates whether LLMs can understand graph patterns based on either terminological or topological descriptions. Additionally, our benchmark tests the LLMs' capacity to autonomously discover graph patterns from data. The benchmark encompasses both synthetic and real datasets, and a variety of models, with a total of 11 tasks and 7 models. Our experimental framework is designed for easy expansion to accommodate new models and datasets. Our findings reveal that: (1) LLMs have preliminary abilities to understand graph patterns, with O1-mini outperforming in the majority of tasks; (2) Formatting input data to align with the knowledge acquired during pretraining can enhance performance; (3) The strategies employed by LLMs may differ from those used in conventional algorithms.
Revisiting the Graph Reasoning Ability of Large Language Models: Case Studies in Translation, Connectivity and Shortest Path
Aug 18, 2024
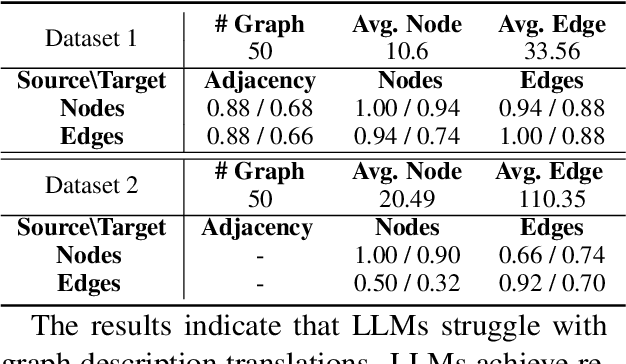

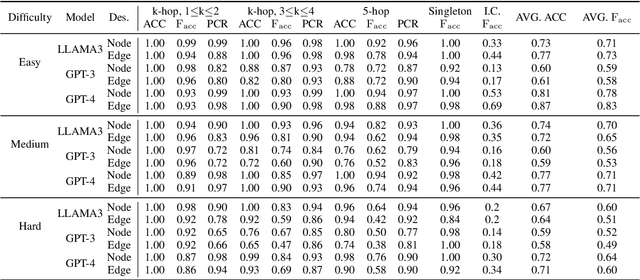
Large Language Models (LLMs) have achieved great success in various reasoning tasks. In this work, we focus on the graph reasoning ability of LLMs. Although theoretical studies proved that LLMs are capable of handling graph reasoning tasks, empirical evaluations reveal numerous failures. To deepen our understanding on this discrepancy, we revisit the ability of LLMs on three fundamental graph tasks: graph description translation, graph connectivity, and the shortest-path problem. Our findings suggest that LLMs can fail to understand graph structures through text descriptions and exhibit varying performance for all these three fundamental tasks. Meanwhile, we perform a real-world investigation on knowledge graphs and make consistent observations with our findings. The codes and datasets are available.