 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaffold-Conditioned Preference Triplets for Controllable Molecular Optimization with Large Language Models
Apr 14, 2026Molecular property optimization is central to drug discovery, yet many deep learning methods rely on black-box scoring and offer limited control over scaffold preservation, often producing unstable or biologically implausible edits. While large language models (LLMs) are promising molecular generators, optimization remains constrained by the lack of chemistry-grounded preference supervision and principled data curation. We introduce \textbf{Scaffold-Conditioned Preference Triplets (SCPT)}, a pipeline that constructs similarity-constrained triplets $\langle\text{scaffold}, \text{better}, \text{worse}\rangle$ via scaffold alignment and chemistry-driven filters for validity, synthesizability, and meaningful property gains. Using these preferences, we align a pretrained molecular LLM as a conditional editor, enabling property-improving edits that retain the scaffold. Across single- and multi-objective benchmarks, SCPT improves optimization success and property gains while maintaining higher scaffold similarity than competitive baselines. Compared with representative non-LLM molecular optimization methods, SCPT-trained LLMs are better suited to scaffold-constrained and multi-objective optimization. In addition, models trained on single-property and two-property supervision generalize effectively to three-property tasks, indicating promising extrapolative generalization under limited higher-order supervision. SCPT also provides controllable data-construction knobs that yield a predictable similarity-gain frontier, enabling systematic adaptation to diverse optimization regimes.
SpecXMaster Technical Report
Mar 24, 2026Intelligent spectroscopy serves as a pivotal element in AI-driven closed-loop scientific discovery, functioning as the critical bridge between matter structure and artificial intelligence. However, conventional expert-dependent spectral interpretation encounters substantial hurdles, including susceptibility to human bias and error, dependence on limited specialized expertise, and variability across interpreters. To address these challenges, we propose SpecXMaster, an intelligent framework leveraging Agentic Reinforcement Learning (RL) for NMR molecular spectral interpretation. SpecXMaster enables automated extraction of multiplicity information from both 1H and 13C spectra directly from raw FID (free induction decay) data. This end-to-end pipeline enables fully automated interpretation of NMR spectra into chemical structures. It demonstrates superior performance across multiple public NMR interpretation benchmarks and has been refined through iterative evaluations by professional chemical spectroscopists. We believe that SpecXMaster, as a novel methodological paradigm for spectral interpretation, will have a profound impact on the organic chemistry community.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
Uni-3DAR: Unified 3D Generation and Understanding via Autoregression on Compressed Spatial Tokens
Mar 21, 2025Recent advancements in large language models and their multi-modal extensions have demonstrated the effectiveness of unifying generation and understanding through autoregressive next-token prediction. However, despite the critical role of 3D structural generation and understanding (3D GU) in AI for science, these tasks have largely evolved independently, with autoregressive methods remaining underexplored. To bridge this gap, we introduce Uni-3DAR, a unified framework that seamlessly integrates 3D GU tasks via autoregressive prediction. At its core, Uni-3DAR employs a novel hierarchical tokenization that compresses 3D space using an octree, leveraging the inherent sparsity of 3D structures. It then applies an additional tokenization for fine-grained structural details, capturing key attributes such as atom types and precise spatial coordinates in microscopic 3D structures. We further propose two optimizations to enhance efficiency and effectiveness. The first is a two-level subtree compression strategy, which reduces the octree token sequence by up to 8x. The second is a masked next-token prediction mechanism tailored for dynamically varying token positions, significantly boosting model performance. By combining these strategies, Uni-3DAR successfully unifies diverse 3D GU tasks within a single autoregressive framework. Extensive experiments across multiple microscopic 3D GU tasks, including molecules, proteins, polymers, and crystals, validate its effectiveness and versatility. Notably, Uni-3DAR surpasses previous state-of-the-art diffusion models by a substantial margin, achieving up to 256\% relative improvement while delivering inference speeds up to 21.8x faster. The code is publicly available at https://github.com/dptech-corp/Uni-3DAR.
Representation Learning, Large-Scale 3D Molecular Pretraining, Molecular Property
Mar 13, 2025Molecular pretrained representations (MPR) has emerged as a powerful approach for addressing the challenge of limited supervised data in applications such as drug discovery and material design. While early MPR methods relied on 1D sequences and 2D graphs, recent advancements have incorporated 3D conformational information to capture rich atomic interactions. However, these prior models treat molecules merely as discrete atom sets, overlooking the space surrounding them. We argue from a physical perspective that only modeling these discrete points is insufficient. We first present a simple yet insightful observation: naively adding randomly sampled virtual points beyond atoms can surprisingly enhance MPR performance. In light of this, we propose a principled framework that incorporates the entire 3D space spanned by molecules. We implement the framework via a novel Transformer-based architecture, dubbed SpaceFormer, with three key components: (1) grid-based space discretization; (2) grid sampling/merging; and (3) efficient 3D positional encoding. Extensive experiments show that SpaceFormer significantly outperforms previous 3D MPR models across various downstream tasks with limited data, validating the benefit of leveraging the additional 3D space beyond atoms in MPR models.
Uni-Mol2: Exploring Molecular Pretraining Model at Scale
Jun 21, 2024



In recent years, pretraining models have made significant advancements in the fields of natural language processing (NLP), computer vision (CV), and life sciences. The significant advancements in NLP and CV are predominantly driven by the expansion of model parameters and data size, a phenomenon now recognized as the scaling laws. However, research exploring scaling law in molecular pretraining models remains unexplored. In this work, we present Uni-Mol2 , an innovative molecular pretraining model that leverages a two-track transformer to effectively integrate features at the atomic level, graph level, and geometry structure level. Along with this, we systematically investigate the scaling law within molecular pretraining models, characterizing the power-law correlations between validation loss and model size, dataset size, and computational resources. Consequently, we successfully scale Uni-Mol2 to 1.1 billion parameters through pretraining on 800 million conformations, making it the largest molecular pretraining model to date. Extensive experiments show consistent improvement in the downstream tasks as the model size grows. The Uni-Mol2 with 1.1B parameters also outperforms existing methods, achieving an average 27% improvement on the QM9 and 14% on COMPAS-1D dataset.
Uni-QSAR: an Auto-ML Tool for Molecular Property Prediction
Apr 24, 2023



Recently deep learning based quantitative structure-activity relationship (QSAR) models has shown surpassing performance than traditional methods for property prediction tasks in drug discovery. However, most DL based QSAR models are restricted to limited labeled data to achieve better performance, and also are sensitive to model scale and hyper-parameters. In this paper, we propose Uni-QSAR, a powerful Auto-ML tool for molecule property prediction tasks. Uni-QSAR combines molecular representation learning (MRL) of 1D sequential tokens, 2D topology graphs, and 3D conformers with pretraining models to leverage rich representation from large-scale unlabeled data. Without any manual fine-tuning or model selection, Uni-QSAR outperforms SOTA in 21/22 tasks of the Therapeutic Data Commons (TDC) benchmark under designed parallel workflow, with an average performance improvement of 6.09\%. Furthermore, we demonstrate the practical usefulness of Uni-QSAR in drug discovery domains.
Categorical Difference and Related Brain Regions of the Attentional Blink Effect
Nov 03, 2021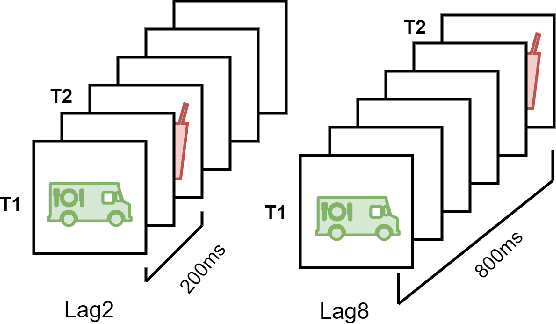
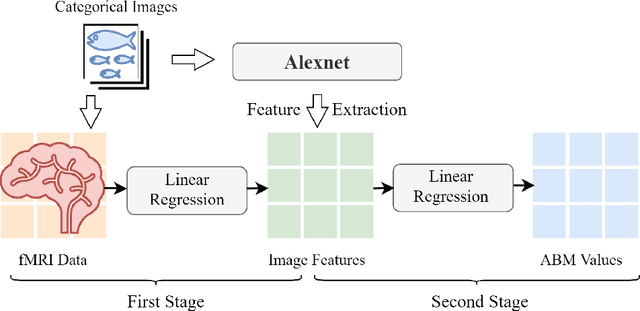
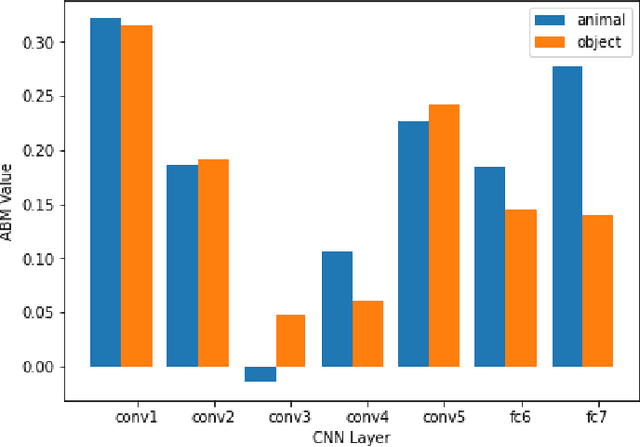
Attentional blink (AB) is a biological effect, showing that for 200 to 500ms after paying attention to one visual target, it is difficult to notice another target that appears next, and attentional blink magnitude (ABM) is a indicating parameter to measure the degree of this effect. Researchers have shown that different categories of images can access the consciousness of human mind differently, and produce different ranges of ABM values. So in this paper, we compare two different types of images, categorized as animal and object, by predicting ABM values directly from image features extracted from convolutional neural network (CNN), and indirectly from functional magnetic resonance imaging (fMRI) data. First, for two sets of images, we separately extract their average features from layers of Alexnet, a classic model of CNN, then input the features into a trained linear regression model to predict ABM values, and we find higher-level instead of lower-level image features determine the categorical difference in AB effect, and mid-level image features predict ABM values more correctly than low-level and high-level image features. Then we employ fMRI data from different brain regions collected when the subjects viewed 50 test images to predict ABM values, and conclude that brain regions covering relatively broader areas, like LVC, HVC and VC, perform better than other smaller brain regions, which means AB effect is more related to synthetic impact of several visual brain regions than only one particular visual regions.