 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Graph Reasoning Ability of Large Language Models: Case Studies in Translation, Connectivity and Shortest Path
Paper and Code
Aug 18, 2024
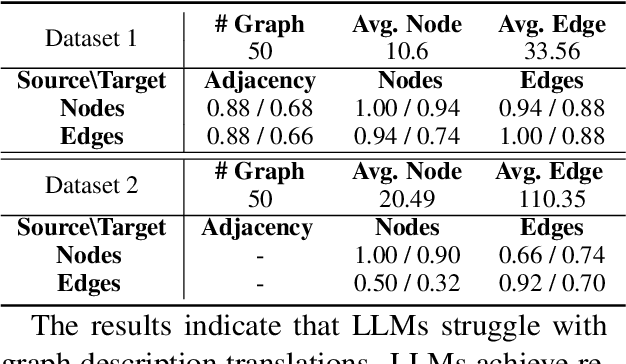

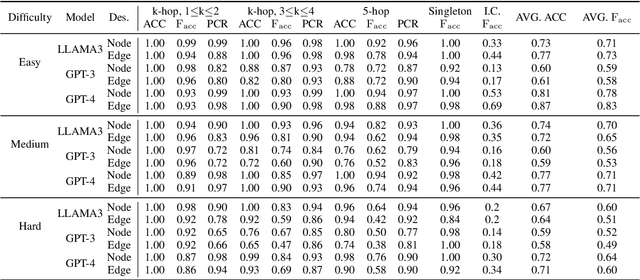
Large Language Models (LLMs) have achieved great success in various reasoning tasks. In this work, we focus on the graph reasoning ability of LLMs. Although theoretical studies proved that LLMs are capable of handling graph reasoning tasks, empirical evaluations reveal numerous failures. To deepen our understanding on this discrepancy, we revisit the ability of LLMs on three fundamental graph tasks: graph description translation, graph connectivity, and the shortest-path problem. Our findings suggest that LLMs can fail to understand graph structures through text descriptions and exhibit varying performance for all these three fundamental tasks. Meanwhile, we perform a real-world investigation on knowledge graphs and make consistent observations with our findings. The codes and datasets are available.