 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Model from Scratch
Dec 18, 2024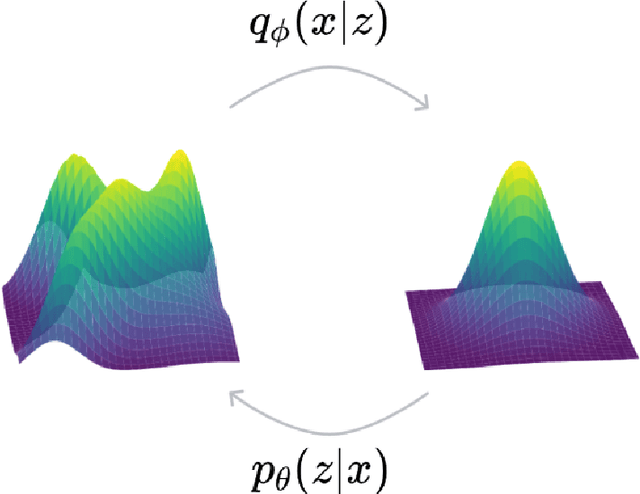
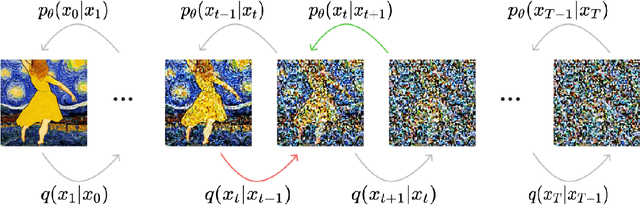
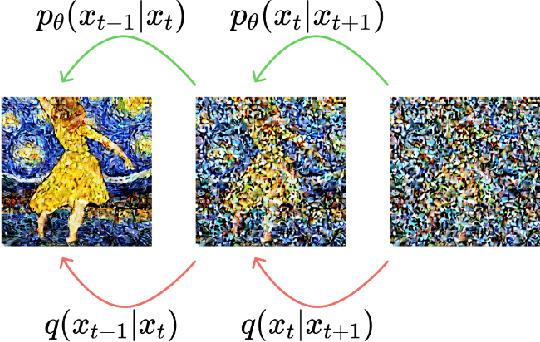
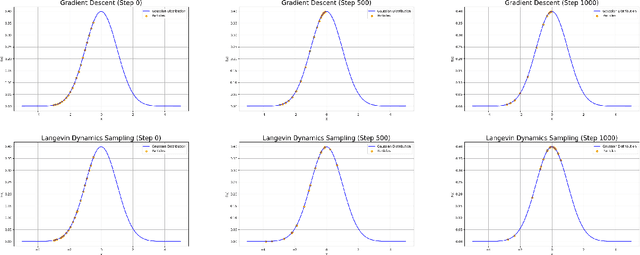
Diffusion generative models are currently the most popular generative models. However, their underlying modeling process is quite complex, and starting directly with the seminal paper Denoising Diffusion Probability Model (DDPM) can be challenging. This paper aims to assist readers in building a foundational understanding of generative models by tracing the evolution from VAEs to DDPM through detailed mathematical derivations and a problem-oriented analytical approach. It also explores the core ideas and improvement strategies of current mainstream methodologies, providing guidance for undergraduate and graduate students interested in learning about diffusion models.
Uni-Mol2: Exploring Molecular Pretraining Model at Scale
Jun 21, 2024



In recent years, pretraining models have made significant advancements in the fields of natural language processing (NLP), computer vision (CV), and life sciences. The significant advancements in NLP and CV are predominantly driven by the expansion of model parameters and data size, a phenomenon now recognized as the scaling laws. However, research exploring scaling law in molecular pretraining models remains unexplored. In this work, we present Uni-Mol2 , an innovative molecular pretraining model that leverages a two-track transformer to effectively integrate features at the atomic level, graph level, and geometry structure level. Along with this, we systematically investigate the scaling law within molecular pretraining models, characterizing the power-law correlations between validation loss and model size, dataset size, and computational resources. Consequently, we successfully scale Uni-Mol2 to 1.1 billion parameters through pretraining on 800 million conformations, making it the largest molecular pretraining model to date. Extensive experiments show consistent improvement in the downstream tasks as the model size grows. The Uni-Mol2 with 1.1B parameters also outperforms existing methods, achieving an average 27% improvement on the QM9 and 14% on COMPAS-1D dataset.